![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
In QNX Neutrino, the microkernel is paired with the Process Manager in a single module (procnto). This module is required for all runtime systems.
The process manager is capable of creating multiple POSIX processes (each of which may contain multiple POSIX threads). Its main areas of responsibility include:
User processes can access microkernel functions directly via kernel calls and process manager functions by sending messages to procnto. Note that a user process sends a message by invoking the MsgSend*() kernel call.
It's important to note that threads executing within procnto invoke the microkernel in exactly the same way as threads in other processes. The fact that the process manager code and the microkernel share the same process address space doesn't imply a "special" or "private" interface. All threads in the system share the same consistent kernel interface and all perform a privilege switch when invoking the microkernel.
The first responsibility of procnto is to dynamically create new processes. These processes will then depend on procnto's other responsibilities of memory management and pathname management.
Process management consists of both process creation and destruction as well as the management of process attributes such as process IDs, process groups, user IDs, etc.
There are four process primitives:
The spawn() call was introduced by POSIX. The function creates a child process by directly specifying an executable to load. To those familiar with UNIX systems, the call is modeled after a fork() followed by an exec*(). However, it operates much more efficiently in that there's no need to duplicate address spaces as in a fork(), only to destroy and replace it when the exec*() is called.
One of the main advantages of using the fork()-then-exec*() method of creating a child process is the flexibility in changing the default environment inherited by the new child process. This is done in the forked child just before the exec*(). For example, the following simple shell command would close and reopen the standard output before exec*()'ing:
ls >file
The POSIX spawn() function gives control over four classes of environment inheritance, which are often adjusted when creating a new child process:
Our implementation also allows you to change:
There are two forms of the POSIX spawn() function:
There's also a set of non-POSIX convenience functions that are built on top of spawn() and spawnp() as follows:
Using spawn() is the preferred way to create a new child process.
When a process is spawn()'ed, the child process inherits the following attributes of its parent:
The child process has several differences from the parent process:
If the child process is spawned on a remote node, the process group ID and the session membership aren't set; the child process is put into a new session and a new process group.
The child process can access the parent process's environment by using the environ global variable (found in <unistd.h>).
For more information, see the spawn() function in the Library Reference.
The fork() function creates a new child process by sharing the same code as the calling process and duplicating the calling process's data to give the child process an exact copy. Most process resources are inherited. The following lists some resources that are explicitly not inherited:
The fork() function is typically used for one of two reasons:
When creating a new thread, common data is placed in an explicitly created shared memory region. Prior to the POSIX thread standard, this was the only way to accomplish this. With POSIX threads, this use of fork() is better accomplished by creating threads within a single process using pthread_create().
When creating a new process running a different program, the call to fork() is soon followed by a call to one of the exec*() functions. This too is better accomplished by a single call to the POSIX spawn() function, which combines both operations with far greater efficiency.
Since QNX Neutrino provides better POSIX solutions than using fork(), its use is probably best suited for porting existing code and for writing portable code that must run on a UNIX system that doesn't support the POSIX pthread_create() or spawn() API.
 |
Note that fork() should be called from a process containing only a single thread. |
The vfork() function (which should also be called only from a single-threaded process) is useful when the purpose of fork() would have been to create a new system context for a call to one of the exec*() functions. The vfork() function differs from fork() in that the child doesn't get a copy of the calling process's data. Instead, it borrows the calling process's memory and thread of control until a call to one of the exec*() functions is made. The calling process is suspended while the child is using its resources.
The vfork() child can't return from the procedure that called vfork(), since the eventual return from the parent vfork() would then return to a stack frame that no longer existed.
The exec*() family of functions replaces the current process with a new process, loaded from an executable file. Since the calling process is replaced, there can be no successful return.
The following exec*() functions are defined:
The exec*() functions usually follow a fork() or vfork() in order to load a new child process. This is better achieved by using the new POSIX spawn() call.
Processes loaded from a filesystem using either the exec*() or spawn() calls are in ELF format. If the filesystem is on a block-oriented device, the code and data are loaded into main memory.
If the filesystem is memory mapped (e.g. ROM/Flash image), the code needn't be loaded into RAM, but may be executed in place. This approach makes all RAM available for data and stack, leaving the code in ROM or Flash. In all cases, if the same process is loaded more than once, its code will be shared.
While some realtime kernels or executives provide support for memory protection in the development environment, few provide protected memory support for the runtime configuration, citing penalties in memory and performance as reasons. But with memory protection becoming common on many embedded processors, the benefits of memory protection far outweigh the very small penalties in performance for enabling it.
The key advantage gained by adding memory protection to embedded applications, especially for mission-critical systems, is improved robustness.
With memory protection, if one of the processes executing in a multitasking environment attempts to access memory that hasn't been explicitly declared or allocated for the type of access attempted, the MMU hardware can notify the OS, which can then abort the thread (at the failing/offending instruction).
This "protects" process address spaces from each other, preventing coding errors in a thread on one process from "damaging" memory used by threads in other processes or even in the OS. This protection is useful both for development and for the installed runtime system, because it makes postmortem analysis possible.
During development, common coding errors (e.g. stray pointers and indexing beyond array bounds) can result in one process/thread accidentally overwriting the data space of another process. If the overwrite touches memory that isn't referenced again until much later, you can spend hours of debugging -- often using in-circuit emulators and logic analyzers -- in an attempt to find the "guilty party."
With an MMU enabled, the OS can abort the process the instant the memory-access violation occurs, providing immediate feedback to the programmer instead of mysteriously crashing the system some time later. The OS can then provide the location of the errant instruction in the failed process, or position a symbolic debugger directly to this instruction.
A typical MMU operates by dividing physical memory into a number of 4-KB pages. The hardware within the processor then makes use of a set of page tables stored in system memory that define the mapping of virtual addresses (i.e. the memory addresses used within the application program) to the addresses emitted by the CPU to access physical memory.
While the thread executes, the page tables managed by the OS control how the memory addresses that the thread is using are "mapped" onto the physical memory attached to the processor.
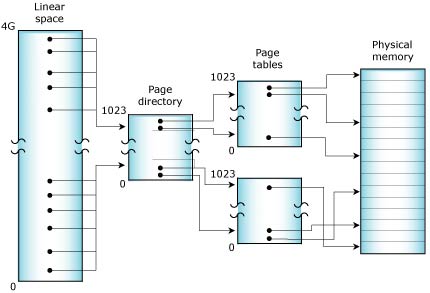
Virtual address mapping (on an x86).
For a large address space with many processes and threads, the number of page-table entries needed to describe these mappings can be significant -- more than can be stored within the processor. To maintain performance, the processor caches frequently used portions of the external page tables within a TLB (translation look-aside buffer).
The servicing of "misses" on the TLB cache is part of the overhead imposed by enabling the MMU. Our OS uses various clever page-table arrangements to minimize this overhead.
Associated with these page tables are bits that define the attributes of each page of memory. Pages can be marked as read-only, read-write, etc. Typically, the memory of an executing process would be described with read-only pages for code and read-write for the data and stack.
When the OS performs a context switch (i.e. suspends the execution of one thread and resumes another), it will manipulate the MMU to use a potentially different set of page tables for the newly resumed thread. If the OS is switching between threads within a single process, no MMU manipulations are necessary.
When the new thread resumes execution, any addresses generated as the thread runs are mapped to physical memory through the assigned page tables. If the thread tries to use an address not mapped to it or to use an address in a way that violates the defined attributes (e.g. writing to a read-only page), the CPU will receive a "fault" (similar to a divide-by-zero error), typically implemented as a special type of interrupt.
By examining the instruction pointer pushed on the stack by the interrupt, the OS can determine the address of the instruction that caused the memory-access fault within the thread/process and can act accordingly.
While memory protection is useful during development, it can also provide greater reliability for embedded systems installed in the field. Many embedded systems already employ a hardware "watchdog timer" to detect if the software or hardware has "lost its mind," but this approach lacks the finesse of an MMU-assisted watchdog.
Hardware watchdog timers are usually implemented as a retriggerable monostable timer attached to the processor reset line. If the system software doesn't strobe the hardware timer regularly, the timer will expire and force a processor reset. Typically, some component of the system software will check for system integrity and strobe the timer hardware to indicate the system is "sane."
Although this approach enables recovery from a lockup related to a software or hardware glitch, it results in a complete system restart and perhaps significant "downtime" while this restart occurs.
When an intermittent software error occurs in a memory-protected system, the OS can catch the event and pass control to a user-written thread instead of the memory dump facilities. This thread can make an intelligent decision about how best to recover from the failure, instead of forcing a full reset as the hardware watchdog timer would do. The software watchdog could:
The important distinction here is that we retain intelligent, programmed control of the embedded system, even though various processes and threads within the control software may have failed for various reasons. A hardware watchdog timer is still of use to recover from hardware "latch-ups," but for software failures we now have much better control.
While performing some variation of these recovery strategies, the system can also collect information about the nature of the software failure. For example, if the embedded system contains or has access to some mass storage (Flash memory, hard drive, a network link to another computer with disk storage), the software watchdog can generate a chronologically archived sequence of dump files. These dump files could then be used for postmortem diagnostics.
Embedded control systems often employ these "partial restart" approaches to surviving intermittent software failures without the operators experiencing any system "downtime" or even being aware of these quick-recovery software failures. Since the dump files are available, the developers of the software can detect and correct software problems without having to deal with the emergencies that result when critical systems fail at inconvenient times. If we compare this to the hardware watchdog timer approach and the prolonged interruptions in service that result, it's obvious what our preference is!
Postmortem dump-file analysis is especially important for mission-critical embedded systems. Whenever a critical system fails in the field, significant effort should be made to identify the cause of the failure so that a "fix" can be engineered and applied to other systems before they experience similar failures.
Dump files give programmers the information they need to fix the problem -- without them, programmers may have little more to go on than a customer's cryptic complaint that "the system crashed."
By dividing embedded software into a team of cooperating, memory-protected processes (containing threads), we can readily treat these processes as "components" to be used again in new projects. Because of the explicitly defined (and hardware-enforced) interfaces, these processes can be integrated into applications with confidence that they won't disrupt the system's overall reliability. In addition, because the exact binary image (not just the source code) of the process is being reused, we can better control changes and instabilities that might have resulted from recompilation of source code, relinking, new versions of development tools, header files, library routines, etc.
Since the binary image of the process is reused (with its behavior perhaps modified by command-line options), the confidence we have in that binary module from acquired experience in the field more easily carries over to new applications than if the binary image of the process were changed.
As much as we strive to produce error-free code for the systems we deploy, the reality of software-intensive embedded systems is that programming errors will end up in released products. Rather than pretend these bugs don't exist (until the customer calls to report them), we should adopt a "mission-critical" mindset. Systems should be designed to be tolerant of, and able to recover from, software faults. Making use of the memory protection delivered by integrated MMUs in the embedded systems we build is a good step in that direction.
Our full-protection model relocates all code in the image into a new virtual space, enabling the MMU hardware and setting up the initial page-table mappings. This allows procnto to start in a correct, MMU-enabled environment. The process manager will then take over this environment, changing the mapping tables as needed by the processes it starts.
In the full-protection model, each process is given its own private virtual memory, which spans to 2 or 3.5 Gigabytes (depending on the CPU). This is accomplished by using the CPU's MMU. The performance cost for a process switch and a message pass will increase due to the increased complexity of obtaining addressability between two completely private address spaces.
|
Private memory space starts at 0 on x86, SH-4, ARM, and MIPS processors, but not on the PowerPC, where the space from 0 to 1G is reserved for system processes. |
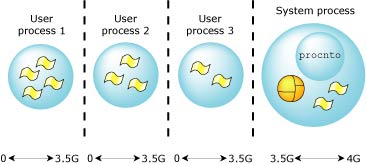
Full protection VM (on an x86).
The memory cost per process may increase by 4 KB to 8 KB for each process's page tables. Note that this memory model supports the POSIX fork() call.
I/O resources are not built into the microkernel, but are instead provided by resource manager processes that may be started dynamically at runtime. The procnto manager allows resource managers, through a standard API, to adopt a subset of the pathname space as a "domain of authority" to administer. As other resource managers adopt their respective domains of authority, procnto becomes responsible for maintaining a pathname tree to track the processes that own portions of the pathname space. An adopted pathname is sometimes referred to as a "prefix" because it prefixes any pathnames that lie beneath it. The adopted pathname is also called a mountpoint, because that's where a server mounts into the pathname.
This approach to pathname space management is what allows QNX Neutrino to preserve the POSIX semantics for device and file access, while making the presence of those services optional for small embedded systems.
At startup, procnto populates the pathname space with the following pathname prefixes:
| Prefix | Description |
|---|---|
| / | Root of the filesystem. |
| /proc/boot/ | Some of the files from the boot image presented as a flat filesystem. |
| /proc/ | The running processes, each represented by their process ID (PID). |
| /dev/zero | A device that always returns zero. Used for allocating zero-filled pages using the mmap() function. |
| /dev/mem | A device that represents all physical memory. |
When a process opens a file, the POSIX-compliant open() library routine first sends the pathname to procnto, where the pathname is compared against the prefix tree to determine which resource managers should be sent the open() message.
The prefix tree may contain identical or partially overlapping regions of authority -- multiple servers can register the same prefix. If the regions are identical, the order of resolution can be specified. If the regions are overlapping, the longest match wins. For example, suppose we have these prefixes registered:
| / | QNX 4 disk-based filesystem (fs-qnx4.so) |
| /dev/ser1 | Serial device manager (devc-ser*) |
| /dev/ser2 | Serial device manager (devc-ser*) |
| /dev/hd0 | Raw disk volume (devb-eide) |
The filesystem manager has registered a prefix for a mounted QNX 4 filesystem (i.e. /). The block device driver has registered a prefix for a block special file that represents an entire physical hard drive (i.e. /dev/hd0). The serial device manager has registered two prefixes for the two PC serial ports.
The following table illustrates the longest-match rule for pathname resolution:
| This pathname: | matches: | and resolves to: |
|---|---|---|
| /dev/ser1 | /dev/ser1 | devc-ser* |
| /dev/ser2 | /dev/ser2 | devc-ser* |
| /dev/ser | / | fs-qnx4.so |
| /dev/hd0 | /dev/hd0 | devb-eide.so |
| /usr/jhsmith/test | / | fs-qnx4.so |
Consider another example involving three servers:
At this point, the process manager's internal mount table would look like this:
| Mountpoint | Server |
|---|---|
| / | Server A (QNX 4 filesystem) |
| /bin | Server B (flash filesystem) |
| /dev/random | Server C (device) |
Of course, each "Server" name is actually an abbreviation for the nd,pid,chid for that particular server channel.
Now suppose a client wants to send a message to Server C. The client's code might look like this:
int fd;
fd = open("/dev/random", ...);
read(fd, ...);
close(fd);
In this case, the C library will ask the process manager for the servers that could potentially handle the path /dev/random. The process manager would return a list of servers:
From this information, the library will then contact each server in turn and send it an open message, including the component of the path that the server should validate:
As soon as one server positively acknowledges the request, the library won't contact the remaining servers. This means Server A is contacted only if Server C denies the request.
This process is fairly straightforward with single device entries, where the first server is generally the server that will handle the request. Where it becomes interesting is in the case of unioned filesystem mountpoints.
Let's assume we have two servers set up as before:
Note that each server has a /bin directory, but with different contents.
Once both servers are mounted, you would see the following due to the unioning of the mountpoints:
What's happening here is that the resolution for the path /bin takes place as before, but rather than limit the return to just one connection ID, all the servers are contacted and asked about their handling for the path:
DIR *dirp;
dirp = opendir("/bin", ...);
closedir(dirp);
which results in:
The result now is that we have a collection of file descriptors to servers who handle the path /bin (in this case two servers); the actual directory name entries are read in turn when a readdir() is called. If any of the names in the directory are accessed with a regular open, then the normal resolution procedure takes place and only one server is accessed.
This overlaying of mountpoints is a very handy feature when doing field updates, servicing, etc. It also makes for a more unified system, where pathnames result in connections to servers regardless of what services they're providing, thus resulting in a more unified API.
We've discussed prefixes that map to a resource manager. A second form of prefix, known as a symbolic prefix, is a simple string substitution for a matched prefix.
You create symbolic prefixes using the POSIX ln (link) command. This command is typically used to create hard or symbolic links on a filesystem by using the -s option. If you also specify the -P option, then a symbolic link is created in the in-memory prefix space of procnto.
| Command | Description |
|---|---|
| ln -s existing_file symbolic_link | Create a filesystem symbolic link. |
| ln -Ps existing_file symbolic_link | Create a prefix tree symbolic link. |
Note that a prefix tree symbolic link will always take precedence over a filesystem symbolic link.
For example, assume you're running on a machine that doesn't have a local filesystem. However, there's a filesystem on another node (say neutron) that you wish to access as "/bin". You accomplish this using the following symbolic prefix:
ln -Ps /net/neutron/bin /bin
This will cause /bin to be mapped into /net/neutron/bin. For example, /bin/ls will be replaced with the following:
/net/neutron/bin/ls
This new pathname will again be applied against the prefix tree, but this time the prefix matched will be /net, which will point to npm-qnet. The npm-qnet resource manager will then resolve the neutron component, and redirect further resolution requests to the node called neutron. On node neutron, the rest of the pathname (i.e. /bin/ls) will be resolved against the prefix space on that node. This will resolve to the filesystem manager on node neutron, where the open() request will be directed. With just a few characters, this symbolic prefix has allowed us to access a remote filesystem as though it were local.
It's not necessary to run a local filesystem process to perform the redirection. A diskless workstation's prefix tree might look something like this:
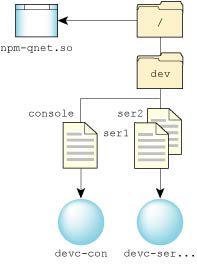
With this prefix tree, local devices such as /dev/ser1 or /dev/console will be routed to the local character device manager, while requests for other pathnames will be routed to the remote filesystem.
You can also use symbolic prefixes to create special device names. For example, if your modem was on /dev/ser1, you could create a symbolic prefix of /dev/modem as follows:
ln -Ps /dev/ser1 /dev/modem
Any request to open /dev/modem will be replaced with /dev/ser1. This mapping would allow the modem to be changed to a different serial port simply by changing the symbolic prefix and without affecting any applications.
Pathnames need not start with slash. In such cases, the path is considered relative to the current working directory. The OS maintains the current working directory as a character string. Relative pathnames are always converted to full network pathnames by prepending the current working directory string to the relative pathname.
Note that different behaviors result when your current working directory starts with a slash versus starting with a network root.
In some traditional UNIX systems, the cd (change directory) command modifies the pathname given to it if that pathname contains symbolic links. As a result, the pathname of the new current working directory -- which you can display with pwd -- may differ from the one given to cd.
In QNX Neutrino, however, cd doesn't modify the pathname -- aside from collapsing .. references. For example:
cd /usr/home/dan/test/../doc
would result in a current working directory of /usr/home/dan/doc, even if some of the elements in the pathname were symbolic links.
For more information about symbolic links and .. references, see "QNX 4 filesystem" in the Working with Filesystems chapter of the QNX Neutrino User's Guide.
Once an I/O resource has been opened, a different namespace comes into play. The open() returns an integer referred to as a file descriptor (FD), which is used to direct all further I/O requests to that resource manager.
Unlike the pathname space, the file descriptor namespace is completely local to each process. The resource manager uses the combination of a SCOID (server connection ID) and FD (file descriptor/connection ID) to identify the control structure associated with the previous open() call. This structure is referred to as an open control block (OCB) and is contained within the resource manager.
The following diagram shows an I/O manager taking some SCOID, FD pairs and mapping them to OCBs.
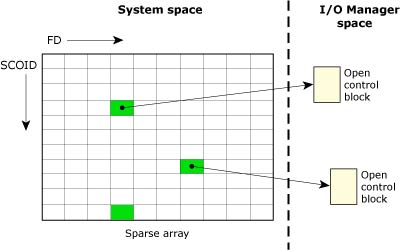
The SCOID and FD map to an OCB of an I/O Manager.
The open control block (OCB) contains active information about the open resource. For example, the filesystem keeps the current seek point within the file here. Each open() creates a new OCB. Therefore, if a process opens the same file twice, any calls to lseek() using one FD will not affect the seek point of the other FD. The same is true for different processes opening the same file.
The following diagram shows two processes, in which one opens the same file twice, and the other opens it once. There are no shared FDs.
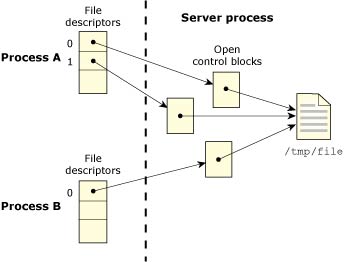
Two processes open the same file.
|
FDs are a process resource, not a thread resource. |
Several file descriptors in one or more processes can refer to the same OCB. This is accomplished by two means:
When several FDs refer to the same OCB, then any change in the state of the OCB is immediately seen by all processes that have file descriptors linked to the same OCB.
For example, if one process uses the lseek() function to change the position of the seek point, then reading or writing takes place from the new position no matter which linked file descriptor is used.
The following diagram shows two processes in which one opens a file twice, then does a dup() to get a third FD. The process then creates a child that inherits all open files.
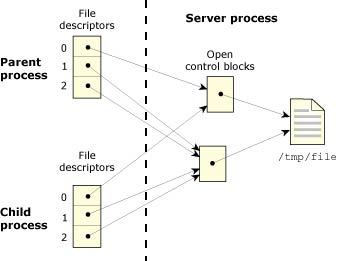
A process opens a file twice.
You can prevent a file descriptor from being inherited when you spawn() or exec*() by calling the fcntl() function and setting the FD_CLOEXEC flag.
|
|
|
|