This chapter includes:
In this chapter, we'll look at the most distinctive feature of Neutrino, message passing. Message passing lies at the heart of the operating system's microkernel architecture, giving the OS its modularity.
One of the principal advantages of Neutrino is that it's scalable. By “scalable” I mean that it can be tailored to work on tiny embedded boxes with tight memory constraints, right up to large networks of multiprocessor SMP boxes with almost unlimited memory.
Neutrino achieves its scalability by making each service-providing component modular. This way, you can include only the components you need in the final system. By using threads in the design, you'll also help to make it scalable to SMP systems (we'll see some more uses for threads in this chapter).
This is the philosophy that was used during the initial design of the QNX family of operating systems and has been carried through to this day. The key is a small microkernel architecture, with modules that would traditionally be incorporated into a monolithic kernel as optional components.
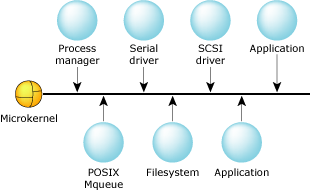
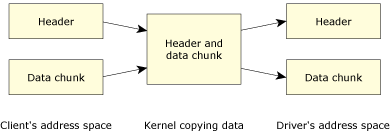
Neutrino's modular architecture.
You, the system architect, decide which modules you want. Do you need a filesystem in your project? If so, then add one. If you don't need one, then don't bother including one. Do you need a serial port driver? Whether the answer is yes or no, this doesn't affect (nor is it affected by) your previous decision about the filesystem.
At run time, you can decide which system components are included in the running system. You can dynamically remove components from a live system and reinstall them, or others, at some other time. Is there anything special about these “drivers”? Nope, they're just regular, user-level programs that happen to perform a specific job with the hardware. In fact, we'll see how to write them in the Resource Managers chapter.
The key to accomplishing this is message passing. Instead of having the OS modules bound directly into the kernel, and having some kind of “special” arrangement with the kernel, under Neutrino the modules communicate via message passing among themselves. The kernel is basically responsible only for thread-level services (e.g., scheduling). In fact, message passing isn't used just for this installation and deinstallation trick — it's the fundamental building block for almost all other services (for example, memory allocation is performed by a message to the process manager). Of course, some services are provided by direct kernel calls.
Consider opening a file and writing a block of data to it. This is accomplished by a number of messages sent from the application to an installable component of Neutrino called the filesystem. The message tells the filesystem to open a file, and then another message tells it to write some data (and contains that data). Don't worry though — the Neutrino operating system performs message passing very quickly.
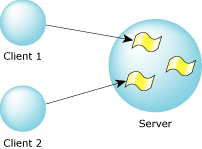
Imagine an application reading data from the filesystem. In QNX lingo, the application is a client requesting the data from a server.
This client/server model introduces several process states associated with message passing (we talked about these in the Processes and Threads chapter). Initially, the server is waiting for a message to arrive from somewhere. At this point, the server is said to be receive-blocked (also known as the RECEIVE state). Here's some sample pidin output:
pid tid name prio STATE Blocked
4 1 devc-pty 10r RECEIVE 1
In the above sample, the pseudo-tty server (called devc-pty) is process ID 4, has one thread (thread ID 1), is running at priority 10 Round-Robin, and is receive-blocked, waiting for a message from channel ID 1 (we'll see all about “channels” shortly).
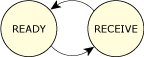
State transitions of server.
When a message is received, the server goes into the READY state, and is capable of running. If it happens to be the highest-priority READY process, it gets the CPU and can perform some processing. Since it's a server, it looks at the message it just got and decides what to do about it. At some point, the server will complete whatever job the message told it to do, and then will “reply” to the client.
Let's switch over to the client. Initially the client was running along, consuming CPU, until it decided to send a message. The client changed from READY to either send-blocked or reply-blocked, depending on the state of the server that it sent a message to.
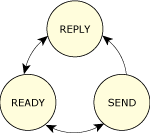
State transitions of clients.
Generally, you'll see the reply-blocked state much more often than the send-blocked state. That's because the reply-blocked state means:
The server has received the message and is now processing it. At some point, the server will complete processing and will reply to the client. The client is blocked waiting for this reply.
Contrast that with the send-blocked state:
The server hasn't yet received the message, most likely because it was busy handling another message first. When the server gets around to “receiving” your (client) message, then you'll go from the send-blocked state to the reply-blocked state.
In practice, if you see a process that is send-blocked it means one of two things:
This is a normal situation — you can verify it by running pidin again to get a new snapshot. This time you'll probably see that the process is no longer send-blocked.
When this happens, you'll see many processes that are send-blocked on one server. To verify this, run pidin again, observing that there's no change in the blocked state of the client processes.
Here's a sample showing a reply-blocked client and the server it's blocked on:
pid tid name prio STATE Blocked
1 1 to/x86/sys/procnto 0f READY
1 2 to/x86/sys/procnto 10r RECEIVE 1
1 3 to/x86/sys/procnto 10r NANOSLEEP
1 4 to/x86/sys/procnto 10r RUNNING
1 5 to/x86/sys/procnto 15r RECEIVE 1
16426 1 esh 10r REPLY 1
This shows that the program esh (the embedded shell) has sent a message to process number 1 (the kernel and process manager, procnto) and is now waiting for a reply.
Now you know the basics of message passing in a client/server architecture.
So now you might be thinking, “Do I have to write special Neutrino message-passing calls just to open a file or write some data?!?”
You don't have to write any message-passing functions, unless you want to get “under the hood” (which I'll talk about a little later). In fact, let me show you some client code that does message passing:
#include <fcntl.h>
#include <unistd.h>
int
main (void)
{
int fd;
fd = open ("filename", O_WRONLY);
write (fd, "This is message passing\n", 24);
close (fd);
return (EXIT_SUCCESS);
}
See? Standard C code, nothing tricky.
The message passing is done by the Neutrino C library. You simply issue standard POSIX 1003.1 or ANSI C function calls, and the C library does the message-passing work for you.
In the above example, we saw three functions being called and three distinct messages being sent:
We'll be discussing the messages themselves in a lot more detail when we look at resource managers (in the Resource Managers chapter), but for now all you need to know is the fact that different types of messages were sent.
Let's step back for a moment and contrast this to the way the example would have worked in a traditional operating system.
The client code would remain the same and the differences would be hidden by the C library provided by the vendor. On such a system, the open() function call would invoke a kernel function, which would then call directly into the filesystem, which would execute some code, and return a file descriptor. The write() and close() calls would do the same thing.
So? Is there an advantage to doing things this way? Keep reading!
Suppose we want to change our example above to talk to a different node on the network. You might think that we'll have to invoke special function calls to “get networked.” Here's the network version's code:
#include <fcntl.h>
#include <unistd.h>
int
main (void)
{
int fd;
fd = open ("/net/wintermute/home/rk/filename", O_WRONLY);
write (fd, "This is message passing\n", 24);
close (fd);
return (EXIT_SUCCESS);
}
You're right if you think the code is almost the same in both versions. It is.
In a traditional OS, the C library open() calls into the kernel, which looks at the filename and says “oops, this is on a different node.” The kernel then calls into the network filesystem (NFS) code, which figures out where /net/wintermute/home/rk/filename actually is. Then, NFS calls into the network driver and sends a message to the kernel on node wintermute, which then repeats the process that we described in our original example. Note that in this case, there are really two filesystems involved; one is the NFS client filesystem, and one is the remote filesystem. Unfortunately, depending on the implementation of the remote filesystem and NFS, certain operations may not work as expected (e.g., file locking) due to incompatibilities.
Under Neutrino, the C library open() creates the same message that it would have sent to the local filesystem and sends it to the filesystem on node wintermute. In the local and remote cases, the exact same filesystem is used.
This is another fundamental characteristic of Neutrino: network-distributed operations are essentially “free,” as the work to decouple the functionality requirements of the clients from the services provided by the servers is already done, by virtue of message passing.
On a traditional kernel there's a “double standard” where local services are implemented one way, and remote (network) services are implemented in a totally different way.
Message passing is elegant and network-distributed. So what? What does it buy you, the programmer?
Well, it means that your programs inherit those characteristics — they too can become network-distributed with far less work than on other systems. But the benefit that I find most useful is that they let you test software in a nice, modular manner.
You've probably worked on large projects where many people have to provide different pieces of the software. Of course, some of these people are done sooner or later than others.
These projects often have problems at two stages: initially at project definition time, when it's hard to decide where one person's development effort ends and another's begins, and then at testing/integration time, when it isn't possible to do full systems integration testing because all the pieces aren't available.
With message passing, the individual components of a project can be decoupled very easily, leading to a very simple design and reasonably simple testing. If you want to think about this in terms of existing paradigms, it's very similar to the concepts used in Object Oriented Programming (OOP).
What this boils down to is that testing can be performed on a piece-by-piece basis. You can set up a simple program that sends messages to your server process, and since the inputs and outputs of that server process are (or should be!) well documented, you can determine if that process is functioning. Heck, these test cases can even be automated and placed in a regression suite that runs periodically!
Message passing is at the heart of the philosophy of Neutrino. Understanding the uses and implications of message passing will be the key to making effective use of the OS. Before we go into the details, let's look at a little bit of theory first.
Although the client/server model is easy to understand, and the most commonly used, there are two other variations on the theme. The first is the use of multiple threads (the topic of this section), and the second is a model called server/subserver that's sometimes useful for general design, but really shines in network-distributed designs. The combination of the two can be extremely powerful, especially on a network of SMP boxes!
As we discussed in the Processes and Threads chapter, Neutrino has the ability to run multiple threads of execution in the same process. How can we use this to our advantage when we combine this with message passing?
The answer is fairly simple. We can start a pool of threads (using the thread_pool_*() functions that we talked about in the Processes and Threads chapter), each of which can handle a message from a client:
Clients accessing threads in a server.
This way, when a client sends us a message, we really don't care which thread gets it, as long as the work gets done. This has a number of advantages. The ability to service multiple clients with multiple threads, versus servicing multiple clients with just one thread, is a powerful concept. The main advantage is that the kernel can multitask the server among the various clients, without the server itself having to perform the multitasking.
On a single-processor machine, having a bunch of threads running means that they're all competing with each other for CPU time.
But, on an SMP box, we can have multiple threads competing for multiple CPUs, while sharing the same data area across those multiple CPUs. This means that we're limited only by the number of available CPUs on that particular machine.
Let's now look at the server/subserver model, and then we'll combine it with the multiple threads model.
In this model, a server still provides a service to clients, but because these requests may take a long time to complete, we need to be able to start a request and still be able to handle new requests as they arrive from other clients.
If we tried to do this with the traditional single-threaded client/server model, once one request was received and started, we wouldn't be able to receive any more requests unless we periodically stopped what we were doing, took a quick peek to see if there were any other requests pending, put those on a work queue, and then continued on, distributing our attention over the various jobs in the work queue. Not very efficient. You're practically duplicating the work of the kernel by “time slicing” between multiple jobs!
Imagine what this would look like if you were doing it. You're at your desk, and someone walks up to you with a folder full of work. You start working on it. As you're busy working, you notice that someone else is standing in the doorway of your cubicle with more work of equally high priority (of course)! Now you've got two piles of work on your desk. You're spending a few minutes on one pile, switching over to the other pile, and so on, all the while looking at your doorway to see if someone else is coming around with even more work.
The server/subserver model would make a lot more sense here. In this model, we have a server that creates several other processes (the subservers). These subservers each send a message to the server, but the server doesn't reply to them until it gets a request from a client. Then it passes the client's request to one of the subservers by replying to it with the job that it should perform. The following diagram illustrates this. Note the direction of the arrows — they indicate the direction of the sends!
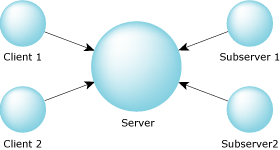
Server/subserver model.
If you were doing a job like this, you'd start by hiring some extra employees. These employees would all come to you (just as the subservers send a message to the server — hence the note about the arrows in the diagram above), looking for work to do. Initially, you might not have any, so you wouldn't reply to their query. When someone comes into your office with a folder full of work, you say to one of your employees, “Here's some work for you to do.” That employee then goes off and does the work. As other jobs come in, you'd delegate them to the other employees.
The trick to this model is that it's reply-driven — the work starts when you reply to your subservers. The standard client/server model is send-driven because the work starts when you send the server a message.
So why would the clients march into your office, and not the offices of the employees that you hired? Why are you “arbitrating” the work? The answer is fairly simple: you're the coordinator responsible for performing a particular task. It's up to you to ensure that the work is done. The clients that come to you with their work know you, but they don't know the names or locations of your (perhaps temporary) employees.
As you probably suspected, you can certainly mix multithreaded servers with the server/subserver model. The main trick is going to be determining which parts of the “problem” are best suited to being distributed over a network (generally those parts that won't use up the network bandwidth too much) and which parts are best suited to being distributed over the SMP architecture (generally those parts that want to use common data areas).
So why would we use one over the other? Using the server/subserver approach, we can distribute the work over multiple machines on a network. This effectively means that we're limited only by the number of available machines on the network (and network bandwidth, of course). Combining this with multiple threads on a bunch of SMP boxes distributed over a network yields “clusters of computing,” where the central “arbitrator” delegates work (via the server/subserver model) to the SMP boxes on the network.
Now we'll consider a few examples of each method.
Filesystems, serial ports, consoles, and sound cards all use the client/server model. A C language application program takes on the role of the client and sends requests to these servers. The servers perform whatever work was specified, and reply with the answer.
Some of these traditional “client/server” servers may in fact actually be reply-driven (server/subserver) servers! This is because, to the ultimate client, they appear as a standard server, even though the server itself uses server/subserver methods to get the work done. What I mean by that is, the client still sends a message to what it thinks is the “service providing process.” What actually happens is that the “service providing process” simply delegates the client's work to a different process (the subserver).
One of the more popular reply-driven programs is a fractal graphics program distributed over the network. The master program divides the screen into several areas, for example, 64 regions. At startup, the master program is given a list of nodes that can participate in this activity. The master program starts up worker (subserver) programs, one on each of the nodes, and then waits for the worker programs to send to the master.
The master then repeatedly picks “unfilled” regions (of the 64 on screen) and delegates the fractal computation work to the worker program on another node by replying to it. When the worker program has completed the calculations, it sends the results back to the master, which displays the result on the screen.
Because the worker program sent to the master, it's now up to the master to again reply with more work. The master continues doing this until all 64 areas on the screen have been filled.
Because the master program is delegating work to worker programs, the master program can't afford to become blocked on any one program! In a traditional send-driven approach, you'd expect the master to create a program and then send to it. Unfortunately, the master program wouldn't be replied to until the worker program was done, meaning that the master program couldn't send simultaneously to another worker program, effectively negating the advantages of having multiple worker nodes.
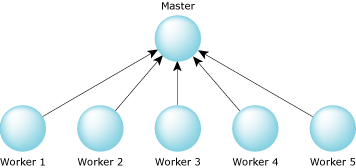
One master, multiple workers.
The solution to this problem is to have the worker programs start up, and ask the master program if there's any work to do by sending it a message. Once again, we've used the direction of the arrows in the diagram to indicate the direction of the send. Now the worker programs are waiting for the master to reply. When something tells the master program to do some work, it replies to one or more of the workers, which causes them to go off and do the work. This lets the workers go about their business; the master program can still respond to new requests (it's not blocked waiting for a reply from one of the workers).
Multi-threaded servers are indistinguishable from single-threaded servers from the client's point of view. In fact, the designer of a server can just “turn on” multi-threading by starting another thread.
In any event, the server can still make use of multiple CPUs in an SMP configuration, even if it is servicing only one “client.” What does that mean? Let's revisit the fractal graphics example. When a subserver gets a request from the server to “compute,” there's absolutely nothing stopping the subserver from starting up multiple threads on multiple CPUs to service the one request. In fact, to make the application scale better across networks that have some SMP boxes and some single-CPU boxes, the server and subserver can initially exchange a message whereby the subserver tells the server how many CPUs it has — this lets it know how many requests it can service simultaneously. The server would then queue up more requests for SMP boxes, allowing the SMP boxes to do more work than single-CPU boxes.
Now that we've seen the basic concepts involved in message passing, and learned that even common everyday things like the C library use it, let's take a look at some of the details.
We've been talking about “clients” and “servers.” I've also used three key phrases:
I specifically used those phrases because they closely reflect the actual function names used in Neutrino message-passing operations.
Here's the complete list of functions dealing with message passing available under Neutrino (in alphabetical order):
Don't let this list overwhelm you! You can write perfectly useful client/server applications using just a small subset of the calls from the list — as you get used to the ideas, you'll see that some of the other functions can be very useful in certain cases.
 |
A useful minimal set of functions is ChannelCreate(), ConnectAttach(), MsgReply(), MsgSend(), and MsgReceive(). |
We'll break our discussion up into the functions that apply on the client side, and those that apply on the server side.
The client wants to send a request to a server, block until the server has completed the request, and then when the request is completed and the client is unblocked, to get at the “answer.”
This implies two things: the client needs to be able to establish a connection to the server and then to transfer data via messages — a message from the client to the server (the “send” message) and a message back from the server to the client (the “reply” message, the server's reply).
So, let's look at these functions in turn. The first thing we need to do is to establish a connection. We do this with the function ConnectAttach(), which looks like this:
#include <sys/neutrino.h>
int ConnectAttach (int nd,
pid_t pid,
int chid,
unsigned index,
int flags);
ConnectAttach() is given three identifiers: the nd, which is the Node Descriptor, the pid, which is the process ID, and the chid, which is the channel ID. These three IDs, commonly referred to as “ND/PID/CHID,” uniquely identify the server that the client wants to connect to. We'll ignore the index and flags (just set them to 0).
So, let's assume that we want to connect to process ID 77, channel ID 1 on our node. Here's the code sample to do that:
int coid; coid = ConnectAttach (0, 77, 1, 0, 0);
As you can see, by specifying a nd of zero, we're telling the kernel that we wish to make a connection on our node.
|
How did I figure out I wanted to talk to process ID 77 and channel ID 1? We'll see that shortly (see “Finding the server's ND/PID/CHID,” below). |
At this point, I have a connection ID — a small integer that uniquely identifies a connection from my client to a specific channel on a particular server.
I can use this connection ID when sending to the server as many times as I like. When I'm done with it, I can destroy it via:
ConnectDetach (coid);
So let's see how I actually use it.
Message passing on the client is achieved using some variant of the MsgSend*() function family. We'll look at the simplest member, MsgSend():
#include <sys/neutrino.h>
int MsgSend (int coid,
const void *smsg,
int sbytes,
void *rmsg,
int rbytes);
MsgSend()'s arguments are:
It couldn't get any simpler than that!
Let's send a simple message to process ID 77, channel ID 1:
#include <sys/neutrino.h>
char *smsg = "This is the outgoing buffer";
char rmsg [200];
int coid;
// establish a connection
coid = ConnectAttach (0, 77, 1, 0, 0);
if (coid == -1) {
fprintf (stderr, "Couldn't ConnectAttach to 0/77/1!\n");
perror (NULL);
exit (EXIT_FAILURE);
}
// send the message
if (MsgSend (coid,
smsg,
strlen (smsg) + 1,
rmsg,
sizeof (rmsg)) == -1) {
fprintf (stderr, "Error during MsgSend\n");
perror (NULL);
exit (EXIT_FAILURE);
}
if (strlen (rmsg) > 0) {
printf ("Process ID 77 returns \"%s\"\n", rmsg);
}
Let's assume that process ID 77 was an active server expecting that particular format of message on its channel ID 1. After the server received the message, it would process it and at some point reply with a result. At that point, the MsgSend() would return a 0 indicating that everything went well. If the server sends us any data in the reply, we'd print it with the last line of code (we're assuming we're getting NUL-terminated ASCII data back).
Now that we've seen the client, let's look at the server. The client used ConnectAttach() to create a connection to a server, and then used MsgSend() for all its message passing.
This implies that the server has to create a channel — this is the thing that the client connected to when it issued the ConnectAttach() function call. Once the channel has been created, the server usually leaves it up forever.
The channel gets created via the ChannelCreate() function, and destroyed via the ChannelDestroy() function:
#include <sys/neutrino.h> int ChannelCreate (unsigned flags); int ChannelDestroy (int chid);
We'll come back to the flags argument later (in the “Channel flags” section, below). For now, let's just use a 0. Therefore, to create a channel, the server issues:
int chid; chid = ChannelCreate (0);
So we have a channel. At this point, clients could connect (via ConnectAttach()) to this channel and start sending messages:
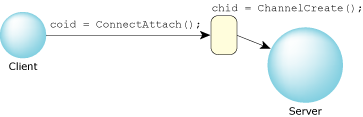
Relationship between a server channel and a client connection.
As far as the message-passing aspects are concerned, the server handles message passing in two stages; a “receive” stage and a “reply” stage:
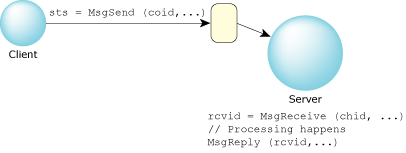
Relationship of client and server message-passing functions.
We'll look initially at two simple versions of these functions, MsgReceive() and MsgReply(), and then later see some of the variants.
#include <sys/neutrino.h>
int MsgReceive (int chid,
void *rmsg,
int rbytes,
struct _msg_info *info);
int MsgReply (int rcvid,
int status,
const void *msg,
int nbytes);
Let's look at how the parameters relate:
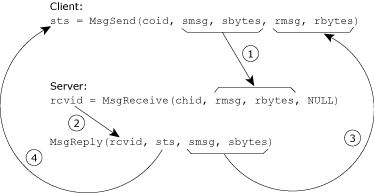
Message data flow.
As you can see from the diagram, there are four things we need to talk about:
You may have noticed that there are two sizes for every buffer transfer (in the client send case, there's sbytes on the client side and rbytes on the server side; in the server reply case, there's sbytes on the server side and rbytes on the client side.) The two sets of sizes are present so that the programmers of each component can specify the sizes of their buffers. This is done for added safety.
In our example, the MsgSend() buffer's size was the same as the message string's length. Let's look at the server and see how the size is used there.
Here's the overall structure of a server:
#include <sys/neutrino.h>
…
void
server (void)
{
int rcvid; // indicates who we should reply to
int chid; // the channel ID
char message [512]; // big enough for our purposes
// create a channel
chid = ChannelCreate (0);
// this is typical of a server: it runs forever
while (1) {
// get the message, and print it
rcvid = MsgReceive (chid, message, sizeof (message),
NULL);
printf ("Got a message, rcvid is %X\n", rcvid);
printf ("Message was \"%s\".\n", message);
// now, prepare the reply. We reuse "message"
strcpy (message, "This is the reply");
MsgReply (rcvid, EOK, message, sizeof (message));
}
}
As you can see, MsgReceive() tells the kernel that it can handle messages up to sizeof (message) (or 512 bytes). Our sample client (above) sent only 28 bytes (the length of the string). The following diagram illustrates:
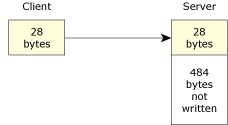
Transferring less data than expected.
The kernel transfers the minimum specified by both sizes. In our case, the kernel would transfer 28 bytes. The server would be unblocked and print out the client's message. The remaining 484 bytes (of the 512 byte buffer) will remain unaffected.
We run into the same situation again with MsgReply(). The MsgReply() function says that it wants to transfer 512 bytes, but our client's MsgSend() function has specified that a maximum of 200 bytes can be transferred. So the kernel once again transfers the minimum. In this case, the 200 bytes that the client can accept limits the transfer size. (One interesting aspect here is that once the server transfers the data, if the client doesn't receive all of it, as in our example, there's no way to get the data back — it's gone forever.)
|
Keep in mind that this “trimming” operation is normal and expected behavior. When we discuss message passing over a network, you'll see that there's a tiny “gotcha” with the amount of data transferred. We'll see this in “Networked message-passing differences,” below. |
One thing that's perhaps not obvious in a message-passing environment is the need to follow a strict send-hierarchy. What this means is that two threads should never send messages to each other; rather, they should be organized such that each thread occupies a “level”; all sends go from one level to a higher level, never to the same or lower level. The problem with having two threads send messages to each other is that eventually you'll run into the problem of deadlock — both threads are waiting for each other to reply to their respective messages. Since the threads are blocked, they'll never get a chance to run and perform the reply, so you end up with two (or more!) hung threads.
The way to assign the levels to the threads is to put the outermost clients at the highest level, and work down from there. For example, if you have a graphical user interface that relies on some database server, and the database server in turn relies on the filesystem, and the filesystem in turn relies on a block filesystem driver, then you've got a natural hierarchy of different processes. The sends will flow from the outermost client (the graphical user interface) down to the lower servers; the replies will flow in the opposite direction.
While this certainly works in the majority of cases, you will encounter situations where you need to “break” the send hierarchy. This is never done by simply violating the send hierarchy and sending a message “against the flow,” but rather by using the MsgDeliverEvent() function, which we'll take a look at later.
We haven't talked about the various parameters in the examples above so that we could focus just on the message passing. Now let's take a look.
In the server example above, we saw that the server created just one channel. It could certainly have created more, but generally, servers don't do that. (The most obvious example of a server with two channels is the Transparent Distributed Processing (TDP, also known as Qnet) native network manager — definitely an “odd” piece of software!)
As it turns out, there really isn't much need to create multiple channels in the real world. The main purpose of a channel is to give the server a well-defined place to “listen” for messages, and to give the clients a well-defined place to send their messages (via a connection). About the only time that you'd have multiple channels in a server is if the server wanted to provide either different services, or different classes of services, depending on which channel the message arrived on. The second channel could be used, for example, as a place to drop wake up pulses — this ensures that they're treated as a different “class” of service than messages arriving on the first channel.
In a previous paragraph I had said that you could have a pool of threads running in a server, ready to accept messages from clients, and that it didn't really matter which thread got the request. This is another aspect of the channel abstraction. Under previous versions of the QNX family of operating systems (notably QNX 4), a client would target messages at a server identified by a node ID and process ID. Since QNX 4 is single-threaded, this means that there cannot be confusion about “to whom” the message is being sent. However, once you introduce threads into the picture, the design decision had to be made as to how you would address the threads (really, the “service providers”). Since threads are ephemeral, it really didn't make sense to have the client connect to a particular node ID, process ID, and thread ID. Also, what if that particular thread was busy? We'd have to provide some method to allow a client to select a “non-busy thread within a defined pool of service-providing threads.”
Well, that's exactly what a channel is. It's the “address” of a “pool of service-providing threads.” The implication here is that a bunch of threads can issue a MsgReceive() function call on a particular channel, and block, with only one thread getting a message at a time.
Often a server will need to know who sent it a message. There are a number of reasons for this:
It would be cumbersome (and a security hole) to have the client provide this information with each and every message sent. Therefore, there's a structure filled in by the kernel whenever the MsgReceive() function unblocks because it got a message. This structure is of type struct _msg_info, and contains the following:
struct _msg_info
{
int nd;
int srcnd;
pid_t pid;
int32_t chid;
int32_t scoid;
int32_t coid;
int32_t msglen;
int32_t tid;
int16_t priority;
int16_t flags;
int32_t srcmsglen;
int32_t dstmsglen;
};
You pass it to the MsgReceive() function as the last argument. If you pass a NULL, then nothing happens. (The information can be retrieved later via the MsgInfo() call, so it's not gone forever!)
Let's look at the fields:
In the code sample above, notice how we:
rcvid = MsgReceive (…); … MsgReply (rcvid, …);
This is a key snippet of code, because it illustrates the binding between receiving a message from a client, and then being able to (sometime later) reply to that particular client. The receive ID is an integer that acts as a “magic cookie” that you'll need to hold onto if you want to interact with the client later. What if you lose it? It's gone. The client will not unblock from the MsgSend() until you (the server) die, or if the client has a timeout on the message-passing call (and even then it's tricky; see the TimerTimeout() function in the Neutrino Library Reference, and the discussion about its use in the Clocks, Timers, and Getting A Kick Every So Often chapter, under “Kernel timeouts”).
|
Don't depend on the value of the receive ID
to have any particular meaning — it may change
in future versions of the operating system. You can
assume that it will be unique, in that you'll never
have two outstanding clients identified by the same
receive IDs (in that case, the kernel couldn't tell them
apart either when you do the MsgReply()).
Also, note that except in one special case (the MsgDeliverEvent() function which we'll look at later), once you've done the MsgReply(), that particular receive ID ceases to have meaning. |
This brings us to the MsgReply() function.
MsgReply() accepts a receive ID, a status, a message pointer, and a message size. We've just finished discussing the receive ID; it identifies who the reply message should be sent to. The status variable indicates the return status that should be passed to the client's MsgSend() function. Finally, the message pointer and size indicate the location and size of the optional reply message that should be sent.
The MsgReply() function may appear to be very simple (and it is), but its applications require some examination.
There's absolutely no requirement that you reply to a client before accepting new messages from other clients via MsgReceive()! This can be used in a number of different scenarios.
In a typical device driver, a client may make a request that won't be serviced for a long time. For example, the client may ask an Analog-to-Digital Converter (ADC) device driver to “Go out and collect 45 seconds worth of samples.” In the meantime, the ADC driver shouldn't just close up shop for 45 seconds! Other clients might wish to have requests serviced (for example, there might be multiple analog channels, or there might be status information that should be available immediately, etc.).
Architecturally, the ADC driver will simply queue the receive ID that it got from the MsgReceive(), start up the 45-second accumulation process, and go off and handle other requests. When the 45 seconds are up and the samples have been accumulated, the ADC driver can find the receive ID associated with the request and then reply to the client.
You'd also want to hold off replying to a client in the case of the reply-driven server/subserver model (where some of the “clients” are the subservers). Since the subservers are looking for work, you'd simply make a note of their receive IDs and store those away. When actual work arrived, then and only then would you reply to the subserver, thus indicating that it should do some work.
When you finally reply to the client, there's no requirement that you transfer any data. This is used in two scenarios.
You may choose to reply with no data if the sole purpose of the reply is to unblock the client. Let's say the client just wants to be blocked until some particular event occurs, but it doesn't need to know which event. In this case, no data is required by the MsgReply() function; the receive ID is sufficient:
MsgReply (rcvid, EOK, NULL, 0);
This unblocks the client (but doesn't return any data) and returns the EOK “success” indication.
As a slight modification of that, you may wish to return an error status to the client. In this case, you can't do that with MsgReply(), but instead must use MsgError():
MsgError (rcvid, EROFS);
In the above example, the server detects that the client is attempting to write to a read-only filesystem, and, instead of returning any actual data, simply returns an errno of EROFS back to the client.
Alternatively (and we'll look at the calls shortly), you may have already transferred the data (via MsgWrite()), and there's no additional data to transfer.
Why the two calls? They're subtly different. While both MsgError() and MsgReply() will unblock the client, MsgError() will not transfer any additional data, will cause the client's MsgSend() function to return -1, and will cause the client to have errno set to whatever was passed as the second argument to MsgError().
On the other hand, MsgReply() could transfer data (as indicated by the third and fourth arguments), and will cause the client's MsgSend() function to return whatever was passed as the second argument to MsgReply(). MsgReply() has no effect on the client's errno.
Generally, if you're returning only a pass/fail indication (and no data), you'd use MsgError(), whereas if you're returning data, you'd use MsgReply(). Traditionally, when you do return data, the second argument to MsgReply() will be a positive integer indicating the number of bytes being returned.
You've noticed that in the ConnectAttach() function, we require a Node Descriptor (ND), a process ID (PID), and a channel ID (CHID) in order to be able to attach to a server. So far we haven't talked about how the client finds this ND/PID/CHID information.
If one process creates the other, then it's easy — the process creation call returns with the process ID of the newly created process. Either the creating process can pass its own PID and CHID on the command line to the newly created process or the newly created process can issue the getppid() function call to get the PID of its parent and assume a “well-known” CHID.
What if we have two perfect strangers? This would be the case if, for example, a third party created a server and an application that you wrote wanted to talk to that server. The real issue is, “How does a server advertise its location?”
There are many ways of doing this; we'll look at four of them, in increasing order of programming “elegance”:
The first approach is very simple, but can suffer from “pathname pollution,” where the /etc directory has all kinds of *.pid files in it. Since files are persistent (meaning they survive after the creating process dies and the machine reboots), there's no obvious method of cleaning up these files, except perhaps to have a “grim reaper” task that runs around seeing if these things are still valid.
There's another related problem. Since the process that created the file can die without removing the file, there's no way of knowing whether or not the process is still alive until you try to send a message to it. Worse yet, the ND/PID/CHID specified in the file may be so stale that it would have been reused by another program! The message that you send to that program will at best be rejected, and at worst may cause damage. So that approach is out.
The second approach, where we use global variables to advertise the ND/PID/CHID values, is not a general solution, as it relies on the client's being able to access the global variables. And since this requires shared memory, it certainly won't work across a network! This generally gets used in either tiny test case programs or in very special cases, but always in the context of a multithreaded program. Effectively, all that happens is that one thread in the program is the client, and another thread is the server. The server thread creates the channel and then places the channel ID into a global variable (the node ID and process ID are the same for all threads in the process, so they don't need to be advertised.) The client thread then picks up the global channel ID and performs the ConnectAttach() to it.
The third approach, where we use the name_attach() and name_detach() functions, works well for simple client/server situations.
The last approach, where the server becomes a resource manager, is definitely the cleanest and is the recommended general-purpose solution. The mechanics of “how” will become clear in the Resource Managers chapter, but for now, all you need to know is that the server registers a particular pathname as its “domain of authority,” and a client performs a simple open() of that pathname.
|
I can't emphasize this enough:
POSIX file descriptors are implemented using connection IDs; that is, a file descriptor is a connection ID! The beauty of this scheme is that since the file descriptor that's returned from the open() is the connection ID, no further work is required on the client's end to be able to use that particular connection. For example, when the client calls read() later, passing it the file descriptor, this translates with very little overhead into a MsgSend() function. |
What if a low-priority process and a high-priority process send a message to a server at the same time?
|
Messages are always delivered in priority order.
If two processes send a message “simultaneously,” the entire message from the higher-priority process is delivered to the server first. If both processes are at the same priority, then the messages will be delivered in time order (since there's no such thing as absolutely simultaneous on a single-processor machine — even on an SMP box there will be some ordering as the CPUs arbitrate kernel access among themselves). |
We'll come back to some of the other subtleties introduced by this question when we look at priority inversions later in this chapter.
So far you've seen the basic message-passing primitives. As I mentioned earlier, these are all that you need. However, there are a few extra functions that make life much easier.
Let's consider an example using a client and server where we might need other functions.
The client issues a MsgSend() to transfer some data to the server. After the client issues the MsgSend() it blocks; it's now waiting for the server to reply.
An interesting thing happens on the server side. The server has called MsgReceive() to receive the message from the client. Depending on the design that you choose for your messages, the server may or may not know how big the client's message is. Why on earth would the server not know how big the message is? Consider the filesystem example that we've been using. Suppose the client does:
write (fd, buf, 16);
This works as expected if the server does a MsgReceive() and specifies a buffer size of, say, 1024 bytes. Since our client sent only a tiny message (28 bytes), we have no problems.
However, what if the client sends something bigger than 1024 bytes, say 1 megabyte?
write (fd, buf, 1000000);
How is the server going to gracefully handle this? We could, arbitrarily, say that the client isn't allowed to write more than n bytes. Then, in the client-side C library code for write(), we could look at this requirement and split up the write request into several requests of n bytes each. This is awkward.
The other problem with this example would be, “How big should n be?”
You can see that this approach has major disadvantages:
Luckily, this problem has a fairly simple workaround that also gives us some advantages.
Two functions, MsgRead() and MsgWrite(), are especially useful here. The important fact to keep in mind is that the client is blocked. This means that the client isn't going to go and change data structures while the server is trying to examine them.
|
In a multi-threaded client, the potential exists for another thread to mess around with the data area of a client thread that's blocked on a server. This is considered a bug (bad design) — the server thread assumes that it has exclusive access to a client's data area until the server thread unblocks the client. |
The MsgRead() function looks like this:
#include <sys/neutrino.h>
int MsgRead (int rcvid,
void *msg,
int nbytes,
int offset);
MsgRead() lets your server read data from the blocked client's address space, starting offset bytes from the beginning of the client-specified “send” buffer, into the buffer specified by msg for nbytes. The server doesn't block, and the client doesn't unblock. MsgRead() returns the number of bytes it actually read, or -1 if there was an error.
So let's think about how we'd use this in our write() example. The C Library write() function constructs a message with a header that it sends to the filesystem server, fs-qnx4. The server receives a small portion of the message via MsgReceive(), looks at it, and decides where it's going to put the rest of the message. The fs-qnx4 server may decide that the best place to put the data is into some cache buffers it's already allocated.
Let's track an example:
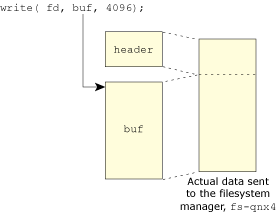
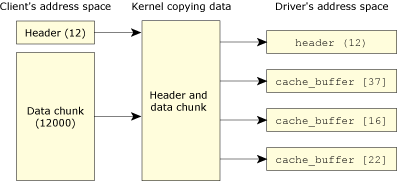
The fs-qnx4 message example, showing contiguous data view.
So, the client has decided to send 4 KB to the filesystem. (Notice how the C Library stuck a tiny header in front of the data so that the filesystem could tell just what kind of request it actually was — we'll come back to this when we look at multi-part messages, and in even more detail when we look at resource managers.) The filesystem reads just enough data (the header) to figure out what kind of a message it is:
// part of the headers, fictionalized for example purposes
struct _io_write {
uint16_t type;
uint16_t combine_len;
int32_t nbytes;
uint32_t xtype;
};
typedef union {
uint16_t type;
struct _io_read io_read;
struct _io_write io_write;
…
} header_t;
header_t header; // declare the header
rcvid = MsgReceive (chid, &header, sizeof (header), NULL);
switch (header.type) {
…
case _IO_WRITE:
number_of_bytes = header.io_write.nbytes;
…
At this point, fs-qnx4 knows that 4 KB are sitting in the client's address space (because the message told it in the nbytes member of the structure) and that it should be transferred to a cache buffer. The fs-qnx4 server could issue:
MsgRead (rcvid, cache_buffer [index].data,
cache_buffer [index].size, sizeof (header.io_write));
Notice that the message transfer has specified an offset of sizeof (header.io_write) in order to skip the write header that was added by the client's C library. We're assuming here that cache_buffer [index].size is actually 4096 (or more) bytes.
Similarly, for writing data to the client's address space, we have:
#include <sys/neutrino.h>
int MsgWrite (int rcvid,
const void *msg,
int nbytes,
int offset);
MsgWrite() lets your server write data to the client's address space, starting offset bytes from the beginning of the client-specified “receive” buffer. This function is most useful in cases where the server has limited space but the client wishes to get a lot of information from the server.
For example, with a data acquisition driver, the client may specify a 4-megabyte data area and tell the driver to grab 4 megabytes of data. The driver really shouldn't need to have a big area like this lying around just in case someone asks for a huge data transfer.
The driver might have a 128 KB area for DMA data transfers, and then message-pass it piecemeal into the client's address space using MsgWrite() (incrementing the offset by 128 KB each time, of course). Then, when the last piece of data has been written, the driver will MsgReply() to the client.
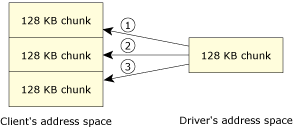
Transferring several chunks with MsgWrite().
Note that MsgWrite() lets you write the data components at various places, and then either just wake up the client using MsgReply():
MsgReply (rcvid, EOK, NULL, 0);
or wake up the client after writing a header at the start of the client's buffer:
MsgReply (rcvid, EOK, &header, sizeof (header));
This is a fairly elegant trick for writing unknown quantities of data, where you know how much data you wrote only when you're done writing it. If you're using this method of writing the header after the data's been transferred, you must remember to leave room for the header at the beginning of the client's data area!
Until now, we've shown only message transfers happening from one buffer in the client's address space into another buffer in the server's address space. (And one buffer in the server's space into another buffer in the client's space during the reply.)
While this approach is good enough for most applications, it can lead to inefficiencies. Recall that our write() C library code took the buffer that you passed to it, and stuck a small header on the front of it. Using what we've learned so far, you'd expect that the C library would implement write() something like this (this isn't the real source):
ssize_t write (int fd, const void *buf, size_t nbytes)
{
char *newbuf;
io_write_t *wptr;
int nwritten;
newbuf = malloc (nbytes + sizeof (io_write_t));
// fill in the write_header at the beginning
wptr = (io_write_t *) newbuf;
wptr -> type = _IO_WRITE;
wptr -> nbytes = nbytes;
// store the actual data from the client
memcpy (newbuf + sizeof (io_write_t), buf, nbytes);
// send the message to the server
nwritten = MsgSend (fd,
newbuf,
nbytes + sizeof (io_write_t),
newbuf,
sizeof (io_write_t));
free (newbuf);
return (nwritten);
}
See what happened? A few bad things:
Since the kernel is going to copy the data anyway, it would be nice if we could tell it that one part of the data (the header) is located at a certain address, and that the other part (the data itself) is located somewhere else, without the need for us to manually assemble the buffers and to copy the data.
As luck would have it, Neutrino implements a mechanism that lets us do just that! The mechanism is something called an IOV, standing for “Input/Output Vector.”
Let's look at some code first, then we'll discuss what happens:
#include <sys/neutrino.h>
ssize_t write (int fd, const void *buf, size_t nbytes)
{
io_write_t whdr;
iov_t iov [2];
// set up the IOV to point to both parts:
SETIOV (iov + 0, &whdr, sizeof (whdr));
SETIOV (iov + 1, buf, nbytes);
// fill in the io_write_t at the beginning
whdr.type = _IO_WRITE;
whdr.nbytes = nbytes;
// send the message to the server
return (MsgSendv (coid, iov, 2, iov, 1));
}
First of all, notice there's no malloc() and no memcpy(). Next, notice the use of the iov_t type. This is a structure that contains an address and length pair, and we've allocated two of them (named iov).
The iov_t type definition is automatically included by <sys/neutrino.h>, and is defined as:
typedef struct iovec
{
void *iov_base;
size_t iov_len;
} iov_t;
Given this structure, we fill the address and length pairs with the write header (for the first part) and the data from the client (in the second part). There's a convenience macro called SETIOV() that does the assignments for us. It's formally defined as:
#include <sys/neutrino.h>
#define SETIOV(_iov, _addr, _len) \
((_iov)->iov_base = (void *)(_addr), \
(_iov)->iov_len = (_len))
SETIOV() accepts an iov_t, and the address and length data to be stuffed into the IOV.
Also notice that since we're creating an IOV to point to the header, we can allocate the header on the stack without using malloc(). This can be a blessing and a curse — it's a blessing when the header is quite small, because you avoid the headaches of dynamic memory allocation, but it can be a curse when the header is huge, because it can consume a fair chunk of stack space. Generally, the headers are quite small.
In any event, the important work is done by MsgSendv(), which takes almost the same arguments as the MsgSend() function that we used in the previous example:
#include <sys/neutrino.h>
int MsgSendv (int coid,
const iov_t *siov,
int sparts,
const iov_t *riov,
int rparts);
Let's examine the arguments:
This is how the kernel views the data:
How the kernel sees a multipart message.
The kernel just copies the data seamlessly from each part of the IOV in the client's space into the server's space (and back, for the reply). Effectively, the kernel is performing a gather-scatter operation.
A few points to keep in mind:
Why is the last point so important? To answer that, let's take a look at the big picture. On the client side, let's say we issued:
write (fd, buf, 12000);
which generated a two-part IOV of:
On the server side, (let's say it's the filesystem, fs-qnx4), we have a number of 4 KB cache blocks, and we'd like to efficiently receive the message directly into the cache blocks. Ideally, we'd like to write some code like this:
// set up the IOV structure to receive into: SETIOV (iov + 0, &header, sizeof (header.io_write)); SETIOV (iov + 1, &cache_buffer [37], 4096); SETIOV (iov + 2, &cache_buffer [16], 4096); SETIOV (iov + 3, &cache_buffer [22], 4096); rcvid = MsgReceivev (chid, iov, 4, NULL);
This code does pretty much what you'd expect: it sets up a 4-part IOV structure, sets the first part of the structure to point to the header, and the next three parts to point to cache blocks 37, 16, and 22. (These numbers represent cache blocks that just happened to be available at that particular time.) Here's a graphical representation:
Converting contiguous data to separate buffers.
Then the MsgReceivev() function is called, indicating that we'll receive a message from the specified channel (the chid parameter) and that we're supplying a 4-part IOV structure. This also shows the IOV structure itself.
(Apart from its IOV functionality, MsgReceivev() operates just like MsgReceive().)
Oops! We made the same mistake as we did before, when we introduced the MsgReceive() function. How do we know what kind of message we're receiving, and how much data is associated with it, until we actually receive the message?
We can solve this the same way as before:
rcvid = MsgReceive (chid, &header, sizeof (header), NULL);
switch (header.message_type) {
…
case _IO_WRITE:
number_of_bytes = header.io_write.nbytes;
// allocate / find cache buffer entries
// fill 3-part IOV with cache buffers
MsgReadv (rcvid, iov, 3, sizeof (header.io_write));
This does the initial MsgReceive() (note that we didn't use the IOV form for this — there's really no need to do that with a one-part message), figures out what kind of message it is, and then continues reading the data out of the client's address space (starting at offset sizeof (header.io_write)) into the cache buffers specified by the 3-part IOV.
Notice that we switched from using a 4-part IOV (in the first example) to a 3-part IOV. That's because in the first example, the first part of the 4-part IOV was the header, which we read directly using MsgReceive(), and the last three parts of the 4-part IOV are the same as the 3-part IOV — they specify where we'd like the data to go.
You can imagine how we'd perform the reply for a read request:
Note that if the data doesn't start right at the beginning of a cache block (or other data structure), this isn't a problem. Simply offset the first IOV to point to where the data does start, and modify the size.
All the message-passing functions except the MsgSend*() family have the same general form: if the function has a “v” at the end of it, it takes an IOV and a number-of-parts; otherwise, it takes a pointer and a length.
The MsgSend*() family has four major variations in terms of the source and destinations for the message buffers, combined with two variations of the kernel call itself.
Look at the following table:
| Function | Send buffer | Receive buffer |
|---|---|---|
| MsgSend() | Linear | Linear |
| MsgSendnc() | Linear | Linear |
| MsgSendsv() | Linear | IOV |
| MsgSendsvnc() | Linear | IOV |
| MsgSendvs() | IOV | Linear |
| MsgSendvsnc() | IOV | Linear |
| MsgSendv() | IOV | IOV |
| MsgSendvnc() | IOV | IOV |
By “linear,” I mean a single buffer of type void * is passed, along with its length. The easy way to remember this is that the “v” stands for “vector,” and is in the same place as the appropriate parameter — first or second, referring to “send” or “receive,” respectively.
Hmmm… looks like the MsgSendsv() and MsgSendsvnc() functions are identical, doesn't it? Well, yes, as far as their parameters go, they indeed are. The difference lies in whether or not they are cancellation points. The “nc” versions are not cancellation points, whereas the non-“nc” versions are. (For more information about cancellation points and cancelability in general, please consult the Neutrino Library Reference, under pthread_cancel().)
You've probably already suspected that all the variants of the MsgRead(), MsgReceive(), MsgSend(), and MsgWrite() functions are closely related. (The only exception is MsgReceivePulse() — we'll look at this one shortly.)
Which ones should you use? Well, that's a bit of a philosophical debate. My own personal preference is to mix and match.
If I'm sending or receiving only one-part messages, why bother with the complexity of setting up IOVs? The tiny amount of CPU overhead in setting them up is basically the same regardless of whether you set it up yourself or let the kernel/library do it. The single-part message approach saves the kernel from having to do address space manipulations and is a little bit faster.
Should you use the IOV functions? Absolutely! Use them any time you find yourself dealing with multipart messages. Never copy the data when you can use a multipart message transfer with only a few lines of code. This keeps the system screaming along by minimizing the number of times data gets copied around the system; passing the pointers is much faster than copying the data into a new buffer.
All the messaging we've talked about so far blocks the client. It's nap time for the client as soon as it calls MsgSend(). The client sleeps until the server gets around to replying.
However, there are instances where the sender of a message can't afford to block. We'll look at some examples in the Interrupts and Clocks, Timers, and Getting a Kick Every So Often chapters, but for now we should understand the concept.
The mechanism that implements a non-blocking send is called a pulse. A pulse is a tiny message that:
Receiving a pulse is very simple: a tiny, well-defined message is presented to the MsgReceive(), as if a thread had sent a normal message. The only difference is that you can't MsgReply() to this message — after all, the whole idea of a pulse is that it's asynchronous. In this section, we'll take a look at another function, MsgReceivePulse(), that's useful for dealing with pulses.
The only “funny” thing about a pulse is that the receive ID that comes back from the MsgReceive() function is zero. That's your indication that this is a pulse, rather than a regular message from a client. You'll often see code in servers that looks like this:
#include <sys/neutrino.h>
rcvid = MsgReceive (chid, …);
if (rcvid == 0) { // it's a pulse
// determine the type of pulse
// handle it
} else { // it's a regular message
// determine the type of message
// handle it
}
Okay, so you receive this message with a receive ID of zero. What does it actually look like? From the <sys/neutrino.h> header file, here's the definition of the _pulse structure:
struct _pulse {
uint16_t type;
uint16_t subtype;
int8_t code;
uint8_t zero [3];
union sigval value;
int32_t scoid;
};
Both the type and subtype members are zero (a further indication that this is a pulse). The code and value members are set to whatever the sender of the pulse determined. Generally, the code will be an indication of why the pulse was sent; the value will be a 32-bit data value associated with the pulse. Those two fields are where the “40 bits” of content comes from; the other fields aren't user adjustable.
The kernel reserves negative values of code, leaving 127 values for programmers to use as they see fit.
The value member is actually a union:
union sigval {
int sival_int;
void *sival_ptr;
};
Therefore (expanding on the server example above), you often see code like:
#include <sys/neutrino.h>
rcvid = MsgReceive (chid, …
if (rcvid == 0) { // it's a pulse
// determine the type of pulse
switch (msg.pulse.code) {
case MY_PULSE_TIMER:
// One of your timers went off, do something
// about it...
break;
case MY_PULSE_HWINT:
// A hardware interrupt service routine sent
// you a pulse. There's a value in the "value"
// member that you need to examine:
val = msg.pulse.value.sival_int;
// Do something about it...
break;
case _PULSE_CODE_UNBLOCK:
// A pulse from the kernel, indicating a client
// unblock was received, do something about it...
break;
// etc...
} else { // it's a regular message
// determine the type of message
// handle it
}
This code assumes, of course, that you've set up your msg structure to contain a struct _pulse pulse; member, and that the manifest constants MY_PULSE_TIMER and MY_PULSE_HWINT are defined. The pulse code _PULSE_CODE_UNBLOCK is one of those negative-numbered kernel pulses mentioned above. You can find a complete list of them in <sys/neutrino.h> along with a brief description of the value field.
The MsgReceive() and MsgReceivev() functions will receive either a “regular” message or a pulse. There may be situations where you want to receive only pulses. The best example of this is in a server where you've received a request from a client to do something, but can't complete the request just yet (perhaps you have to do a long hardware operation). In such a design, you'd generally set up the hardware (or a timer, or whatever) to send you a pulse whenever a significant event occurs.
If you write your server using the classic “wait in an infinite loop for messages” design, you might run into a situation where one client sends you a request, and then, while you're waiting for the pulse to come in (to signal completion of the request), another client sends you another request. Generally, this is exactly what you want — after all, you want to be able to service multiple clients at the same time. However, there might be good reasons why this is not acceptable — servicing a client might be so resource-intensive that you want to limit the number of clients.
In that case, you now need to be able to “selectively” receive only a pulse, and not a regular message. This is where MsgReceivePulse() comes into play:
#include <sys/neutrino.h>
int MsgReceivePulse (int chid,
void *rmsg,
int rbytes,
struct _msg_info *info);
As you can see, you use the same parameters as MsgReceive(); the channel ID, the buffer (and its size), as well as the info parameter. (We discussed the info parameter above, in “Who sent the message?”.) Note that the info parameter is not used in the case of a pulse; you might ask why it's present in the parameter list. Simple answer: it was easier to do it that way in the implementation. Just pass a NULL!
The MsgReceivePulse() function will receive nothing but pulses. So, if you had a channel with a number of threads blocked on it via MsgReceivePulse(), (and no threads blocked on it via MsgReceive()), and a client attempted to send your server a message, the client would remain SEND-blocked until a thread issued the MsgReceive() call. Pulses would be transferred via the MsgReceivePulse() functions in the meantime.
The only thing you can guarantee if you mix both MsgReceivePulse() and MsgReceive() is that the MsgReceivePulse() will get pulses only. The MsgReceive() could get pulses or messages! This is because, generally, the use of the MsgReceivePulse() function is reserved for the cases where you want to exclude regular message delivery to the server.
This does introduce a bit of confusion. Since the MsgReceive() function can receive both a message and a pulse, but the MsgReceivePulse() function can receive only a pulse, how do you deal with a server that makes use of both functions? Generally, the answer here is that you'd have a pool of threads that are performing MsgReceive(). This pool of threads (one or more threads; the number depends on how many clients you're prepared to service concurrently) is responsible for handling client calls (requests for service). Since you're trying to control the number of “service-providing threads,” and since some of these threads may need to block, waiting for a pulse to arrive (for example, from some hardware or from another thread), you'd typically block the service-providing thread using MsgReceivePulse(). This ensures that a client request won't “sneak in” while you're waiting for the pulse (since MsgReceivePulse() will receive only a pulse).
As mentioned above in “The send-hierarchy,” there are cases when you need to break the natural flow of sends.
Such a case might occur if you had a client that sent a message to the server, the result might not be available for a while, and the client didn't want to block. Of course, you could also partly solve this with threads, by having the client simply “use up” a thread on the blocking server call, but this may not scale well for larger systems (where you'd be using up lots of threads to wait for many different servers). Let's say you didn't want to use a thread, but instead wanted the server to reply immediately to the client, “I'll get around to your request shortly.” At this point, since the server replied, the client is now free to continue processing. Once the server has completed whatever task the client gave it, the server now needs some way to tell the client, “Hey, wake up, I'm done.” Obviously, as we saw in the send-hierarchy discussion above, you can't have the server send a message to the client, because this might cause deadlock if the client sent a message to the server at that exact same instant. So, how does the server “send” a message to a client without violating the send hierarchy?
It's actually a multi-step operation. Here's how it works:
We'll take a look in detail at the struct sigevent in the Clocks, Timers, and Getting a Kick Every So Often chapter, under “How to fill in the struct sigevent.” For now, just think of the struct sigevent as a “black box” that somehow contains the event that the server uses to notify the client.
Since the server stored the struct sigevent and the receive ID from the client, the server can now call MsgDeliverEvent() to deliver the event, as selected by the client, to the client:
int
MsgDeliverEvent (int rcvid,
const struct sigevent *event);
Notice that the MsgDeliverEvent() function takes two parameters, the receive ID (in rcvid) and the event to deliver in event. The server does not modify or examine the event in any way! This point is important, because it allows the server to deliver whatever kind of event the client chose, without any specific processing on the server's part. (The server can, however, verify that the event is valid by using the MsgVerifyEvent() function.)
The rcvid is a receive ID that the server got from the client. Note that this is indeed a special case. Generally, after the server has replied to a client, the receive ID ceases to have any meaning (the reasoning being that the client is unblocked, and the server couldn't unblock it again, or read or write data from/to the client, etc.). But in this case, the receive ID contains just enough information for the kernel to be able to decide which client the event should be delivered to. When the server calls the MsgDeliverEvent() function, the server doesn't block — this is a non-blocking call for the server. The client has the event delivered to it (by the kernel), and may then perform whatever actions are appropriate.
When we introduced the server (in “The server”), we mentioned that the ChannelCreate() function takes a flags parameter and that we'd just leave it as zero.
Now it's time to explain the flags. We'll examine only a few of the possible flags values:
Let's look at the _NTO_CHF_UNBLOCK flag; it has a few interesting wrinkles for both the client and the server.
Normally (i.e., where the server does not specify the _NTO_CHF_UNBLOCK flag) when a client wishes to unblock from a MsgSend() (and related MsgSendv(), MsgSendvs(), etc. family of functions), the client simply unblocks. The client could wish to unblock due to receiving a signal or a kernel timeout (see the TimerTimeout() function in the Neutrino Library Reference, and the Clocks, Timers, and Getting a Kick Every So Often chapter). The unfortunate aspect to this is that the server has no idea that the client has unblocked and is no longer waiting for a reply. Note that it isn't possible to write a reliable server with this flag off, except in very special situations which require cooperation between the server and all its clients.
Let's assume that you have a server with multiple threads, all blocked on the server's MsgReceive() function. The client sends a message to the server, and one of the server's threads receives it. At this point, the client is blocked, and a thread in the server is actively processing the request. Now, before the server thread has a chance to reply to the client, the client unblocks from the MsgSend() (let's assume it was because of a signal).
Remember, a server thread is still processing the request on behalf of the client. But since the client is now unblocked (the client's MsgSend() would have returned with EINTR), the client is free to send another request to the server. Thanks to the architecture of Neutrino servers, another thread would receive another message from the client, with the exact same receive ID! The server has no way to tell these two requests apart! When the first thread completes and replies to the client, it's really replying to the second message that the client sent, not the first message (as the thread actually believes that it's doing). So, the server's first thread replies to the client's second message.
This is bad enough; but let's take this one step further. Now the server's second thread completes the request and tries to reply to the client. But since the server's first thread already replied to the client, the client is now unblocked and the server's second thread gets an error from its reply.
This problem is limited to multithreaded servers, because in a single-threaded server, the server thread would still be busy working on the client's first request. This means that even though the client is now unblocked and sends again to the server, the client would now go into the SEND-blocked state (instead of the REPLY-blocked state), allowing the server to finish the processing, reply to the client (which would result in an error, because the client isn't REPLY-blocked any more), and then the server would receive the second message from the client. The real problem here is that the server is performing useless processing on behalf of the client (the client's first request). The processing is useless because the client is no longer waiting for the results of that work.
The solution (in the multithreaded server case) is to have the server specify the _NTO_CHF_UNBLOCK flag to its ChannelCreate() call. This says to the kernel, “Tell me when a client tries to unblock from me (by sending me a pulse), but don't let the client unblock! I'll unblock the client myself.”
The key thing to keep in mind is that this server flag changes the behavior of the client by not allowing the client to unblock until the server says it's okay to do so.
In a single-threaded server, the following happens:
| Action | Client | Server |
|---|---|---|
| Client sends to server | Blocked | Processing |
| Client gets hit with signal | Blocked | Processing |
| Kernel sends pulse to server | Blocked | Processing (first message) |
| Server completes the first request, replies to client | Unblocked with correct data | Processing (pulse) |
This didn't help the client unblock when it should have, but it did ensure that the server didn't get confused. In this kind of example, the server would most likely simply ignore the pulse that it got from the kernel. This is okay to do — the assumption being made here is that it's safe to let the client block until the server is ready with the data.
If you want the server to act on the pulse that the kernel sent, there are two ways to do this:
Which method you choose depends on the type of work the server does. In the first case, the server is actively performing the work on behalf of the client, so you really don't have a choice — you'll have to have a second thread that listens for unblock-pulses from the kernel (or you could poll periodically within the thread to see if a pulse has arrived, but polling is generally discouraged).
In the second case, the server has something else doing the work — perhaps a piece of hardware has been commanded to “go and collect data.” In that case, the server's thread will be blocked on the MsgReceive() function anyway, waiting for an indication from the hardware that the command has completed.
In either case, the server must reply to the client, otherwise the client will remain blocked.
Even if you use the _NTO_CHF_UNBLOCK flag as described above, there's still one more synchronization problem to deal with. Suppose that you have multiple server threads blocked on the MsgReceive() function, waiting for messages or pulses, and the client sends you a message. One thread goes off and begins the client's work. While that's happening, the client wishes to unblock, so the kernel generates the unblock pulse. Another thread in the server receives this pulse. At this point, there's a race condition — the first thread could be just about ready to reply to the client. If the second thread (that got the pulse) does the reply, then there's a chance that the client would unblock and send another message to the server, with the server's first thread now getting a chance to run and replying to the client's second request with the first request's data:
Confusion in a multithreaded server.
Or, if the thread that got the pulse is just about to reply to the client, and the first thread does the reply, then you have the same situation — the first thread unblocks the client, who sends another request, and the second thread (that got the pulse) now unblocks the client's second request.
The situation is that you have two parallel flows of execution (one caused by the message, and one caused by the pulse). Ordinarily, we'd immediately recognize this as a situation that requires a mutex. Unfortunately, this causes a problem — the mutex would have to be acquired immediately after the MsgReceive() and released before the MsgReply(). While this will indeed work, it defeats the whole purpose of the unblock pulse! (The server would either get the message and ignore the unblock pulse until after it had replied to the client, or the server would get the unblock pulse and cancel the client's second operation.)
A solution that looks promising (but is ultimately doomed to failure) would be to have a fine-grained mutex. What I mean by that is a mutex that gets locked and unlocked only around small portions of the control flow (the way that you're supposed to use a mutex, instead of blocking the entire processing section, as proposed above). You'd set up a “Have we replied yet?” flag in the server, and this flag would be cleared when you received a message and set when you replied to a message. Just before you replied to the message, you'd check the flag. If the flag indicates that the message has already been replied to, you'd skip the reply. The mutex would be locked and unlocked around the checking and setting of the flag.
Unfortunately, this won't work because we're not always dealing with two parallel flows of execution — the client won't always get hit with a signal during processing (causing an unblock pulse). Here's the scenario where it breaks:
If you refine the flag to indicate more states (such as pulse received, pulse replied to, message received, message replied to), you'll still run into a synchronization race condition because there's no way for you to create an atomic binding between the flag and the receive and reply function calls. (Fundamentally, that's where the problem lies — the small timing windows after a MsgReceive() and before the flag is adjusted, and after the flag is adjusted just before the MsgReply().) The only way to get around this is to have the kernel keep track of the flag for you.
Luckily, the kernel keeps track of the flag for you as a single bit in the message info structure (the struct _msg_info that you pass as the last parameter to MsgReceive(), or that you can fetch later, given the receive ID, by calling MsgInfo()).
This flag is called _NTO_MI_UNBLOCK_REQ and is set if the client wishes to unblock (for example, after receiving a signal).
This means that in a multithreaded server, you'd typically have a “worker” thread that's performing the client's work, and another thread that's going to receive the unblock message (or some other message; we'll just focus on the unblock message for now). When you get the unblock message from the client, you'd set a flag to yourself, letting your program know that the thread wishes to unblock.
There are two cases to consider:
If the worker thread is blocked, you'll need to have the thread that got the unblock message awaken it. It might be blocked if it's waiting for a resource, for example. When the worker thread wakes up, it should examine the _NTO_MI_UNBLOCK_REQ flag, and, if set, reply with an abort status. If the flag isn't set, then the thread can do whatever normal processing it does when it wakes up.
Alternatively, if the worker thread is running, it should periodically check the “flag to self” that the unblock thread may have set, and if the flag is set, it should reply to the client with an abort status. Note that this is just an optimization: in the unoptimized case, the worker thread would constantly call “MsgInfo” on the receive ID and check the _NTO_MI_UNBLOCK_REQ bit itself.
To keep things clear, I've avoided talking about how you'd use message passing over a network, even though this is a crucial part of Neutrino's flexibility!
Everything you've learned so far applies to message passing over the network.
Earlier in this chapter, I showed you an example:
#include <fcntl.h>
#include <unistd.h>
int
main (void)
{
int fd;
fd = open ("/net/wintermute/home/rk/filename", O_WRONLY);
write (fd, "This is message passing\n", 24);
close (fd);
return (EXIT_SUCCESS);
}
At the time, I said that this was an example of “using message passing over a network.” The client creates a connection to a ND/PID/CHID (which just happens to be on a different node), and the server performs a MsgReceive() on its channel. The client and server are identical in this case to the local, single-node case. You could stop reading right here — there really isn't anything “tricky” about message passing over the network. But for those readers who are curious about the how of this, read on!
Now that we've seen some of the details of local message passing, we can discuss in a little more depth how message passing over a network works. While this discussion may seem complicated, it really boils down to two phases: name resolution, and once that's been taken care of, simple message passing.
Here's a diagram that illustrates the steps we'll be talking about:
Message passing over a network. Notice that Qnet is divided into two sections.
In the diagram, our node is called magenta, and, as implied by the example, the target node is called wintermute.
Let's analyze the interactions that occur when a client program uses Qnet to access a server over the network:
Once steps 1 through 3 have been established, step 4 is the model for all future communications. In our client example above, the open(), read(), and close() messages all take path number 4. Note that the client's open() is what triggered this sequence of events to happen in the first place — but the actual open message flows as described (through path number 4).
|
For the really interested reader: I've left out one step. During step 2, when the client asks Qnet about wintermute, Qnet needs to figure out who wintermute is. This may result in Qnet performing one more network transaction to resolve the nodename. The diagram presented above is correct if we assume that Qnet already knew about wintermute. |
We'll come back to the messages used for the open(), read(), and close() (and others) in the Resource Managers chapter.
So, once the connection is established, all further messaging flows using step 4 in the diagram above. This may lead you to the erroneous belief that message passing over a network is identical to message passing in the local case. Unfortunately, this is not true. Here are the differences:
Since message passing is now being done over some medium, rather than a direct kernel-controlled memory-to-memory copy, you can expect that the amount of time taken to transfer messages will be significantly higher (100 MB Ethernet versus 100 MHz 64-bit wide DRAM is going to be an order of magnitude or two slower). Plus, on top of this will be protocol overhead (minimal) and retries on lossy networks.
When you call ConnectAttach(), you're specifying an ND, a PID, and a CHID. All that happens in Neutrino is that the kernel returns a connection ID to the Qnet “network handler” thread pictured in the diagram above. Since no message has been sent, you're not informed as to whether the node that you've just attached to is still alive or not. In normal use, this isn't a problem, because most clients won't be doing their own ConnectAttach() — rather, they'll be using the services of the library call open(), which does the ConnectAttach() and then almost immediately sends out an “open” message. This has the effect of indicating almost immediately if the remote node is alive or not.
When a server calls MsgDeliverEvent() locally, it's the kernel's responsibility to deliver the event to the target thread. With the network, the server still calls MsgDeliverEvent(), but the kernel delivers a “proxy” of that event to Qnet, and it's up to Qnet to deliver the proxy to the other (client-side) Qnet, who'll then deliver the actual event to the client. Things can get screwed up on the server side, because the MsgDeliverEvent() function call is non-blocking — this means that once the server has called MsgDeliverEvent() it's running. It's too late to turn around and say, “I hate to tell you this, but you know that MsgDeliverEvent() that I said succeeded? Well, it didn't!”
To prevent the problem I just mentioned with MsgDeliverEvent() from happening with MsgReply(), MsgRead(), and MsgWrite(), these functions were transformed into blocking calls when used over the network. Locally they'd simply transfer the data and unblock immediately. On the network, we have to (in the case of MsgReply()) ensure that the data has been delivered to the client or (in the case of the other two) to actually transfer the data to or from the client over the network.
Finally, MsgReceive() is affected as well (in the networked case). Not all the client's data may have been transferred over the network by Qnet when the server's MsgReceive() unblocks. This is done for performance reasons.
There are two flags in the struct _msg_info that's passed as the last parameter to MsgReceive() (we've seen this structure in detail in “Who sent the message?” above):
So, if the client wanted to transfer 1 megabyte of data over the network, the server's MsgReceive() would unblock and msglen would be set to 8192 (indicating that 8192 bytes were available in the buffer), while srcmsglen would be set to 1048576 (indicating that the client tried to send 1 megabyte).
The server then uses MsgRead() to get the rest of the data from the client's address space.
The other “funny” thing that we haven't yet talked about when it comes to message passing is this whole business of a “node descriptor” or just “ND” for short.
Recall that we used symbolic node names, like /net/wintermute in our examples. Under QNX 4 (the previous version of the OS before Neutrino), native networking was based on the concept of a node ID, a small integer that was unique on the network. Thus, we'd talk about “node 61,” or “node 1,” and this was reflected in the function calls.
Under Neutrino, all nodes are internally referred to by a 32-bit quantity, but it's not network unique! What I mean by that is that wintermute might think of spud as node descriptor number “7,” while spud might think of magenta as node descriptor number “7” as well. Let me expand that to give you a better picture. This table shows some sample node descriptors that might be used by three nodes, wintermute, spud, and foobar:
| Node | wintermute | spud | foobar |
|---|---|---|---|
| wintermute | 0 | 7 | 4 |
| spud | 4 | 0 | 6 |
| foobar | 5 | 7 | 0 |
Notice how each node's node descriptor for itself is zero. Also notice how wintermute's node descriptor for spud is “7,” as is foobar's node descriptor for spud. But wintermute's node descriptor for foobar is “4” while spud's node descriptor for foobar is “6.” As I said, they're not unique across the network, although they are unique on each node. You can effectively think of them as file descriptors — two processes might have the same file descriptor if they access the same file, but they might not; it just depends on who opened which file when.
Fortunately, you don't have to worry about node descriptors, for a number of reasons:
To work with node descriptors, you'll want to include the file <sys/netmgr.h> because it includes a bunch of netmgr_*() functions.
You'd use the function netmgr_strtond() to convert a string into a node descriptor. Once you have this node descriptor, you'd use it immediately in the ConnectAttach() function call. Specifically, you shouldn't ever cache it in a data structure! The reason is that the native networking manager may decide to reuse it once all connections to that particular node are disconnected. So, if you got a node descriptor of “7” for /net/magenta, and you connected to it, sent a message, and then disconnected, there's a possibility that the native networking manager will return a node descriptor of “7” again for a different node.
Since node descriptors aren't unique per network, the question that arises is, “How do you pass these things around the network?” Obviously, magenta's view of what node descriptor “7” is will be radically different from wintermute's. There are two solutions here:
The first is a good general-purpose solution. The second solution is reasonably simple to use:
int netmgr_remote_nd (int remote_nd, int local_nd);
This function takes two parameters: the remote_nd is the node descriptor of the target machine, and local_nd is the node descriptor (from the local machine's point of view) to be translated to the remote machine's point of view. The result is the node descriptor that is valid from the remote machine's point of view.
For example, let's say wintermute is our local machine. We have a node descriptor of “7” that is valid on our local machine and points to magenta. What we'd like to find out is what node descriptor magenta uses to talk to us:
int remote_nd;
int magenta_nd;
magenta_nd = netmgr_strtond ("/net/magenta", NULL);
printf ("Magenta's ND is %d\n", magenta_nd);
remote_nd = netmgr_remote_nd (magenta_nd, ND_LOCAL_NODE);
printf ("From magenta's point of view, we're ND %d\n",
remote_nd);
This might print something similar to:
Magenta's ND is 7 From magenta's point of view, we're ND 4
This says that on magenta, the node descriptor “4” refers to our node. (Notice the use of the special constant ND_LOCAL_NODE, which is really zero, to indicate “this node.”)
Now, recall that we said (in “Who sent the message?”) that the struct _msg_info contains, among other things, two node descriptors:
struct _msg_info
{
int nd;
int srcnd;
…
};
We stated in the description for those two fields that:
So, for our example above, where wintermute is the local node and magenta is the remote node, when magenta sends a message to us (wintermute), we'd expect that:
One of the interesting issues in a realtime operating system is a phenomenon known as priority inversion.
Priority inversion manifests itself as, for example, a low-priority thread consuming all available CPU time, even though a higher-priority thread is ready to run.
Now you're probably thinking, “Wait a minute! You said that a higher-priority thread will always preempt a lower-priority thread! How can this be?”
This is true — a higher-priority thread will always preempt a lower-priority thread. But something interesting can happen. Let's look at a scenario where we have three threads (in three different processes, just to keep things simple), “L” is our low-priority thread, “H” is our high-priority thread, and “S” is a server. This diagram shows the three threads and their priorities:
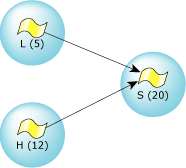
Three threads at different priorities.
Currently, H is running. S, a higher-priority server thread, doesn't have anything to do right now so it's waiting for a message and is blocked in MsgReceive(). L would like to run but is at a lower priority than H, which is running. Everything is as you'd expect, right?
Now H has decided that it would like to go to sleep for 100 milliseconds — perhaps it needs to wait for some slow hardware. At this point, L is running.
This is where things get interesting.
As part of its normal operation, L sends a message to the server thread S, causing S to go READY and (because it's the highest-priority thread that's READY) to start running. Unfortunately, the message that L sent to S was “Compute pi to 5000 decimal places.”
Obviously, this takes more than 100 milliseconds. Therefore, when H's 100 milliseconds are up and H goes READY, guess what? It won't run, because S is READY and at a higher priority!
What happened is that a low-priority thread prevented a higher-priority thread from running by leveraging the CPU via an even higher-priority thread. This is priority inversion.
To fix it, we need to talk about priority inheritance. A simple fix is to have the server, S, inherit the priority of the client thread:
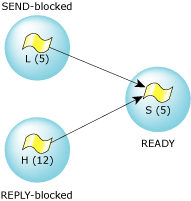
Blocked threads.
In this scenario, when H's 100-millisecond sleep has completed, it goes READY and, because it's the highest-priority READY thread, runs.
Not bad, but there's one more “gotcha.”
Suppose that H now decides that it too would like a computation performed. It wants to compute the 5,034th prime number, so it sends a message to S and blocks.
However, S is still computing pi, at a priority of 5! In our example system, there are lots of other threads running at priorities higher than 5 that are making use of the CPU, effectively ensuring that S isn't getting much time to calculate pi.
This is another form of priority inversion. In this case, a lower-priority thread has prevented a higher-priority thread from getting access to a resource. Contrast this with the first form of priority inversion, where the lower-priority thread was effectively consuming CPU — in this case it's only preventing a higher-priority thread from getting CPU — it's not consuming any CPU itself.
Luckily, the solution is fairly simple here too. Boost the server's priority to be the highest of all blocked clients:
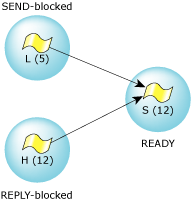
Boosting the server's priority.
This way we take a minor hit by letting L's job run at a priority higher than L, but we do ensure that H gets a fair crack at the CPU.
There's no trick! Neutrino does this automatically for you. (You can turn off priority inheritance if you don't want it; see the _NTO_CHF_FIXED_PRIORITY flag in the ChannelCreate() function's documentation.)
There's a minor design issue here, however. How do you revert the priority to what it was before it got changed?
Your server is running along, servicing requests from clients, adjusting its priority automagically when it unblocks from the MsgReceive() call. But when should it adjust its priority back to what it was before the MsgReceive() call changed it?
There are two cases to consider:
In the first case, it would be incorrect for the server to run at the client's priority when it's no longer doing work for that client! The solution is fairly simple. Use the pthread_setschedparam() or pthread_setschedprio() function (discussed in the Processes and Threads chapter) to revert the priority back to what it should be.
What about the other case? The answer is subtly simple: Who cares?
Think about it. What difference does it make if the server becomes RECEIVE-blocked when it was priority 29 versus when it was priority 2? The fact of the matter is it's RECEIVE-blocked! It isn't getting any CPU time, so its priority is irrelevant. As soon as the MsgReceive() function unblocks the server, the (new) client's priority is inherited by the server and everything works as expected.
Message passing is an extremely powerful concept and is one of the main features on which Neutrino (and indeed, all past QNX operating systems) is built.
With message passing, a client and a server exchange messages (thread-to-thread in the same process, thread-to-thread in different processes on the same node, or thread-to-thread in different processes on different nodes in a network). The client sends a message and blocks until the server receives the message, processes it, and replies to the client.
The main advantages of message passing are: