![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
The QNX Neutrino microkernel, procnto, implements the core POSIX features used in embedded realtime systems, along with the fundamental QNX Neutrino message-passing services. The POSIX features that aren't implemented in the microkernel (file and device I/O, for example) are provided by optional processes and shared libraries.
Successive QNX microkernels have seen a reduction in the code required to implement a given kernel call. The object definitions at the lowest layer in the kernel code have become more specific, allowing greater code reuse (such as folding various forms of POSIX signals, realtime signals, and QNX pulses into common data structures and code to manipulate those structures).
At its lowest level, the microkernel contains a few fundamental objects and the highly tuned routines that manipulate them. The OS is built from this foundation.
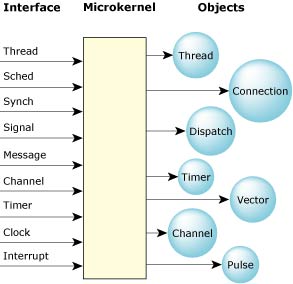
The QNX Neutrino microkernel.
Some developers have assumed that our microkernel is implemented entirely in assembly code for size or performance reasons. In fact, our implementation is coded primarily in C; size and performance goals are achieved through successively refined algorithms and data structures, rather than via assembly-level peep-hole optimizations.
Historically, the "application pressure" on QNX operating systems has been from both ends of the computing spectrum -- from memory-limited embedded systems all the way up to high-end SMP (symmetrical multiprocessing) machines with gigabytes of physical memory. Accordingly, the design goals for QNX Neutrino accommodate both seemingly exclusive sets of functionality. Pursuing these goals is intended to extend the reach of systems well beyond what other OS implementations could address.
Since QNX Neutrino implements the majority of the realtime and thread services directly in the microkernel, these services are available even without the presence of additional OS modules.
In addition, some of the profiles defined by POSIX suggest that these services be present without necessarily requiring a process model. In order to accommodate this, the OS provides direct support for threads, but relies on its process manager portion to extend this functionality to processes containing multiple threads.
Note that many realtime executives and kernels provide only a nonmemory-protected threaded model, with no process model and/or protected memory model at all. Without a process model, full POSIX compliance cannot be achieved.
The QNX Neutrino microkernel has kernel calls to support the following:
The entire OS is built upon these calls. The OS is fully preemptible, even while passing messages between processes; it resumes the message pass where it left off before preemption.
The minimal complexity of the microkernel helps place an upper bound on the longest nonpreemptible code path through the kernel, while the small code size makes addressing complex multiprocessor issues a tractable problem. Services were chosen for inclusion in the microkernel on the basis of having a short execution path. Operations requiring significant work (e.g. process loading) were assigned to external processes/threads, where the effort to enter the context of that thread would be insignificant compared to the work done within the thread to service the request.
Rigorous application of this rule to dividing the functionality between the kernel and external processes destroys the myth that a microkernel OS must incur higher runtime overhead than a monolithic kernel OS. Given the work done between context switches (implicit in a message pass), and the very quick context-switch times that result from the simplified kernel, the time spent performing context switches becomes "lost in the noise" of the work done to service the requests communicated by the message passing between the processes that make up the OS.
The following diagram shows the preemption details for the non-SMP kernel (x86 implementation).
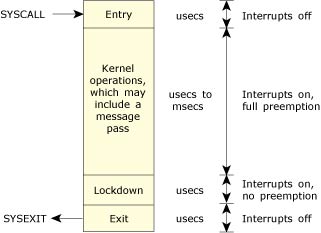
QNX Neutrino preemption details.
Interrupts are disabled, or preemption is held off, for only very brief intervals (typically in the order of hundreds of nanoseconds).
When building an application (realtime, embedded, graphical, or otherwise), the developer may want several algorithms within the application to execute concurrently. This concurrency is achieved by using the POSIX thread model, which defines a process as containing one or more threads of execution.
A thread can be thought of as the minimum "unit of execution," the unit of scheduling and execution in the microkernel. A process, on the other hand, can be thought of as a "container" for threads, defining the "address space" within which threads will execute. A process will always contain at least one thread.
Depending on the nature of the application, threads might execute independently with no need to communicate between the algorithms (unlikely), or they may need to be tightly coupled, with high-bandwidth communications and tight synchronization. To assist in this communication and synchronization, QNX Neutrino provides a rich variety of IPC and synchronization services.
The following pthread_* (POSIX Threads) library calls don't involve any microkernel thread calls:
The following table lists the POSIX thread calls that have a corresponding microkernel thread call, allowing you to choose either interface:
| POSIX call | Microkernel call | Description |
|---|---|---|
| pthread_create() | ThreadCreate() | Create a new thread of execution. |
| pthread_exit() | ThreadDestroy() | Destroy a thread. |
| pthread_detach() | ThreadDetach() | Detach a thread so it doesn't need to be joined. |
| pthread_join() | ThreadJoin() | Join a thread waiting for its exit status. |
| pthread_cancel() | ThreadCancel() | Cancel a thread at the next cancellation point. |
| N/A | ThreadCtl() | Change a thread's Neutrino-specific thread characteristics. |
| pthread_mutex_init() | SyncTypeCreate() | Create a mutex. |
| pthread_mutex_destroy() | SyncDestroy() | Destroy a mutex. |
| pthread_mutex_lock() | SyncMutexLock() | Lock a mutex. |
| pthread_mutex_trylock() | SyncMutexLock() | Conditionally lock a mutex. |
| pthread_mutex_unlock() | SyncMutexUnlock() | Unlock a mutex. |
| pthread_cond_init() | SyncTypeCreate() | Create a condition variable. |
| pthread_cond_destroy() | SyncDestroy() | Destroy a condition variable. |
| pthread_cond_wait() | SyncCondvarWait() | Wait on a condition variable. |
| pthread_cond_signal() | SyncCondvarSignal() | Signal a condition variable. |
| pthread_cond_broadcast() | SyncCondvarSignal() | Broadcast a condition variable. |
| pthread_getschedparam() | SchedGet() | Get scheduling parameters and policy of thread. |
| pthread_setschedparam() | SchedSet() | Set scheduling parameters and policy of thread. |
| pthread_sigmask() | SignalProcmask() | Examine or set a thread's signal mask. |
| pthread_kill() | SignalKill() | Send a signal to a specific thread. |
The OS can be configured to provide a mix of threads and processes (as defined by POSIX). Each process is MMU-protected from each other, and each process may contain one or more threads that share the process's address space.
The environment you choose affects not only the concurrency capabilities of the application, but also the IPC and synchronization services the application might make use of.
 |
Even though the common term "IPC" refers to communicating processes, we use it here to describe the communication between threads, whether they're within the same process or separate processes. |
Although threads within a process share everything within the process's address space, each thread still has some "private" data. In some cases, this private data is protected within the kernel (e.g. the tid or thread ID), while other private data resides unprotected in the process's address space (e.g. each thread has a stack for its own use). Some of the more noteworthy thread-private resources are:
Thread-specific data, implemented in the pthread library and stored in the TLS, provides a mechanism for associating a process global integer key with a unique per-thread data value. To use thread-specific data, you first create a new key and then bind a unique data value to the key (per thread). The data value may, for example, be an integer or a pointer to a dynamically allocated data structure. Subsequently, the key can return the bound data value per thread.
A typical application of thread-specific data is for a thread-safe function that needs to maintain a context for each calling thread.
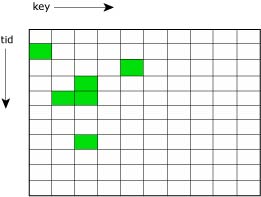
Sparse matrix (tid,key) to value mapping.
You use the following functions to create and manipulate this data:
| Function | Description |
|---|---|
| pthread_key_create() | Create a data key with destructor function |
| pthread_key_delete() | Destroy a data key |
| pthread_setspecific() | Bind a data value to a data key |
| pthread_getspecific() | Return the data value bound to a data key |
The number of threads within a process can vary widely, with threads being created and destroyed dynamically. Thread creation (pthread_create()) involves allocating and initializing the necessary resources within the process's address space (e.g. thread stack) and starting the execution of the thread at some function in the address space.
Thread termination (pthread_exit(), pthread_cancel()) involves stopping the thread and reclaiming the thread's resources. As a thread executes, its state can generally be described as either "ready" or "blocked." More specifically, it can be one of the following:
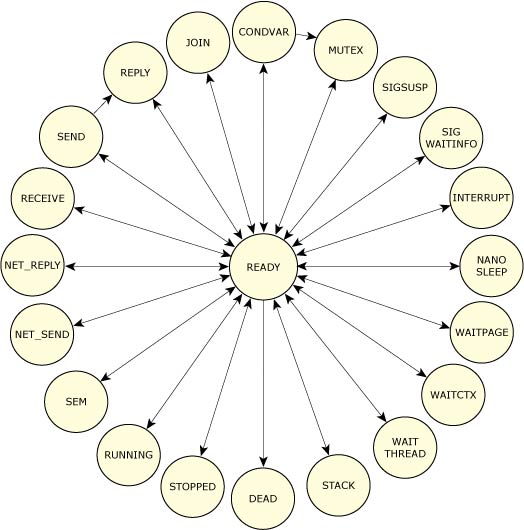
Possible thread states.
The execution of a running thread is temporarily suspended whenever the microkernel is entered as the result of a kernel call, exception, or hardware interrupt. A scheduling decision is made whenever the execution state of any thread changes -- it doesn't matter which processes the threads might reside within. Threads are scheduled globally across all processes.
Normally, the execution of the suspended thread will resume, but the scheduler will perform a context switch from one thread to another whenever the running thread:
The running thread blocks when it must wait for some event to occur (response to an IPC request, wait on a mutex, etc.). The blocked thread is removed from the ready queue and the highest-priority ready thread is then run. When the blocked thread is subsequently unblocked, it is placed on the end of the ready queue for that priority level.
The running thread is preempted when a higher-priority thread is placed on the ready queue (it becomes READY, as the result of its block condition being resolved). The preempted thread remains at the beginning of the ready queue for that priority and the higher-priority thread runs.
The running thread voluntarily yields the processor (sched_yield()) and is placed on the end of the ready queue for that priority. The highest-priority thread then runs (which may still be the thread that just yielded).
Every thread is assigned a priority. The scheduler selects the next thread to run by looking at the priority assigned to every thread that is READY (i.e. capable of using the CPU). The thread with the highest priority is selected to run.
The following diagram shows the ready queue for six threads (A-F) that are READY. All other threads (G-Z) are BLOCKED. Thread A is currently running. Thread A, B, and C are at the highest priority, so they'll share the processor based on the running thread's scheduling algorithm.
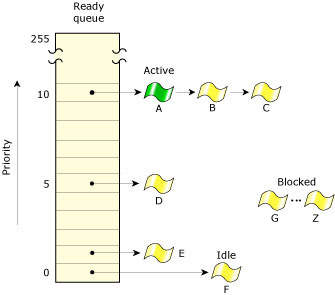
The ready queue.
The OS supports a total of 256 scheduling priority levels. A non-root thread can set its priority to a level from 1 to 63 (the highest priority), independent of the scheduling policy. Only root threads (i.e. those whose effective uid is 0) are allowed to set priorities above 63. The special idle thread (in the process manager) has priority 0 and is always ready to run. A thread inherits the priority of its parent thread by default.
You can change the allowed priority range for non-root processes with the procnto -P option:
procnto -P priority
Here's a summary of the ranges:
| Priority level | Owner |
|---|---|
| 0 | Idle thread |
| 1 through priority - 1 | Non-root or root |
| priority through 255 | root |
Note that in order to prevent priority inversion, the kernel may temporarily boost a thread's priority.
The threads on the ready queue are ordered by priority. The ready queue is actually implemented as 256 separate queues, one for each priority. Most of the time, threads are queued in FIFO order in the queue of their priority. (The exception is a server thread that's coming out of a RECEIVE-blocked state with a message from a client; the server thread is inserted at the head of the queue for that priority -- that is, the order is LIFO, not FIFO.) The first thread in the highest-priority queue is selected to run.
To meet the needs of various applications, QNX Neutrino provides these scheduling algorithms:
Each thread in the system may run using any method. The methods are effective on a per-thread basis, not on a global basis for all threads and processes on a node.
Remember that the FIFO and round-robin scheduling algorithms apply only when two or more threads that share the same priority are READY (i.e. the threads are directly competing with each other). The sporadic method, however, employs a "budget" for a thread's execution. In all cases, if a higher-priority thread becomes READY, it immediately preempts all lower-priority threads.
In the following diagram, three threads of equal priority are READY. If Thread A blocks, Thread B will run.
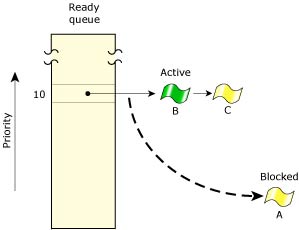
Thread A blocks, Thread B runs.
Although a thread inherits its scheduling algorithm from its parent process, the thread can request to change the algorithm applied by the kernel.
In FIFO scheduling, a thread selected to run continues executing until it:
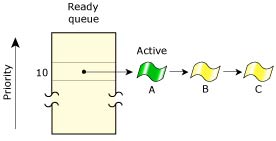
FIFO scheduling.
In round-robin scheduling, a thread selected to run continues executing until it:
As the following diagram shows, Thread A ran until it consumed its timeslice; the next READY thread (Thread B) now runs:
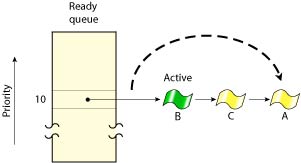
Round-robin scheduling.
A timeslice is the unit of time assigned to every process. Once it consumes its timeslice, a thread is preempted and the next READY thread at the same priority level is given control. A timeslice is 4 * the clock period. (For more information, see the entry for ClockPeriod() in the Library Reference.)
|
Apart from time slicing, round-robin scheduling is identical to FIFO scheduling. |
The sporadic scheduling algorithm is generally used to provide a capped limit on the execution time of a thread within a given period of time. This behavior is essential when Rate Monotonic Analysis (RMA) is being performed on a system that services both periodic and aperiodic events. Essentially, this algorithm allows a thread to service aperiodic events without jeopardizing the hard deadlines of other threads or processes in the system.
As in FIFO scheduling, a thread using sporadic scheduling continues executing until it blocks or is preempted by a higher-priority thread. And as in adaptive scheduling, a thread using sporadic scheduling will drop in priority, but with sporadic scheduling you have much more precise control over the thread's behavior.
Under sporadic scheduling, a thread's priority can oscillate dynamically between a foreground or normal priority and a background or low priority. Using the following parameters, you can control the conditions of this sporadic shift:
|
In a poorly configured system, a thread's execution budget may become eroded because of too much blocking -- i.e. it won't receive enough replenishments. |
As the following diagram shows, the sporadic scheduling policy establishes a thread's initial execution budget (C), which is consumed by the thread as it runs and is replenished periodically (for the amount T). When a thread blocks, the amount of the execution budget that's been consumed (R) is arranged to be replenished at some later time (e.g. at 40 msec) after the thread first became ready to run.
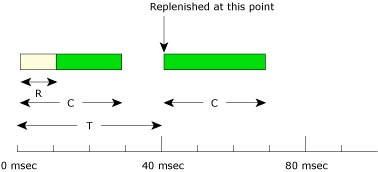
A thread's budget is replenished periodically.
At its normal priority N, a thread will execute for the amount of time defined by its initial execution budget C. As soon as this time is exhausted, the priority of the thread will drop to its low priority L until the replenishment operation occurs.
Assume, for example, a system where the thread never blocks or is never preempted:
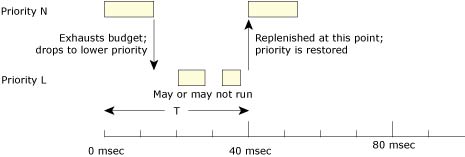
Thread drops in priority until its budget is replenished.
Here the thread will drop to its low-priority (background) level, where it may or may not get a chance to run depending on the priority of other threads in the system.
Once the replenishment occurs, the thread's priority is raised to its original level. This guarantees that within a properly configured system, the thread will be given the opportunity every period T to run for a maximum execution time C. This ensures that a thread running at priority N will consume only C/T percent of the system's resources.
When a thread blocks multiple times, then several replenishment operations may be started and occur at different times. This could mean that the thread's execution budget will total C within a period T; however, the execution budget may not be contiguous during that period.
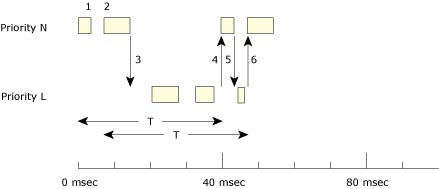
Thread oscillates between high and low priority.
In the diagram above, the thread has a budget (C) of 10 msec to be consumed within each 40-msec replenishment period (T).
And so on. The thread will continue to oscillate between its two priority levels, servicing aperiodic events in your system in a controlled, predictable manner.
A thread's priority can vary during its execution, either from direct manipulation by the thread itself or from the kernel adjusting the thread's priority as it receives a message from a higher-priority thread.
In addition to priority, you can also select the scheduling algorithm that the kernel will use for the thread. Here are the POSIX calls for performing these manipulations, along with the microkernel calls used by these library routines:
| POSIX call | Microkernel call | Description |
|---|---|---|
| sched_getparam() | SchedGet() | Get scheduling priority |
| sched_setparam() | SchedSet() | Set scheduling priority |
| sched_getscheduler() | SchedGet() | Get scheduling policy |
| sched_setscheduler() | SchedSet() | Set scheduling policy |
Since all the threads in a process have unhindered access to the shared data space, wouldn't this execution model "trivially" solve all of our IPC problems? Can't we just communicate the data through shared memory and dispense with any other execution models and IPC mechanisms?
If only it were that simple!
One issue is that the access of individual threads to common data must be synchronized. Having one thread read inconsistent data because another thread is part way through modifying it is a recipe for disaster. For example, if one thread is updating a linked list, no other threads can be allowed to traverse or modify the list until the first thread has finished. A code passage that must execute "serially" (i.e. by only one thread at a time) in this manner is termed a "critical section." The program would fail (intermittently, depending on how frequently a "collision" occurred) with irreparably damaged links unless some synchronization mechanism ensured serial access.
Mutexes, semaphores, and condvars are examples of synchronization tools that can be used to address this problem. These tools are described later in this section.
Although synchronization services can be used to allow threads to cooperate, shared memory per se can't address a number of IPC issues. For example, although threads can communicate through the common data space, this works only if all the threads communicating are within a single process. What if our application needs to communicate a query to a database server? We need to pass the details of our query to the database server, but the thread we need to communicate with lies within a database server process and the address space of that server isn't addressable to us.
The OS takes care of the network-distributed IPC issue because the one interface -- message passing -- operates in both the local and network-remote cases, and can be used to access all OS services. Since messages can be exactly sized, and since most messages tend to be quite tiny (e.g. the error status on a write request, or a tiny read request), the data moved around the network can be far less with message passing than with network-distributed shared memory, which would tend to copy 4K pages around.
Although threads are very appropriate for some system designs, it's important to respect the Pandora's box of complexities their use unleashes. In some ways, it's ironic that while MMU-protected multitasking has become common, computing fashion has made popular the use of multiple threads in an unprotected address space. This not only makes debugging difficult, but also hampers the generation of reliable code.
Threads were initially introduced to UNIX systems as a "light-weight" concurrency mechanism to address the problem of slow context switches between "heavy weight" processes. Although this is a worthwhile goal, an obvious question arises: Why are process-to-process context switches slow in the first place?
Architecturally, the OS addresses the context-switch performance issue first. In fact, threads and processes provide nearly identical context-switch performance numbers. QNX Neutrino's process-switch times are faster than UNIX thread-switch times. As a result, QNX Neutrino threads don't need to be used to solve the IPC performance problem; instead, they're a tool for achieving greater concurrency within application and server processes.
Without resorting to threads, fast process-to-process context switching makes it reasonable to structure an application as a team of cooperating processes sharing an explicitly allocated shared-memory region. An application thus exposes itself to bugs in the cooperating processes only so far as the effects of those bugs on the contents of the shared-memory region. The private memory of the process is still protected from the other processes. In the purely threaded model, the private data of all threads (including their stacks) is openly accessible, vulnerable to stray pointer errors in any thread in the process.
Nevertheless, threads can also provide concurrency advantages that a pure process model cannot address. For example, a filesystem server process that executes requests on behalf of many clients (where each request takes significant time to complete), definitely benefits from having multiple threads of execution. If one client process requests a block from disk, while another client requests a block already in cache, the filesystem process can utilize a pool of threads to concurrently service client requests, rather than remain "busy" until the disk block is read for the first request.
As requests arrive, each thread is able to respond directly from the buffer cache or to block and wait for disk I/O without increasing the response latency seen by other client processes. The filesystem server can "precreate" a team of threads, ready to respond in turn to client requests as they arrive. Although this complicates the architecture of the filesystem manager, the gains in concurrency are significant.
QNX Neutrino provides the POSIX-standard thread-level synchronization primitives, some of which are useful even between threads in different processes. The synchronization services include at least the following:
| Synchronization service | Supported between processes | Supported across a QNX LAN |
|---|---|---|
| Mutexes | Yes | No |
| Condvars | Yes | No |
| Barriers | No | No |
| Sleepon locks | No | No |
| Reader/writer locks | Yes | No |
| Semaphores | Yes | Yes (named only) |
| FIFO scheduling | Yes | No |
| Send/Receive/Reply | Yes | Yes |
| Atomic operations | Yes | No |
|
The above synchronization primitives are implemented directly by
the kernel, except for:
|
Mutual exclusion locks, or mutexes, are the simplest of the synchronization services. A mutex is used to ensure exclusive access to data shared between threads. It is typically acquired (pthread_mutex_lock()) and released (pthread_mutex_unlock()) around the code that accesses the shared data (usually a critical section).
Only one thread may have the mutex locked at any given time. Threads attempting to lock an already locked mutex will block until the thread is later unlocked. When the thread unlocks the mutex, the highest-priority thread waiting to lock the mutex will unblock and become the new owner of the mutex. In this way, threads will sequence through a critical region in priority-order.
On most processors, acquisition of a mutex doesn't require entry to the kernel for a free mutex. What allows this is the use of the compare-and-swap opcode on x86 processors and the load/store conditional opcodes on most RISC processors.
Entry to the kernel is done at acquisition time only if the mutex is already held so that the thread can go on a blocked list; kernel entry is done on exit if other threads are waiting to be unblocked on that mutex. This allows acquisition and release of an uncontested critical section or resource to be very quick, incurring work by the OS only to resolve contention.
A nonblocking lock function (pthread_mutex_trylock()) can be used to test whether the mutex is currently locked or not. For best performance, the execution time of the critical section should be small and of bounded duration. A condvar should be used if the thread may block within the critical section.
If a thread with a higher priority than the mutex owner attempts to lock a mutex, then the effective priority of the current owner will be increased to that of the higher-priority blocked thread waiting for the mutex. The owner will return to its real priority when it unlocks the mutex. This scheme not only ensures that the higher-priority thread will be blocked waiting for the mutex for the shortest possible time, but also solves the classic priority-inversion problem.
The attributes of the mutex can also be modified (using pthread_mutexattr_setrecursive()) to allow a mutex to be recursively locked by the same thread. This can be useful to allow a thread to call a routine that might attempt to lock a mutex that the thread already happens to have locked.
|
Recursive mutexes are non-POSIX services -- they don't work with condvars. |
A condition variable, or condvar, is used to block a thread within a critical section until some condition is satisfied. The condition can be arbitrarily complex and is independent of the condvar. However, the condvar must always be used with a mutex lock in order to implement a monitor.
A condvar supports three operations:
|
Note that there's no connection between a condvar signal and a POSIX signal. |
Here's a typical example of how a condvar can be used:
pthread_mutex_lock( &m );
. . .
while (!arbitrary_condition) {
pthread_cond_wait( &cv, &m );
}
. . .
pthread_mutex_unlock( &m );
In this code sample, the mutex is acquired before the condition is tested. This ensures that only this thread has access to the arbitrary condition being examined. While the condition is true, the code sample will block on the wait call until some other thread performs a signal or broadcast on the condvar.
The while loop is required for two reasons. First of all, POSIX cannot guarantee that false wakeups will not occur (e.g. multiprocessor systems). Second, when another thread has made a modification to the condition, we need to retest to ensure that the modification matches our criteria. The associated mutex is unlocked atomically by pthread_cond_wait() when the waiting thread is blocked to allow another thread to enter the critical section.
A thread that performs a signal will unblock the highest-priority thread queued on the condvar, while a broadcast will unblock all threads queued on the condvar. The associated mutex is locked atomically by the highest-priority unblocked thread; the thread must then unlock the mutex after proceeding through the critical section.
A version of the condvar wait operation allows a timeout to be specified (pthread_cond_timedwait()). The waiting thread can then be unblocked when the timeout expires.
A barrier is a synchronization mechanism that lets you "corral" several cooperating threads (e.g. in a matrix computation), forcing them to wait at a specific point until all have finished before any one thread can continue.
Unlike the pthread_join() function, where you'd wait for the threads to terminate, in the case of a barrier you're waiting for the threads to rendezvous at a certain point. When the specified number of threads arrive at the barrier, we unblock all of them so they can continue to run.
You first create a barrier with pthread_barrier_init():
#include <pthread.h>
int
pthread_barrier_init (pthread_barrier_t *barrier,
const pthread_barrierattr_t *attr,
unsigned int count);
This creates a barrier object at the passed address (a pointer to the barrier object is in barrier), with the attributes as specified by attr. The count member holds the number of threads that must call pthread_barrier_wait().
Once the barrier is created, each thread will call pthread_barrier_wait() to indicate that it has completed:
#include <pthread.h> int pthread_barrier_wait (pthread_barrier_t *barrier);
When a thread calls pthread_barrier_wait(), it blocks until the number of threads specified initially in the pthread_barrier_init() function have called pthread_barrier_wait() (and blocked also). When the correct number of threads have called pthread_barrier_wait(), all those threads will unblock at the same time.
Here's an example:
/*
* barrier1.c
*/
#include <stdio.h>
#include <time.h>
#include <pthread.h>
#include <sys/neutrino.h>
pthread_barrier_t barrier; // barrier synchronization object
main () // ignore arguments
{
time_t now;
// create a barrier object with a count of 3
pthread_barrier_init (&barrier, NULL, 3);
// start up two threads, thread1 and thread2
pthread_create (NULL, NULL, thread1, NULL);
pthread_create (NULL, NULL, thread2, NULL);
// at this point, thread1 and thread2 are running
// now wait for completion
time (&now);
printf ("main() waiting for barrier at %s", ctime (&now));
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in main() done at %s", ctime (&now));
}
void *
thread1 (void *not_used)
{
time_t now;
time (&now);
printf ("thread1 starting at %s", ctime (&now));
// do the computation
// let's just do a sleep here...
sleep (20);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread1() done at %s", ctime (&now));
}
void *
thread2 (void *not_used)
{
time_t now;
time (&now);
printf ("thread2 starting at %s", ctime (&now));
// do the computation
// let's just do a sleep here...
sleep (40);
pthread_barrier_wait (&barrier);
// after this point, all three threads have completed.
time (&now);
printf ("barrier in thread2() done at %s", ctime (&now));
}
The main thread created the barrier object and initialized it with a count of the total number of threads that must be synchronized to the barrier before the threads may carry on. In the example above, we used a count of 3: one for the main() thread, one for thread1(), and one for thread2().
Then we start thread1() and thread2(). To simplify this example, we have the threads sleep to cause a delay, as if computations were occurring. To synchronize, the main thread simply blocks itself on the barrier, knowing that the barrier will unblock only after the two worker threads have joined it as well.
In this release, the following barrier functions are included:
| Function | Description |
|---|---|
| pthread_barrierattr_getpshared() | Get the value of a barrier's process-shared attribute |
| pthread_barrierattr_destroy() | Destroy a barrier's attributes object |
| pthread_barrierattr_init() | Initialize a barrier's attributes object |
| pthread_barrierattr_setpshared() | Set the value of a barrier's process-shared attribute |
| pthread_barrier_destroy() | Destroy a barrier |
| pthread_barrier_init() | Initialize a barrier |
| pthread_barrier_wait() | Synchronize participating threads at the barrier |
Sleepon locks are very similar to condvars, with a few subtle differences. Like condvars, sleepon locks (pthread_sleepon_lock()) can be used to block until a condition becomes true (like a memory location changing value). But unlike condvars, which must be allocated for each condition to be checked, sleepon locks multiplex their functionality over a single mutex and dynamically allocated condvar, regardless of the number of conditions being checked. The maximum number of condvars ends up being equal to the maximum number of blocked threads. These locks are patterned after the sleepon locks commonly used within the UNIX kernel.
More formally known as "Multiple readers, single writer locks," these locks are used when the access pattern for a data structure consists of many threads reading the data, and (at most) one thread writing the data. These locks are more expensive than mutexes, but can be useful for this data access pattern.
This lock works by allowing all the threads that request a read-access lock (pthread_rwlock_rdlock()) to succeed in their request. But when a thread wishing to write asks for the lock (pthread_rwlock_wrlock()), the request is denied until all the current reading threads release their reading locks (pthread_rwlock_unlock()).
Multiple writing threads can queue (in priority order) waiting for their chance to write the protected data structure, and all the blocked writer-threads will get to run before reading threads are allowed access again. The priorities of the reading threads are not considered.
There are also calls (pthread_rwlock_tryrdlock() and pthread_rwlock_trywrlock()) to allow a thread to test the attempt to achieve the requested lock, without blocking. These calls return with a successful lock or a status indicating that the lock couldn't be granted immediately.
Reader/writer locks aren't implemented directly within the kernel, but are instead built from the mutex and condvar services provided by the kernel.
Semaphores are another common form of synchronization that allows threads to "post" (sem_post()) and "wait" (sem_wait()) on a semaphore to control when threads wake or sleep. The post operation increments the semaphore; the wait operation decrements it.
If you wait on a semaphore that is positive, you will not block. Waiting on a nonpositive semaphore will block until some other thread executes a post. It is valid to post one or more times before a wait. This use will allow one or more threads to execute the wait without blocking.
A significant difference between semaphores and other synchronization primitives is that semaphores are "async safe" and can be manipulated by signal handlers. If the desired effect is to have a signal handler wake a thread, semaphores are the right choice.
|
Note that in general, mutexes are much faster than semaphores, which always require a kernel entry. |
Another useful property of semaphores is that they were defined to operate between processes. Although our mutexes work between processes, the POSIX thread standard considers this an optional capability and as such may not be portable across systems. For synchronization between threads in a single process, mutexes will be more efficient than semaphores.
As a useful variation, a named semaphore service is also available. It uses a resource manager and as such allows semaphores to be used between processes on different machines connected by a network.
|
Note that named semaphores are slower than the unnamed variety. |
Since semaphores, like condition variables, can legally return a nonzero value because of a false wakeup, correct usage requires a loop:
while (sem_wait(&s) && (errno == EINTR)) { do_nothing(); }
do_critical_region(); /* Semaphore was decremented */
By selecting the POSIX FIFO scheduling algorithm, we can guarantee that no two threads of the same priority execute the critical section concurrently on a non-SMP system. The FIFO scheduling algorithm dictates that all FIFO-scheduled threads in the system at the same priority will run, when scheduled, until they voluntarily release the processor to another thread.
This "release" can also occur when the thread blocks as part of requesting the service of another process, or when a signal occurs. The critical region must therefore be carefully coded and documented so that later maintenance of the code doesn't violate this condition.
In addition, higher-priority threads in that (or any other) process could still preempt these FIFO-scheduled threads. So, all the threads that could "collide" within the critical section must be FIFO-scheduled at the same priority. Having enforced this condition, the threads can then casually access this shared memory without having to first make explicit synchronization calls.
|
This exclusive-access relationship doesn't apply in multiprocessor systems, since each CPU could run a thread simultaneously through the region that would otherwise be serially scheduled on a single-processor machine. |
Our Send/Receive/Reply message-passing IPC services (described later) implement an implicit synchronization by their blocking nature. These IPC services can, in many instances, render other synchronization services unnecessary. They are also the only synchronization and IPC primitives (other than named semaphores, which are built on top of messaging) that can be used across the network.
In some cases, you may want to perform a short operation (such as incrementing a variable) with the guarantee that the operation will perform atomically -- i.e. the operation won't be preempted by another thread or ISR (Interrupt Service Routine).
Under QNX Neutrino, we provide atomic operations for:
These atomic operations are available by including the C header file <atomic.h>.
Although you can use these atomic operations just about anywhere, you'll find them particularly useful in these two cases:
Since an ISR can preempt a thread at any given point, the only way that the thread would be able to protect itself would be to disable interrupts. Since you should avoid disabling interrupts in a realtime system, we recommend that you use the atomic operations provided with QNX Neutrino.
On an SMP system, multiple threads can and do run concurrently. Again, we run into the same situation as with interrupts above -- you should use the atomic operations where applicable to eliminate the need to disable and reenable interrupts.
The following table lists the various microkernel calls and the higher-level POSIX calls constructed from them:
| Microkernel call | POSIX call | Description |
|---|---|---|
| SyncTypeCreate() | pthread_mutex_init(), pthread_cond_init(), sem_init() | Create object for mutex, condvars, and semaphore. |
| SyncDestroy() | pthread_mutex_destroy(), pthread_cond_destroy(), sem_destroy() | Destroy synchronization object. |
| SyncCondvarWait() | pthread_cond_wait(), pthread_cond_timedwait() | Block on a condvar. |
| SyncCondvarSignal() | pthread_cond_broadcast(), pthread_cond_signal() | Wake up condvar-blocked threads. |
| SyncMutexLock() | pthread_mutex_lock(), pthread_mutex_trylock() | Lock a mutex. |
| SyncMutexUnlock() | pthread_mutex_unlock() | Unlock a mutex. |
| SyncSemPost() | sem_post() | Post a semaphore. |
| SyncSemWait() | sem_wait(), sem_trywait() | Wait on a semaphore. |
IPC plays a fundamental role in the transformation of QNX Neutrino from an embedded realtime kernel into a full-scale POSIX operating system. As various service-providing processes are added to the microkernel, IPC is the "glue" that connects those components into a cohesive whole.
Although message passing is the primary form of IPC in QNX Neutrino, several other forms are available as well. Unless otherwise noted, those other forms of IPC are built over our native message passing. The strategy is to create a simple, robust IPC service that can be tuned for performance through a simplified code path in the microkernel; more "feature cluttered" IPC services can then be implemented from these.
Benchmarks comparing higher-level IPC services (like pipes and FIFOs implemented over our messaging) with their monolithic kernel counterparts show comparable performance.
QNX Neutrino offers at least the following forms of IPC:
| Service: | Implemented in: |
|---|---|
| Message-passing | Kernel |
| Signals | Kernel |
| POSIX message queues | External process |
| Shared memory | Process manager |
| Pipes | External process |
| FIFOs | External process |
The designer can select these services on the basis of bandwidth requirements, the need for queuing, network transparency, etc. The tradeoff can be complex, but the flexibility is useful.
As part of the engineering effort that went into defining the QNX Neutrino microkernel, the focus on message passing as the fundamental IPC primitive was deliberate. As a form of IPC, message passing (as implemented in MsgSend(), MsgReceive(), and MsgReply()), is synchronous and copies data. Let's explore these two attributes in more detail.
A thread that does a MsgSend() to another thread (which could be within another process) will be blocked until the target thread does a MsgReceive(), processes the message, and executes a MsgReply(). If a thread executes a MsgReceive() without a previously sent message pending, it will block until another thread executes a MsgSend().
In Neutrino, a server thread typically loops, waiting to receive a message from a client thread. As described earlier, a thread -- whether a server or a client -- is in the READY state if it can use the CPU. It might not actually be getting any CPU time because of its and other threads' priority and scheduling algorithm, but the thread isn't blocked.
Let's look first at the client thread:
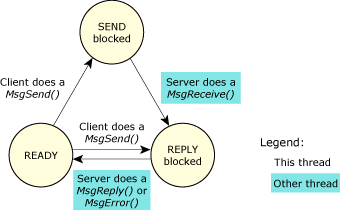
Changes of state for a client thread in a send-receive-reply transaction.
Next, let's consider the server thread:
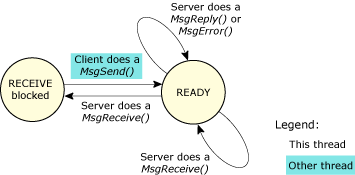
Changes of state for a server thread in a send-receive-reply transaction.
This inherent blocking synchronizes the execution of the sending thread, since the act of requesting that the data be sent also causes the sending thread to be blocked and the receiving thread to be scheduled for execution. This happens without requiring explicit work by the kernel to determine which thread to run next (as would be the case with most other forms of IPC). Execution and data move directly from one context to another.
Data-queuing capabilities are omitted from these messaging primitives because queueing could be implemented when needed within the receiving thread. The sending thread is often prepared to wait for a response; queueing is unnecessary overhead and complexity (i.e. it slows down the nonqueued case). As a result, the sending thread doesn't need to make a separate, explicit blocking call to wait for a response (as it would if some other IPC form had been used).
While the send and receive operations are blocking and synchronous, MsgReply() (or MsgError()) doesn't block. Since the client thread is already blocked waiting for the reply, no additional synchronization is required, so a blocking MsgReply() isn't needed. This allows a server to reply to a client and continue processing while the kernel and/or networking code asynchronously passes the reply data to the sending thread and marks it ready for execution. Since most servers will tend to do some processing to prepare to receive the next request (at which point they block again), this works out well.
|
Note that in a network, a reply may not complete as "immediately" as in a local message pass. For more information on network message passing, see the chapter on Qnet networking in this book. |
The MsgReply() function is used to return a status and zero or more bytes to the client. MsgError(), on the other hand, is used to return only a status to the client. Both functions will unblock the client from its MsgSend().
Since our messaging services copy a message directly from the address space of one thread to another without intermediate buffering, the message-delivery performance approaches the memory bandwidth of the underlying hardware. The kernel attaches no special meaning to the content of a message -- the data in a message has meaning only as mutually defined by sender and receiver. However, "well-defined" message types are also provided so that user-written processes or threads can augment or substitute for system-supplied services.
The messaging primitives support multipart transfers, so that a message delivered from the address space of one thread to another needn't pre-exist in a single, contiguous buffer. Instead, both the sending and receiving threads can specify a vector table that indicates where the sending and receiving message fragments reside in memory. Note that the size of the various parts can be different for the sender and receiver.
Multipart transfers allow messages that have a header block separate from the data block to be sent without performance-consuming copying of the data to create a contiguous message. In addition, if the underlying data structure is a ring buffer, specifying a three-part message will allow a header and two disjoint ranges within the ring buffer to be sent as a single atomic message. A hardware equivalent of this concept would be that of a scatter/gather DMA facility.
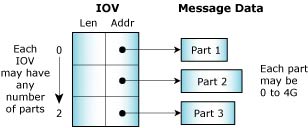
A multipart transfer.
The multipart transfers are also used extensively by filesystems. On a read, the data is copied directly from the filesystem cache into the application using a message with n parts for the data. Each part points into the cache and compensates for the fact that cache blocks aren't contiguous in memory with a read starting or ending within a block.
For example, with a cache block size of 512 bytes, a read of 1454 bytes can be satisfied with a 5-part message:
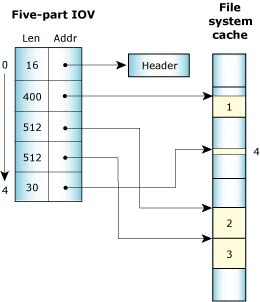
Scatter/gather of a read of 1454 bytes.
Since message data is explicitly copied between address spaces (rather than by doing page table manipulations), messages can be easily allocated on the stack instead of from a special pool of page-aligned memory for MMU "page flipping." As a result, many of the library routines that implement the API between client and server processes can be trivially expressed, without elaborate IPC-specific memory allocation calls.
For example, the code used by a client thread to request that the filesystem manager execute lseek on its behalf is implemented as follows:
#include <unistd.h>
#include <errno.h>
#include <sys/iomsg.h>
off64_t lseek64(int fd, off64_t offset, int whence) {
io_lseek_t msg;
off64_t off;
msg.i.type = _IO_LSEEK;
msg.i.combine_len = sizeof msg.i;
msg.i.offset = offset;
msg.i.whence = whence;
msg.i.zero = 0;
if(MsgSend(fd, &msg.i, sizeof msg.i, &off, sizeof off) == -1) {
return -1;
}
return off;
}
off64_t tell64(int fd) {
return lseek64(fd, 0, SEEK_CUR);
}
off_t lseek(int fd, off_t offset, int whence) {
return lseek64(fd, offset, whence);
}
off_t tell(int fd) {
return lseek64(fd, 0, SEEK_CUR);
}
This code essentially builds a message structure on the stack, populates it with various constants and passed parameters from the calling thread, and sends it to the filesystem manager associated with fd. The reply indicates the success or failure of the operation.
|
This implementation doesn't prevent the kernel from detecting large message transfers and choosing to implement "page flipping" for those cases. Since most messages passed are quite tiny, copying messages is often faster than manipulating MMU page tables. For bulk data transfer, shared memory between processes (with message-passing or the other synchronization primitives for notification) is also a viable option. |
For simple single-part messages, the OS provides functions that take a pointer directly to a buffer without the need for an IOV (input/output vector). In this case, the number of parts is replaced by the size of the message directly pointed to. In the case of the message send primitive -- which takes a send and a reply buffer -- this introduces four variations:
| Function | Send message | Reply message |
|---|---|---|
| MsgSend() | Simple | Simple |
| MsgSendsv() | Simple | IOV |
| MsgSendvs() | IOV | Simple |
| MsgSendv() | IOV | IOV |
The other messaging primitives that take a direct message simply drop the trailing "v" in their names:
| IOV | Simple direct |
|---|---|
| MsgReceivev() | MsgReceive() |
| MsgReceivePulsev() | MsgReceivePulse() |
| MsgReplyv() | MsgReply() |
| MsgReadv() | MsgRead() |
| MsgWritev() | MsgWrite() |
In QNX Neutrino, message passing is directed towards channels and connections, rather than targeted directly from thread to thread. A thread that wishes to receive messages first creates a channel; another thread that wishes to send a message to that thread must first make a connection by "attaching" to that channel.
Channels are required by the message kernel calls and are used by servers to MsgReceive() messages on. Connections are created by client threads to "connect" to the channels made available by servers. Once connections are established, clients can MsgSend() messages over them. If a number of threads in a process all attach to the same channel, then the connections all map to the same kernel object for efficiency. Channels and connections are named within a process by a small integer identifier. Client connections map directly into file descriptors.
Architecturally, this is a key point. By having client connections map directly into FDs, we have eliminated yet another layer of translation. We don't need to "figure out" where to send a message based on the file descriptor (e.g. via a read(fd) call). Instead, we can simply send a message directly to the "file descriptor" (i.e. connection ID).
| Function | Description |
|---|---|
| ChannelCreate() | Create a channel to receive messages on. |
| ChannelDestroy() | Destroy a channel. |
| ConnectAttach() | Create a connection to send messages on. |
| ConnectDetach() | Detach a connection. |
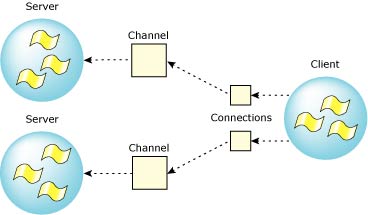
Connections map elegantly into file descriptors.
A process acting as a server would implement an event loop to receive and process messages as follows:
chid = ChannelCreate(flags);
SETIOV(&iov, &msg, sizeof(msg));
for(;;) {
rcv_id = MsgReceivev( chid, &iov, parts, &info );
switch( msg.type ) {
/* Perform message processing here */
}
MsgReplyv( rcv_id, &iov, rparts );
}
This loop allows the thread to receive messages from any thread that had a connection to the channel.
The channel has several lists of messages associated with it:
While in any of these lists, the waiting thread is blocked (i.e. RECEIVE-, SEND-, or REPLY-blocked). Multiple threads and multiple clients may wait on one channel.
In addition to the synchronous Send/Receive/Reply services, the OS also supports fixed-size, nonblocking messages. These are referred to as pulses and carry a small payload (four bytes of data plus a single byte code).
Pulses pack a relatively small payload -- eight bits of code and 32 bits of data. Pulses are often used as a notification mechanism within interrupt handlers. They also allow servers to signal clients without blocking on them.
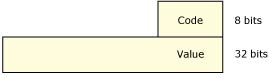
Pulses pack a small payload.
A server process receives messages in priority order. As the threads within the server receive requests, they then inherit the priority of the sending thread (but not the scheduling algorithm). As a result, the relative priorities of the threads requesting work of the server are preserved, and the server work will be executed at the appropriate priority. This message-driven priority inheritance avoids priority-inversion problems.
The message-passing API consists of the following functions:
| Function | Description |
|---|---|
| MsgSend() | Send a message and block until reply. |
| MsgReceive() | Wait for a message. |
| MsgReceivePulse() | Wait for a tiny, nonblocking message (pulse). |
| MsgReply() | Reply to a message. |
| MsgError() | Reply only with an error status. No message bytes are transferred. |
| MsgRead() | Read additional data from a received message. |
| MsgWrite() | Write additional data to a reply message. |
| MsgInfo() | Obtain info on a received message. |
| MsgSendPulse() | Send a tiny, nonblocking message (pulse). |
| MsgDeliverEvent() | Deliver an event to a client. |
| MsgKeyData() | Key a message to allow security checks. |
Architecting a QNX Neutrino application as a team of cooperating threads and processes via Send/Receive/Reply results in a system that uses synchronous notification. IPC thus occurs at specified transitions within the system, rather than asynchronously.
A significant problem with asynchronous systems is that event notification requires signal handlers to be run. Asynchronous IPC can make it difficult to thoroughly test the operation of the system and make sure that no matter when the signal handler runs, that processing will continue as intended. Applications often try to avoid this scenario by relying on a "window" explicitly opened and shut, during which signals will be tolerated.
With a synchronous, nonqueued system architecture built around Send/Receive/Reply, robust application architectures can be very readily implemented and delivered.
Avoiding deadlock situations is another difficult problem when constructing applications from various combinations of queued IPC, shared memory, and miscellaneous synchronization primitives. For example, suppose thread A doesn't release mutex 1 until thread B releases mutex 2. Unfortunately, if thread B is in the state of not releasing mutex 2 until thread A releases mutex 1, a standoff results. Simulation tools are often invoked in order to ensure that deadlock won't occur as the system runs.
The Send/Receive/Reply IPC primitives allow the construction of deadlock-free systems with the observation of only these simple rules:
The first rule is an obvious avoidance of the standoff situation, but the second rule requires further explanation. The team of cooperating threads and processes is arranged as follows:
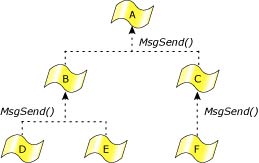
Threads should always send up to higher-level threads.
Here the threads at any given level in the hierarchy never send to each other, but send only upwards instead.
One example of this might be a client application that sends to a database server process, which in turn sends to a filesystem process. Since the sending threads block and wait for the target thread to reply, and since the target thread isn't send-blocked on the sending thread, deadlock can't happen.
But how does a higher-level thread notify a lower-level thread that it has the results of a previously requested operation? (Assume the lower-level thread didn't want to wait for the replied results when it last sent.)
QNX Neutrino provides a very flexible architecture with the MsgDeliverEvent() kernel call to deliver nonblocking events. All of the common asynchronous services can be implemented with this. For example, the server-side of the select() call is an API that an application can use to allow a thread to wait for an I/O event to complete on a set of file descriptors. In addition to an asynchronous notification mechanism being needed as a "back channel" for notifications from higher-level threads to lower-level threads, we can also build a reliable notification system for timers, hardware interrupts, and other event sources around this.
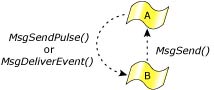
A higher-level thread can "send" a pulse event.
A related issue is the problem of how a higher-level thread can request work of a lower-level thread without sending to it, risking deadlock. The lower-level thread is present only to serve as a "worker thread" for the higher-level thread, doing work on request. The lower-level thread would send in order to "report for work," but the higher-level thread wouldn't reply then. It would defer the reply until the higher-level thread had work to be done, and it would reply (which is a nonblocking operation) with the data describing the work. In effect, the reply is being used to initiate work, not the send, which neatly side-steps rule #1.
A significant advance in the kernel design for QNX Neutrino is the event-handling subsystem. POSIX and its realtime extensions define a number of asynchronous notification methods (e.g. UNIX signals that don't queue or pass data, POSIX realtime signals that may queue and pass data, etc.).
The kernel also defines additional, QNX-specific notification techniques such as pulses. Implementing all of these event mechanisms could have consumed significant code space, so our implementation strategy was to build all of these notification methods over a single, rich, event subsystem.
A benefit of this approach is that capabilities exclusive to one notification technique can become available to others. For example, an application can apply the same queueing services of POSIX realtime signals to UNIX signals. This can simplify the robust implementation of signal handlers within applications.
The events encountered by an executing thread can come from any of three sources:
The event itself can be any of a number of different types: QNX Neutrino pulses, interrupts, various forms of signals, and forced "unblock" events. "Unblock" is a means by which a thread can be released from a deliberately blocked state without any explicit event actually being delivered.
Given this multiplicity of event types, and applications needing the ability to request whichever asynchronous notification technique best suits their needs, it would be awkward to require that server processes (the higher-level threads from the previous section) carry code to support all these options.
Instead, the client thread can give a data structure, or "cookie," to the server to hang on to until later. When the server needs to notify the client thread, it will invoke MsgDeliverEvent() and the microkernel will set the event type encoded within the cookie upon the client thread.
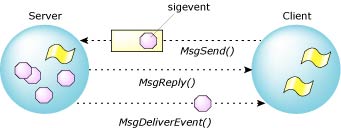
The client sends a sigevent to the server.
The ionotify() function is a means by which a client thread can request asynchronous event delivery. Many of the POSIX asynchronous services (e.g. mq_notify() and the client-side of the select()) are built on top of it. When performing I/O on a file descriptor (fd), the thread may choose to wait for an I/O event to complete (for the write() case), or for data to arrive (for the read() case). Rather than have the thread block on the resource manager process that's servicing the read/write request, ionotify() can allow the client thread to post an event to the resource manager that the client thread would like to receive when the indicated I/O condition occurs. Waiting in this manner allows the thread to continue executing and responding to event sources other than just the single I/O request.
The select() call is implemented using I/O notification and allows a thread to block and wait for a mix of I/O events on multiple fd's while continuing to respond to other forms of IPC.
Here are the conditions upon which the requested event can be delivered:
The OS supports the 32 standard POSIX signals (as in UNIX) as well as the POSIX realtime signals, both numbered from a kernel-implemented set of 64 signals with uniform functionality. While the POSIX standard defines realtime signals as differing from UNIX-style signals (in that they may contain four bytes of data and a byte code and may be queued for delivery), this functionality can be explicitly selected or deselected on a per-signal basis, allowing this converged implementation to still comply with the standard.
Incidentally, the UNIX-style signals can select POSIX realtime signal queuing, if the application wants it. QNX Neutrino also extends the signal-delivery mechanisms of POSIX by allowing signals to be targeted at specific threads, rather than simply at the process containing the threads. Since signals are an asynchronous event, they're also implemented with the event-delivery mechanisms.
| Microkernel call | POSIX call | Description |
|---|---|---|
| SignalKill() | kill(), pthread_kill(), raise(), sigqueue() | Set a signal on a process group, process, or thread. |
| SignalAction() | sigaction() | Define action to take on receipt of a signal. |
| SignalProcmask() | sigprocmask(), pthread_sigmask() | Change signal blocked mask of a thread. |
| SignalSuspend() | sigsuspend(), pause() | Block until a signal invokes a signal handler. |
| SignalWaitinfo() | sigwaitinfo() | Wait for signal and return info on it. |
The original POSIX specification defined signal operation on processes only. In a multithreaded process, the following rules are followed:
When a signal is targeted at a process with a large number of threads, the thread table must be scanned, looking for a thread with the signal unblocked. Standard practice for most multithreaded processes is to mask the signal in all threads but one, which is dedicated to handling them. To increase the efficiency of process-signal delivery, the kernel will cache the last thread that accepted a signal and will always attempt to deliver the signal to it first.
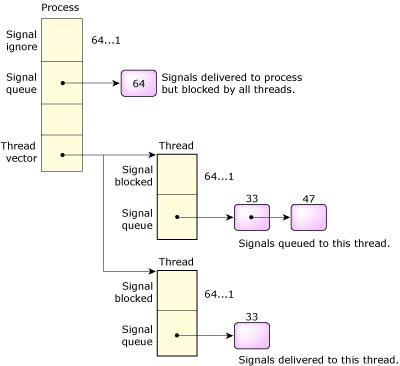
Signal delivery.
The POSIX standard includes the concept of queued realtime signals. QNX Neutrino supports optional queuing of any signal, not just realtime signals. The queuing can be specified on a signal-by-signal basis within a process. Each signal can have an associated 8-bit code and a 32-bit value.
This is very similar to message pulses described earlier. The kernel takes advantage of this similarity and uses common code for managing both signals and pulses. The signal number is mapped to a pulse priority using _SIGMAX - signo. As a result, signals are delivered in priority order with lower signal numbers having higher priority. This conforms with the POSIX standard, which states that existing signals have priority over the new realtime signals.
As mentioned earlier, the OS defines a total of 64 signals. Their range is as follows:
| Signal range | Description |
|---|---|
| 1 ... 57 | 57 POSIX signals (including traditional UNIX signals) |
| 41 ... 56 | 16 POSIX realtime signals (SIGRTMIN to SIGRTMAX) |
| 57 ... 64 | Eight special-purpose QNX Neutrino signals |
The eight special signals cannot be ignored or caught. An attempt to call the signal() or sigaction() functions or the SignalAction() kernel call to change them will fail with an error of EINVAL.
In addition, these signals are always blocked and have signal queuing enabled. An attempt to unblock these signals via the sigprocmask() function or SignalProcmask() kernel call will be quietly ignored.
A regular signal can be programmed to this behavior using the following standard signal calls. The special signals save the programmer from writing this code and protect the signal from accidental changes to this behavior.
sigset_t *set; struct sigaction action; sigemptyset(&set); sigaddset(&set, signo); sigprocmask(SIG_BLOCK, &set, NULL); action.sa_handler = SIG_DFL; action.sa_flags = SA_SIGINFO; sigaction(signo, &action, NULL);
This configuration makes these signals suitable for synchronous notification using the sigwaitinfo() function or SignalWaitinfo() kernel call. The following code will block until the eighth special signal is received:
sigset_t *set;
siginfo_t info;
sigemptyset(&set);
sigaddset(&set, SIGRTMAX + 8);
sigwaitinfo(&set, &info);
printf("Received signal %d with code %d and value %d\n",
info.si_signo,
info.si_code,
info.si_value.sival_int);
Since the signals are always blocked, the program cannot be interrupted or killed if the special signal is delivered outside of the sigwaitinfo() function. Since signal queuing is always enabled, signals won't be lost -- they'll be queued for the next sigwaitinfo() call.
These signals were designed to solve a common IPC requirement where a server wishes to notify a client that it has information available for the client. The server will use the MsgDeliverEvent() call to notify the client. There are two reasonable choices for the event within the notification: pulses or signals.
A pulse is the preferred method for a client that may also be a server to other clients. In this case, the client will have created a channel for receiving messages and can also receive the pulse.
This won't be true for most simple clients. In order to receive a pulse, a simple client would be forced to create a channel for this express purpose. A signal can be used in place of a pulse if the signal is configured to be synchronous (i.e. the signal is blocked) and queued -- this is exactly how the special signals are configured. The client would replace the MsgReceive() call used to wait for a pulse on a channel with a simple sigwaitinfo() call to wait for the signal.
This signal mechanism is used by Photon to wait for events and by the select() function to wait for I/O from multiple servers. Of the eight special signals, the first two have been given special names for this use.
#define SIGSELECT (SIGRTMAX + 1) #define SIGPHOTON (SIGRTMAX + 2)
| Signal | Description |
|---|---|
| SIGABRT | Abnormal termination signal such as issued by the abort() function. |
| SIGALRM | Timeout signal such as issued by the alarm() function. |
| SIGBUS | Indicates a memory parity error (QNX-specific interpretation). Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGCHLD | Child process terminated. The default action is to ignore the signal. |
| SIGCONT | Continue if HELD. The default action is to ignore the signal if the process isn't HELD. |
| SIGDEADLK | Mutex deadlock occurred. If you haven't called SyncMutexEvent(), and if the conditions that would cause the kernel to deliver the event occur, then the kernel delivers a SIGDEADLK instead. |
| SIGEMT | EMT instruction (emulator trap). |
| SIGFPE | Erroneous arithmetic operation (integer or floating point), such as division by zero or an operation resulting in overflow. Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGHUP | Death of session leader, or hangup detected on controlling terminal. |
| SIGILL | Detection of an invalid hardware instruction. Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGINT | Interactive attention signal (Break). |
| SIGIOT | IOT instruction (not generated on x86 hardware). |
| SIGKILL | Termination signal -- should be used only for emergency situations. This signal cannot be caught or ignored. |
| SIGPIPE | Attempt to write on a pipe with no readers. |
| SIGPOLL | Pollable event occurred. |
| SIGQUIT | Interactive termination signal. |
| SIGSEGV | Detection of an invalid memory reference. Note that if a second fault occurs while your process is in a signal handler for this fault, the process will be terminated. |
| SIGSTOP | Stop process (the default). This signal cannot be caught or ignored. |
| SIGSYS | Bad argument to system call. |
| SIGTERM | Termination signal. |
| SIGTRAP | Unsupported software interrupt. |
| SIGTSTP | Stop signal generated from keyboard. |
| SIGTTIN | Background read attempted from control terminal. |
| SIGTTOU | Background write attempted to control terminal. |
| SIGURG | Urgent condition present on socket. |
| SIGUSR1 | Reserved as application-defined signal 1. |
| SIGUSR2 | Reserved as application-defined signal 2. |
| SIGWINCH | Window size changed. |
POSIX defines a set of nonblocking message-passing facilities known as message queues. Like pipes, message queues are named objects that operate with "readers" and "writers." As a priority queue of discrete messages, a message queue has more structure than a pipe and offers applications more control over communications.
|
To use POSIX message queues in QNX Neutrino, the message
queue server must be running.
QNX Neutrino has two implementations of message queues:
For more information about these implementations, see the Utilities Reference. |
Unlike our inherent message-passing primitives, the POSIX message queues reside outside the kernel.
POSIX message queues provide a familiar interface for many realtime programmers. They are similar to the "mailboxes" found in many realtime executives.
There's a fundamental difference between our messages and POSIX message queues. Our messages block -- they copy their data directly between the address spaces of the processes sending the messages. POSIX messages queues, on the other hand, implement a store-and-forward design in which the sender need not block and may have many outstanding messages queued. POSIX message queues exist independently of the processes that use them. You would likely use message queues in a design where a number of named queues will be operated on by a variety of processes over time.
For raw performance, POSIX message queues will be slower than QNX Neutrino native messages for transferring data. However, the flexibility of queues may make this small performance penalty worth the cost.
Message queues resemble files, at least as far as their interface is concerned. You open a message queue with mq_open(), close it with mq_close(), and destroy it with mq_unlink(). And to put data into ("write") and take it out of ("read") a message queue, you use mq_send() and mq_receive().
For strict POSIX conformance, you should create message queues that start with a single slash (/) and contain no other slashes. But note that we extend the POSIX standard by supporting pathnames that may contain multiple slashes. This allows, for example, a company to place all its message queues under its company name and distribute a product with increased confidence that a queue name will not conflict with that of another company.
In QNX Neutrino, all message queues created will appear in the filename space under the directory:
For example, with the traditional implementation:
| mq_open() name: | Pathname of message queue: |
|---|---|
| /data | /dev/mqueue/data |
| /acme/data | /dev/mqueue/acme/data |
| /qnx/data | /dev/mqueue/qnx/data |
You can display all message queues in the system using the ls command as follows:
ls -Rl /dev/mqueue
The size printed is the number of messages waiting.
POSIX message queues are managed via the following functions:
| Function | Description |
|---|---|
| mq_open() | Open a message queue. |
| mq_close() | Close a message queue. |
| mq_unlink() | Remove a message queue. |
| mq_send() | Add a message to the message queue. |
| mq_receive() | Receive a message from the message queue. |
| mq_notify() | Tell the calling process that a message is available on a message queue. |
| mq_setattr() | Set message queue attributes. |
| mq_getattr() | Get message queue attributes. |
Shared memory offers the highest bandwidth IPC available. Once a shared-memory object is created, processes with access to the object can use pointers to directly read and write into it. This means that access to shared memory is in itself unsynchronized. If a process is updating an area of shared memory, care must be taken to prevent another process from reading or updating the same area. Even in the simple case of a read, the other process may get information that is in flux and inconsistent.
To solve these problems, shared memory is often used in conjunction with one of the synchronization primitives to make updates atomic between processes. If the granularity of updates is small, then the synchronization primitives themselves will limit the inherently high bandwidth of using shared memory. Shared memory is therefore most efficient when used for updating large amounts of data as a block.
Both semaphores and mutexes are suitable synchronization primitives for use with shared memory. Semaphores were introduced with the POSIX realtime standard for interprocess synchronization. Mutexes were introduced with the POSIX threads standard for thread synchronization. Mutexes may also be used between threads in different processes. POSIX considers this an optional capability; we support it. In general, mutexes are more efficient than semaphores.
Shared memory and message passing can be combined to provide IPC that offers:
Using message passing, a client sends a request to a server and blocks. The server receives the messages in priority order from clients, processes them, and replies when it can satisfy a request. At this point, the client is unblocked and continues. The very act of sending messages provides natural synchronization between the client and the server. Rather than copy all the data through the message pass, the message can contain a reference to a shared-memory region, so the server could read or write the data directly. This is best explained with a simple example.
Let's assume a graphics server accepts draw image requests from clients and renders them into a frame buffer on a graphics card. Using message passing alone, the client would send a message containing the image data to the server. This would result in a copy of the image data from the client's address space to the server's address space. The server would then render the image and issue a short reply.
If the client didn't send the image data inline with the message, but instead sent a reference to a shared-memory region that contained the image data, then the server could access the client's data directly.
Since the client is blocked on the server as a result of sending it a message, the server knows that the data in shared memory is stable and will not change until the server replies. This combination of message passing and shared memory achieves natural synchronization and very high performance.
This model of operation can also be reversed -- the server can generate data and give it to a client. For example, suppose a client sends a message to a server that will read video data directly from a CD-ROM into a shared memory buffer provided by the client. The client will be blocked on the server while the shared memory is being changed. When the server replies and the client continues, the shared memory will be stable for the client to access. This type of design can be pipelined using more than one shared-memory region.
Simple shared memory can't be used between processes on different computers connected via a network. Message passing, on the other hand, is network transparent. A server could use shared memory for local clients and full message passing of the data for remote clients. This allows you to provide a high-performance server that is also network transparent.
In practice, the message-passing primitives are more than fast enough for the majority of IPC needs. The added complexity of a combined approach need only be considered for special applications with very high bandwidth.
Multiple threads within a process share the memory of that process. To share memory between processes, you must first create a shared-memory region and then map that region into your process's address space. Shared-memory regions are created and manipulated using the following calls:
| Function | Description |
|---|---|
| shm_open() | Open (or create) a shared-memory region. |
| close() | Close a shared-memory region. |
| mmap() | Map a shared-memory region into a process's address space. |
| munmap() | Unmap a shared-memory region from a process's address space. |
| mprotect() | Change protections on a shared-memory region. |
| msync() | Synchronize memory with physical storage. |
| shm_ctl() | Give special attributes to a shared-memory object. |
| shm_unlink() | Remove a shared-memory region. |
POSIX shared memory is implemented in QNX Neutrino via the process manager (procnto). The above calls are implemented as messages to procnto (see the Process Manager chapter in this book).
The shm_open() function takes the same arguments as open() and returns a file descriptor to the object. As with a regular file, this function lets you create a new shared-memory object or open an existing shared-memory object.
When a new shared-memory object is created, the size of the object is set to zero. To set the size, you use the ftruncate() or shm_ctl() function. Note that this is the very same function used to set the size of a file.
Once you have a file descriptor to a shared-memory object, you use the mmap() function to map the object, or part of it, into your process's address space. The mmap() function is the cornerstone of memory management within QNX Neutrino and deserves a detailed discussion of its capabilities.
The mmap() function is defined as follows:
void * mmap(void *where_i_want_it, size_t length,
int memory_protections, int mapping_flags, int fd,
off_t offset_within_shared_memory);
In simple terms this says: "Map in length bytes of shared memory at offset_within_shared_memory in the shared-memory object associated with fd."
The mmap() function will try to place the memory at the address where_i_want_it in your address space. The memory will be given the protections specified by memory_protections and the mapping will be done according to the mapping_flags.
The three arguments fd, offset_within_shared_memory, and length define a portion of a particular shared object to be mapped in. It's common to map in an entire shared object, in which case the offset will be zero and the length will be the size of the shared object in bytes. On an Intel processor, the length will be a multiple of the page size, which is 4096 bytes.
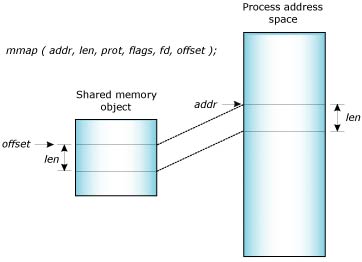
Arguments to mmap().
The return value of mmap() will be the address in your process's address space where the object was mapped. The argument where_i_want_it is used as a hint by the system to where you want the object placed. If possible, the object will be placed at the address requested. Most applications specify an address of zero, which gives the system free reign to place the object where it wishes.
The following protection types may be specified for memory_protections:
| Manifest | Description |
|---|---|
| PROT_EXEC | Memory may be executed. |
| PROT_NOCACHE | Memory should not be cached. |
| PROT_NONE | No access allowed. |
| PROT_READ | Memory may be read. |
| PROT_WRITE | Memory may be written. |
The PROT_NOCACHE manifest should be used when a shared-memory region is used to gain access to dual-ported memory that may be modified by hardware (e.g. a video frame buffer or a memory-mapped network or communications board). Without this manifest, the processor may return "stale" data from a previously cached read.
The mapping_flags determine how the memory is mapped. These flags are broken down into two parts -- the first part is a type and must be specified as one of the following:
| Map type | Description |
|---|---|
| MAP_SHARED | The mapping is shared by the calling processes. |
| MAP_PRIVATE | The mapping is private to the calling process. It allocates system RAM and makes a copy of the object. |
The MAP_SHARED type is the one to use for setting up shared memory between processes; MAP_PRIVATE has more specialized uses.
A number of flags may be ORed into the above type to further define the mapping. These are described in detail in the mmap() entry in the Library Reference. A few of the more interesting flags are:
| Map type modifier | Description |
|---|---|
| MAP_ANON | You commonly use this with MAP_PRIVATE; you must set the fd parameter to NOFD. You can use MAP_ANON as the basis for a page-level memory allocator. By default, the allocated memory is zero-filled; see "Initializing allocated memory," below. |
| MAP_FIXED | Map object to the address specified by where_i_want_it. If a shared-memory region contains pointers within it, then you may need to force the region at the same address in all processes that map it. This can be avoided by using offsets within the region in place of direct pointers. |
| MAP_PHYS | This flag indicates that you wish to deal with physical memory. The fd parameter should be set to NOFD. When used with MAP_SHARED, the offset_within_shared_memory specifies the exact physical address to map (e.g. for video frame buffers). If used with MAP_ANON then physically contiguous memory is allocated (e.g. for a DMA buffer). MAP_NOX64K and MAP_BELOW16M are used to further define the MAP_ANON allocated memory and address limitations present in some forms of DMA. |
| MAP_NOX64K | Used with MAP_PHYS | MAP_ANON. The allocated memory area will not cross a 64K boundary. This is required for the old 16-bit PC DMA. |
| MAP_BELOW16M | Used with MAP_PHYS | MAP_ANON. The allocated memory area will reside in physical memory below 16M. This is necessary when using DMA with ISA bus devices. |
| MAP_NOINIT | Relax the POSIX requirement to zero the allocated memory; see "Initializing allocated memory," below. |
Using the mapping flags described above, a process can easily share memory between processes:
/* Map in a shared memory region */
fd = shm_open("datapoints", O_RDWR);
addr = mmap(0, len, PROT_READ|PROT_WRITE, MAP_SHARED, fd, 0);
Or share memory with hardware such as video memory:
/* Map in VGA display memory */
addr = mmap(0, 65536, PROT_READ|PROT_WRITE,
MAP_PHYS|MAP_SHARED, NOFD, 0xa0000);
Or allocate a DMA buffer for a bus-mastering PCI network card:
/* Allocate a physically contiguous buffer */
addr = mmap(0, 262144, PROT_READ|PROT_WRITE|PROT_NOCACHE,
MAP_PHYS|MAP_ANON, NOFD, 0);
You can unmap all or part of a shared-memory object from your address space using munmap(). This primitive isn't restricted to unmapping shared memory -- it can be used to unmap any region of memory within your process. When used in conjunction with the MAP_ANON flag to mmap(), you can easily implement a private page-level allocator/deallocator.
You can change the protections on a mapped region of memory using mprotect(). Like munmap(), mprotect() isn't restricted to shared-memory regions -- it can change the protection on any region of memory within your process.
POSIX requires that mmap() zero any memory that it allocates. It can take a while to initialize the memory, so QNX Neutrino provides a way to relax the POSIX requirement. This allows for faster starting, but can be a security problem.
|
This feature was added in the QNX Neutrino Core OS 6.3.2. |
Avoiding initializing the memory requires the cooperation of the process doing the unmapping and the one doing the mapping:
int munmap_flags( void *addr, size_t len,
unsigned flags );
Pass one of the following for the flags argument:
By default, the kernel initializes the memory, but you can control this by using the -m option to procnto. The argument to this option is a string that lets you enable or disable aspects of the memory manager:
Note again that munmap_flags() with a flags argument of 0 behaves the same as munmap() does.
|
To use pipes or FIFOs in QNX Neutrino, the pipe resource manager (pipe) must be running. |
A pipe is an unnamed file that serves as an I/O channel between two or more cooperating processes--one process writes into the pipe, the other reads from the pipe. The pipe manager takes care of buffering the data. The buffer size is defined as PIPE_BUF in the <limits.h> file. A pipe is removed once both of its ends have closed. The function pathconf() returns the value of the limit.
Pipes are normally used when two processes want to run in parallel, with data moving from one process to the other in a single direction. (If bidirectional communication is required, messages should be used instead.)
A typical application for a pipe is connecting the output of one program to the input of another program. This connection is often made by the shell. For example:
ls | more
directs the standard output from the ls utility through a pipe to the standard input of the more utility.
| If you want to: | Use the: |
|---|---|
| Create pipes from within the shell | pipe symbol ("|") |
| Create pipes from within programs | pipe() or popen() functions |
FIFOs are essentially the same as pipes, except that FIFOs are named permanent files that are stored in filesystem directories.
| If you want to: | Use the: |
|---|---|
| Create FIFOs from within the shell | mkfifo utility |
| Create FIFOs from within programs | mkfifo() function |
| Remove FIFOs from within the shell | rm utility |
| Remove FIFOs from within programs | remove() or unlink() function |
Clock services are used to maintain the time of day, which is in turn used by the kernel timer calls to implement interval timers.
|
Valid dates on a QNX Neutrino system range from January 1970 to January 2554, but note that POSIX-compliant code may be limited to the year 2038. The internal date and time representation reaches its maximum value in 2554. If your system must operate past 2554 and there's no way for the system to be upgraded or modified in the field, you'll have to take special care with system dates (contact us for help with this). |
The ClockTime() kernel call allows you to get or set the system clock specified by an ID (CLOCK_REALTIME), which maintains the system time. Once set, the system time increments by some number of nanoseconds based on the resolution of the system clock. This resolution can be queried or changed using the ClockPeriod() call.
Within the system page, an in-memory data structure, there's a 64-bit field (nsec) that holds the number of nanoseconds since the system was booted. The nsec field is always monotonically increasing and is never affected by setting the current time of day via ClockTime() or ClockAdjust().
The ClockCycles() function returns the current value of a free-running 64-bit cycle counter. This is implemented on each processor as a high-performance mechanism for timing short intervals. For example, on Intel x86 processors, an opcode that reads the processor's time-stamp counter is used. On a Pentium processor, this counter increments on each clock cycle. A 100 MHz Pentium would have a cycle time of 1/100,000,000 seconds (10 nanoseconds). Other CPU architectures have similar instructions.
On processors that don't implement such an instruction in hardware (e.g. a 386), the kernel will emulate one. This will provide a lower time resolution than if the instruction is provided (838.095345 nanoseconds on an IBM PC-compatible system).
In all cases, the SYSPAGE_ENTRY(qtime)->cycles_per_sec field gives the number of ClockCycles() increments in one second.
The ClockPeriod() function allows a thread to set the system timer to some multiple of nanoseconds; the OS kernel will do the best it can to satisfy the precision of the request with the hardware available.
The interval selected is always rounded down to an integral of the precision of the underlying hardware timer. Of course, setting it to an extremely low value can result in a significant portion of CPU performance being consumed servicing timer interrupts.
| Microkernel call | POSIX call | Description |
|---|---|---|
| ClockTime() | clock_gettime(), clock_settime() | Get or set the time of day (using a 64-bit value in nanoseconds ranging from 1970 to 2554). |
| ClockAdjust() | N/A | Apply small time adjustments to synchronize clocks. |
| ClockCycles() | N/A | Read a 64-bit free-running high-precision counter. |
| ClockPeriod() | clock_getres() | Get or set the period of the clock. |
| ClockId() | clock_getcpuclockid(), pthread_getcpuclockid() | Return an integer that's passed to ClockTime() as a clockid_t. |
In order to facilitate applying time corrections without having the system experience abrupt "steps" in time (or even having time jump backwards), the ClockAdjust() call provides the option to specify an interval over which the time correction is to be applied. This has the effect of speeding or retarding time over a specified interval until the system has synchronized to the indicated current time. This service can be used to implement network-coordinated time averaging between multiple nodes on a network.
QNX Neutrino directly provides the full set of POSIX timer functionality. Since these timers are quick to create and manipulate, they're an inexpensive resource in the kernel.
The POSIX timer model is quite rich, providing the ability to have the timer expire on:
The cyclical mode is very significant, because the most common use of timers tends to be as a periodic source of events to "kick" a thread into life to do some processing and then go back to sleep until the next event. If the thread had to re-program the timer for every event, there would be the danger that time would slip unless the thread was programming an absolute date. Worse, if the thread doesn't get to run on the timer event because a higher-priority thread is running, the date next programmed into the timer could be one that has already elapsed!
The cyclical mode circumvents these problems by requiring that the thread set the timer once and then simply respond to the resulting periodic source of events.
Since timers are another source of events in the OS, they also make use of its event-delivery system. As a result, the application can request that any of the Neutrino-supported events be delivered to the application upon occurrence of a timeout.
An often-needed timeout service provided by the OS is the ability to specify the maximum time the application is prepared to wait for any given kernel call or request to complete. A problem with using generic OS timer services in a preemptive realtime OS is that in the interval between the specification of the timeout and the request for the service, a higher-priority process might have been scheduled to run and preempted long enough that the specified timeout will have expired before the service is even requested. The application will then end up requesting the service with an already lapsed timeout in effect (i.e. no timeout). This timing window can result in "hung" processes, inexplicable delays in data transmission protocols, and other problems.
alarm(...); ... ... <-- Alarm fires here ... blocking_call();
Our solution is a form of timeout request atomic to the service request itself. One approach might have been to provide an optional timeout parameter on every available service request, but this would overly complicate service requests with a passed parameter that would often go unused.
QNX Neutrino provides a TimerTimeout() kernel call that allows an application to specify a list of blocking states for which to start a specified timeout. Later, when the application makes a request of the kernel, the kernel will atomically enable the previously configured timeout if the application is about to block on one of the specified states.
Since the OS has a very small number of blocking states, this mechanism works very concisely. At the conclusion of either the service request or the timeout, the timer will be disabled and control will be given back to the application.
TimerTimeout(...); ... ... ... blocking_call(); ... <-- Timer atomically armed within kernel
| Microkernel call | POSIX call | Description |
|---|---|---|
| TimerAlarm() | alarm() | Set a process alarm. |
| TimerCreate() | timer_create() | Create an interval timer. |
| TimerDestroy() | timer_delete() | Destroy an interval timer. |
| TimerInfo() | timer_gettime() | Get time remaining on an interval timer. |
| TimerInfo() | timer_getoverrun() | Get number of overruns on an interval timer. |
| TimerSettime() | timer_settime() | Start an interval timer. |
| TimerTimeout() | sleep(), nanosleep(), sigtimedwait(), pthread_cond_timedwait(), pthread_mutex_trylock() | Arm a kernel timeout for any blocking state. |
No matter how much we wish it were so, computers are not infinitely fast. In a realtime system, it's absolutely crucial that CPU cycles aren't unnecessarily spent. It's also crucial to minimize the time from the occurrence of an external event to the actual execution of code within the thread responsible for reacting to that event. This time is referred to as latency.
The two forms of latency that most concern us are interrupt latency and scheduling latency.
|
Latency times can vary significantly, depending on the speed of the processor and other factors. For more information, visit our website (www.qnx.com). |
Interrupt latency is the time from the assertion of a hardware interrupt until the first instruction of the device driver's interrupt handler is executed. The OS leaves interrupts fully enabled almost all the time, so that interrupt latency is typically insignificant. But certain critical sections of code do require that interrupts be temporarily disabled. The maximum such disable time usually defines the worst-case interrupt latency -- in QNX Neutrino this is very small.
The following diagrams illustrate the case where a hardware interrupt is processed by an established interrupt handler. The interrupt handler either will simply return, or it will return and cause an event to be delivered.
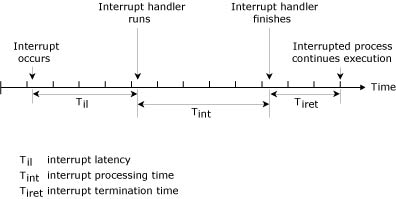
Interrupt handler simply terminates.
The interrupt latency (Til) in the above diagram represents the minimum latency -- that which occurs when interrupts were fully enabled at the time the interrupt occurred. Worst-case interrupt latency will be this time plus the longest time in which the OS, or the running system process, disables CPU interrupts.
In some cases, the low-level hardware interrupt handler must schedule a higher-level thread to run. In this scenario, the interrupt handler will return and indicate that an event is to be delivered. This introduces a second form of latency -- scheduling latency -- which must be accounted for.
Scheduling latency is the time between the last instruction of the user's interrupt handler and the execution of the first instruction of a driver thread. This usually means the time it takes to save the context of the currently executing thread and restore the context of the required driver thread. Although larger than interrupt latency, this time is also kept small in a QNX Neutrino system.
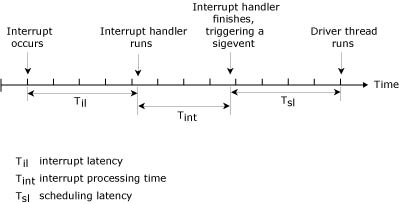
Interrupt handler terminates, returning an event.
It's important to note that most interrupts terminate without delivering an event. In a large number of cases, the interrupt handler can take care of all hardware-related issues. Delivering an event to wake up a higher-level driver thread occurs only when a significant event occurs. For example, the interrupt handler for a serial device driver would feed one byte of data to the hardware upon each received transmit interrupt, and would trigger the higher-level thread within (devc-ser*) only when the output buffer is nearly empty.
QNX Neutrino fully supports nested interrupts. The previous scenarios describe the simplest -- and most common -- situation where only one interrupt occurs. Worst-case timing considerations for unmasked interrupts must take into account the time for all interrupts currently being processed, because a higher priority, unmasked interrupt will preempt an existing interrupt.
In the following diagram, Thread A is running. Interrupt IRQx causes interrupt handler Intx to run, which is preempted by IRQy and its handler Inty. Inty returns an event causing Thread B to run; Intx returns an event causing Thread C to run.
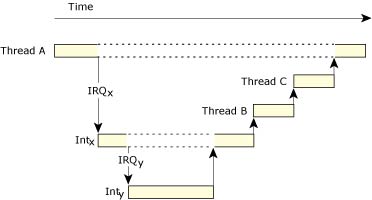
Stacked interrupts.
The interrupt-handling API includes the following kernel calls:
| Function | Description |
|---|---|
| InterruptAttach() | Attach a local function to an interrupt vector. |
| InterruptAttachEvent() | Generate an event on an interrupt, which will ready a thread. No user interrupt handler runs. This is the preferred call. |
| InterruptDetach() | Detach from an interrupt using the ID returned by InterruptAttach() or InterruptAttachEvent(). |
| InterruptWait() | Wait for an interrupt. |
| InterruptEnable() | Enable hardware interrupts. |
| InterruptDisable() | Disable hardware interrupts. |
| InterruptMask() | Mask a hardware interrupt. |
| InterruptUnmask() | Unmask a hardware interrupt. |
| InterruptLock() | Guard a critical section of code between an interrupt handler and a thread. A spinlock is used to make this code SMP-safe. This function is a superset of InterruptDisable() and should be used in its place. |
| InterruptUnlock() | Remove an SMP-safe lock on a critical section of code. |
Using this API, a suitably privileged user-level thread can call InterruptAttach() or InterruptAttachEvent(), passing a hardware interrupt number and the address of a function in the thread's address space to be called when the interrupt occurs. QNX Neutrino allows multiple ISRs to be attached to each hardware interrupt number -- unmasked interrupts can be serviced during the execution of running interrupt handlers.
|
For more information on InterruptLock() and InterruptUnlock(), see "Critical sections" in the chapter on Multicore Processing in this guide. |
The following code sample shows how to attach an ISR to the hardware timer interrupt on the PC (which the OS also uses for the system clock). Since the kernel's timer ISR is already dealing with clearing the source of the interrupt, this ISR can simply increment a counter variable in the thread's data space and return to the kernel:
#include <stdio.h>
#include <sys/neutrino.h>
#include <sys/syspage.h>
struct sigevent event;
volatile unsigned counter;
const struct sigevent *handler( void *area, int id ) {
// Wake up the thread every 100th interrupt
if ( ++counter == 100 ) {
counter = 0;
return( &event );
}
else
return( NULL );
}
int main() {
int i;
int id;
// Request I/O privileges
ThreadCtl( _NTO_TCTL_IO, 0 );
// Initialize event structure
event.sigev_notify = SIGEV_INTR;
// Attach ISR vector
id=InterruptAttach( SYSPAGE_ENTRY(qtime)->intr, &handler,
NULL, 0, 0 );
for( i = 0; i < 10; ++i ) {
// Wait for ISR to wake us up
InterruptWait( 0, NULL );
printf( "100 events\n" );
}
// Disconnect the ISR handler
InterruptDetach(id);
return 0;
}
With this approach, appropriately privileged user-level threads can dynamically attach (and detach) interrupt handlers to (and from) hardware interrupt vectors at run time. These threads can be debugged using regular source-level debug tools; the ISR itself can be debugged by calling it at the thread level and source-level stepping through it or by using the InterruptAttachEvent() call.
When the hardware interrupt occurs, the processor will enter the interrupt redirector in the microkernel. This code pushes the registers for the context of the currently running thread into the appropriate thread table entry and sets the processor context such that the ISR has access to the code and data that are part of the thread the ISR is contained within. This allows the ISR to use the buffers and code in the user-level thread to resolve the interrupt and, if higher-level work by the thread is required, to queue an event to the thread the ISR is part of, which can then work on the data the ISR has placed into thread-owned buffers.
Since it runs with the memory-mapping of the thread containing it, the ISR can directly manipulate devices mapped into the thread's address space, or directly perform I/O instructions. As a result, device drivers that manipulate hardware don't need to be linked into the kernel.
The interrupt redirector code in the microkernel will call each ISR attached to that hardware interrupt. If the value returned indicates that a process is to be passed an event of some sort, the kernel will queue the event. When the last ISR has been called for that vector, the kernel interrupt handler will finish manipulating the interrupt control hardware and then "return from interrupt."
This interrupt return won't necessarily be into the context of the thread that was interrupted. If the queued event caused a higher-priority thread to become READY, the microkernel will then interrupt-return into the context of the now-READY thread instead.
This approach provides a well-bounded interval from the occurrence of the interrupt to the execution of the first instruction of the user-level ISR (measured as interrupt latency), and from the last instruction of the ISR to the first instruction of the thread readied by the ISR (measured as thread or process scheduling latency).
The worst-case interrupt latency is well-bounded, because the OS disables interrupts only for a couple opcodes in a few critical regions. Those intervals when interrupts are disabled have deterministic runtimes, because they're not data dependent.
The microkernel's interrupt redirector executes only a few instructions before calling the user's ISR. As a result, process preemption for hardware interrupts or kernel calls is equally quick and exercises essentially the same code path.
While the ISR is executing, it has full hardware access (since it's part of a privileged thread), but can't issue other kernel calls. The ISR is intended to respond to the hardware interrupt in as few microseconds as possible, do the minimum amount of work to satisfy the interrupt (read the byte from the UART, etc.), and if necessary, cause a thread to be scheduled at some user-specified priority to do further work.
Worst-case interrupt latency is directly computable for a given hardware priority from the kernel-imposed interrupt latency and the maximum ISR runtime for each interrupt higher in hardware priority than the ISR in question. Since hardware interrupt priorities can be reassigned, the most important interrupt in the system can be made the highest priority.
Note also that by using the InterruptAttachEvent() call, no user ISR is run. Instead, a user-specified event is generated on each and every interrupt; the event will typically cause a waiting thread to be scheduled to run and do the work. The interrupt is automatically masked when the event is generated and then explicitly unmasked by the thread that handles the device at the appropriate time.
|
Both InterruptMask() and InterruptUnmask() are counting functions. For example, if InterruptMask() is called ten times, then InterruptUnmask() must also be called ten times. |
Thus the priority of the work generated by hardware interrupts can be performed at OS-scheduled priorities rather than hardware-defined priorities. Since the interrupt source won't re-interrupt until serviced, the effect of interrupts on the runtime of critical code regions for hard-deadline scheduling can be controlled.
In addition to hardware interrupts, various "events" within the microkernel can also be "hooked" by user processes and threads. When one of these events occurs, the kernel can upcall into the indicated function in the user thread to perform some specific processing for this event. For example, whenever the idle thread in the system is called, a user thread can have the kernel upcall into the thread so that hardware-specific low-power modes can be readily implemented.
| Microkernel call | Description |
|---|---|
| InterruptHookIdle() | When the kernel has no active thread to schedule, it will run the idle thread, which can upcall to a user handler. This handler can perform hardware-specific power-management operations. |
| InterruptHookTrace() | This function attaches a pseudo interrupt handler that can receive trace events from the instrumented kernel. |
|
|
|
|