![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
The Neutrino OS architecture consists of the microkernel and some number of cooperating processes. These processes communicate with each other via various forms of interprocess communication (IPC). Message passing is the primary form of IPC in Neutrino.
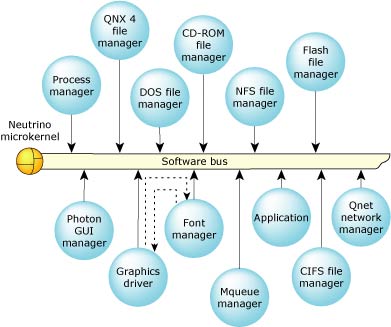
The Neutrino architecture acts as a kind of “software bus” that lets you dynamically plug in/out OS modules.
The above diagram shows the graphics driver sending a message to the font manager when it wants the bitmap for a font. The font manager responds with the bitmap.
The Photon microGUI windowing system is also made up of a number of cooperating processes: the GUI manager (Photon), a font manager (phfontFA), the graphics driver manager (io-graphics), and others. If the graphics driver needs to draw some text, it sends a message to the font manager asking for bitmaps in the desired font for the text to be drawn in. The font manager responds with the requested bitmaps, and the graphics driver then draws the bitmaps on the screen.
This idea of using a set of cooperating processes isn't limited to the OS “system processes.” Your applications should be written in exactly the same way. You might have some driver process that gathers data from some hardware and then needs to pass that data on to other processes, which then act on that data.
Let's use the example of an application that's monitoring the level of water in a reservoir. Should the water level rise too high, then you'll want to alert an operator as well as open some flow-control valve.
In terms of hardware, you'll have some water-level sensor tied to an I/O board in a computer. If the sensor detects some water, it will cause the I/O board to generate an interrupt.
The software consists of a driver process that talks to the I/O board and contains an interrupt handler to deal with the board's interrupt. You'll also have a GUI process that will display an alarm window when told to do so by the driver, and finally, another driver process that will open/close the flow-control valve.
Why break this application into multiple processes? Why not have everything done in one process? There are several reasons:
This approach has two benefits. The first is that a stray pointer won't cause one process to overwrite the memory of another process. The implications are that one process can go bad while other processes keep running.
The second benefit is that the fault will occur precisely when the pointer is used, not when it's overwriting some other process's memory. If a pointer were allowed to overwrite another process's memory, then the problem wouldn't manifest itself until later and would therefore be much harder to debug.
Different operating systems often have different meanings for terms such as “process,” “thread,” “task,” “program,” and so on.
In the Neutrino OS, we typically use only the terms process and thread. An “application” typically means a collection of processes; the term “program” is usually equivalent to “process.”
A thread is a single flow of execution or control. At the lowest level, this equates to the program counter or instruction pointer register advancing through some machine instructions. Each thread has its own current value for this register.
A process is a collection of one or more threads that share many things. Threads within a process share at least the following:
 |
It isn't safe to use floating-point operations in signal handlers. |
Threads don't share such things as stack, values for the various registers, SMP thread-affinity mask, and a few other things.
Two threads residing in two different processes don't share very much. About the only thing they do share is the CPU. You can have them share memory between them, but this takes a little setup (see shm_open() in the Library Reference for an example).
When you run a process, you're automatically running a thread. This thread is called the “main” thread, since the first programmer-provided function that runs in a C program is main(). The main thread can then create additional threads if need be.
Only a few things are special about the main thread. One is that if it returns normally, the code it returns to calls exit(). Calling exit() terminates the process, meaning that all threads in the process are terminated. So when you return normally from the main thread, the process is terminated. When other threads in the process return normally, the code they return to calls pthread_exit(), which terminates just that thread.
Another special thing about the main thread is that if it terminates in such a manner that the process is still around (e.g. it calls pthread_exit() and there are other threads in the process), then the memory for the main thread's stack is not freed up. This is because the command-line arguments are on that stack and other threads may need them. If any other thread terminates, then that thread's stack is freed.
Although there's a good discussion of priorities and scheduling policies in the System Architecture manual (see “Thread scheduling” in the chapter on the microkernel), it will help to go over that topic here in the context of a programmer's guide.
Neutrino provides a priority-driven preemptive architecture. Priority-driven means that each thread can be given a priority and will be able to access the CPU based on that priority. If a low-priority thread and a high-priority thread both want to run, then the high-priority thread will be the one that gets to run.
Preemptive means that if a low-priority thread is currently running and then a high-priority thread suddenly wants to run, then the high-priority thread will take over the CPU and run, thereby preempting the low-priority thread.
Threads can have a scheduling priority ranging from 1 to 255 (the highest priority), independent of the scheduling policy. Non-root threads can have a priority ranging from 1 to 63 (by default); root threads (i.e. those with an effective uid of 0) are allowed to set priorities above 63.
The special idle thread (in the process manager) has priority 0 and is always ready to run. A thread inherits the priority of its parent thread by default.
A thread has both a real priority and an effective priority, and is scheduled in accordance with its effective priority. The thread itself can change both its real and effective priority together, but the effective priority may change because of priority inheritance or the scheduling policy. Normally, the effective priority is the same as the real priority.
Interrupt handlers are of higher priority than any thread, but they're not scheduled in the same way as threads. If an interrupt occurs, then:
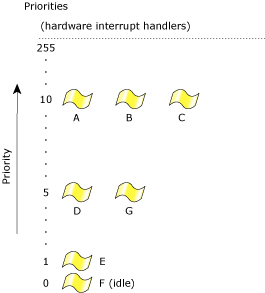
Thread priorities range from 0 (lowest) to 255 (highest).
Although interrupt handlers aren't scheduled in the same way as threads, they're considered to be of a higher priority because an interrupt handler will preempt any running thread.
To fully understand how scheduling works, you must first understand what it means when we say a thread is BLOCKED and when a thread is in the READY state. You must also understand a particular data structure in the kernel called the ready queue.
A thread is BLOCKED if it doesn't want the CPU, which might happen for several reasons, such as:
When designing an application, you always try to arrange it so that if any thread is waiting for something, make sure it isn't spinning in a loop using up the CPU. In general, try to avoid polling. If you do have to poll, then you should try to sleep for some period between polls, thereby giving lower-priority threads the CPU should they want it.
For each type of blocking there is a blocking state. We'll discuss these states briefly as they come up. Examples of some blocking states are REPLY-blocked, RECEIVE-blocked, MUTEX-blocked, INTERRUPT-blocked, and NANOSLEEP-blocked.
A thread is READY if it wants a CPU but something else currently has it. If a thread currently has a CPU, then it's in the RUNNING state. Simply put, a thread that's either READY or RUNNING isn't blocked.
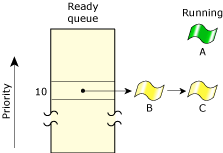
The ready queue is a simplified version of a kernel data structure consisting of a queue with one entry per priority. Each entry in turn consists of another queue of the threads that are READY at the priority. Any threads that aren't READY aren't in any of the queues — but they will be when they become READY.
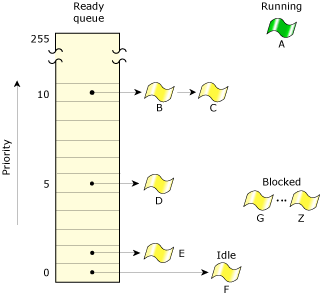
The ready queue for five threads.
In the above diagram, threads B–F are READY. Thread A is currently running. All other threads (G–Z) are BLOCKED. Threads A, B, and C are at the highest priority, so they'll share the processor based on the running thread's scheduling policy.
The active thread is the one in the RUNNING state. The kernel uses an array (with one entry per processor in the system) to keep track of the running threads.
Every thread is assigned a priority. The scheduler selects the next thread to run by looking at the priority assigned to every thread in the READY state (i.e. capable of using the CPU). The thread with the highest priority that's at the head of its priority's queue is selected to run. In the above diagram, thread A was formerly at the head of priority 10's queue, so thread A was moved to the RUNNING state.
The execution of a running thread is temporarily suspended whenever the microkernel is entered as the result of a kernel call, exception, or hardware interrupt. A scheduling decision is made whenever the execution state of any thread changes — it doesn't matter which processes the threads might reside within. Threads are scheduled globally across all processes.
Normally, the execution of the suspended thread will resume, but the scheduler will perform a context switch from one thread to another whenever the running thread:
The running thread will block when it must wait for some event to occur (response to an IPC request, wait on a mutex, etc.). The blocked thread is removed from the running array, and the highest-priority ready thread that's at the head of its priority's queue is then allowed to run. When the blocked thread is subsequently unblocked, it's placed on the end of the ready queue for its priority level.
The running thread will be preempted when a higher-priority thread is placed on the ready queue (it becomes READY as the result of its block condition being resolved). The preempted thread is moved to the start of the ready queue for that priority, and the higher-priority thread runs. When it's time for a thread at that priority level to run again, that thread resumes execution — a preempted thread will not lose its place in the queue for its priority level.
The running thread voluntarily yields the processor (via sched_yield()) and is placed on the end of the ready queue for that priority. The highest-priority thread then runs (which may still be the thread that just yielded).
To meet the needs of various applications, Neutrino provides these scheduling policies:
|
Another scheduling policy (called “other” — SCHED_OTHER) behaves in the same way as round-robin. We don't recommend using the “other” scheduling policy, because its behavior may change in the future. |
Each thread in the system may run using any method. Scheduling methods are effective on a per-thread basis, not on a global basis for all threads and processes on a node.
Remember that these scheduling policies apply only when two or more threads that share the same priority are READY (i.e. the threads are directly competing with each other). If a higher-priority thread becomes READY, it immediately preempts all lower-priority threads.
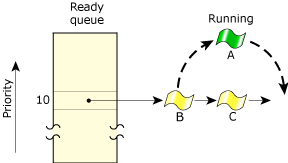
In the following diagram, three threads of equal priority are READY. If Thread A blocks, Thread B will run.
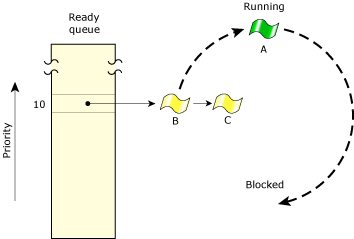
Thread A blocks; Thread B runs.
A thread can call pthread_attr_setschedparam() or pthread_attr_setschedpolicy() to set the scheduling parameters and policy to use for any threads that it creates.
Although a thread inherits its scheduling policy from its parent thread, the thread can call pthread_setschedparam() to request to change the algorithm and priority applied by the kernel, or pthread_setschedprio() to change just the priority. A thread can get information about its current algorithm and policy by calling pthread_getschedparam(). Both these functions take a thread ID as their first argument; you can call pthread_self() to get the calling thread's ID. For example:
struct sched_param param;
int policy, retcode;
/* Get the scheduling parameters. */
retcode = pthread_getschedparam( pthread_self(), &policy, ¶m);
if (retcode != EOK) {
printf ("pthread_getschedparam: %s.\n", strerror (retcode));
return EXIT_FAILURE;
}
printf ("The assigned priority is %d, and the current priority is %d.\n",
param.sched_priority, param.sched_curpriority);
/* Increase the priority. */
param.sched_priority++;
retcode = pthread_setschedparam( pthread_self(), policy, ¶m);
if (retcode != EOK) {
printf ("pthread_setschedparam: %s.\n", strerror (retcode));
return EXIT_FAILURE;
}
When you get the scheduling parameters, the sched_priority member of the sched_param structure is set to the assigned priority, and the sched_curpriority member is set to the priority that the thread is currently running at (which could be different because of priority inheritance).
Our libraries provide a number of ways to get and set scheduling parameters:
|
Our implementations of these functions don't conform completely to POSIX. In multi-threaded applications, they get or set the parameters for thread 1 in the process pid, or for the calling thread if pid is 0. If you depend on this behavior, your code won't be portable. POSIX 1003.1 says these functions should return -1 and set errno to EPERM in a multi-threaded application. |
In FIFO (SCHED_FIFO) scheduling, a thread selected to run continues executing until it:
FIFO scheduling. Thread A runs until it blocks.
In round-robin (SCHED_RR) scheduling, a thread selected to run continues executing until it:
Round-robin scheduling. Thread A ran until it consumed its timeslice; the next READY thread (Thread B) now runs.
A timeslice is the unit of time assigned to every process. Once it consumes its timeslice, a thread is put at the end of its queue in the ready queue and the next READY thread at the same priority level is given control.
A timeslice is calculated as:
4 × ticksize
If your processor speed is greater than 40 MHz, then the ticksize defaults to 1 millisecond; otherwise, it defaults to 10 milliseconds. So, the default timeslice is either 4 milliseconds (the default for most CPUs) or 40 milliseconds (the default for slower hardware).
Apart from time-slicing, the round-robin scheduling method is identical to FIFO scheduling.
The sporadic (SCHED_SPORADIC) scheduling policy is generally used to provide a capped limit on the execution time of a thread within a given period of time. This behavior is essential when Rate Monotonic Analysis (RMA) is being performed on a system that services both periodic and aperiodic events. Essentially, this algorithm allows a thread to service aperiodic events without jeopardizing the hard deadlines of other threads or processes in the system.
Under sporadic scheduling, a thread's priority can oscillate dynamically between a foreground or normal priority and a background or low priority. For more information, see “Sporadic scheduling” in the QNX Neutrino Microkernel chapter of the System Architecture guide.
Now that we know more about priorities, we can talk about why you might want to use threads. We saw many good reasons for breaking things up into separate processes, but what's the purpose of a multithreaded process?
Let's take the example of a driver. A driver typically has two obligations: one is to talk to the hardware and the other is to talk to other processes. Generally, talking to the hardware is more time-critical than talking to other processes. When an interrupt comes in from the hardware, it needs to be serviced in a relatively small window of time — the driver shouldn't be busy at that moment talking to another process.
One way of fixing this problem is to choose a way of talking to other processes where this situation simply won't arise (e.g. don't send messages to another process such that you have to wait for acknowledgment, don't do any time-consuming processing on behalf of other processes, etc.).
Another way is to use two threads: a higher-priority thread that deals with the hardware and a lower-priority thread that talks to other processes. The lower-priority thread can be talking away to other processes without affecting the time-critical job at all, because when the interrupt occurs, the higher-priority thread will preempt the lower-priority thread and then handle the interrupt.
Although this approach does add the complication of controlling access to any common data structures between the two threads, Neutrino provides synchronization tools such as mutexes (mutual exclusion locks), which can ensure exclusive access to any data shared between threads.
The modular architecture is apparent throughout the entire system: the Neutrino OS itself consists of a set of cooperating processes, as does an application. And each individual process can comprise several cooperating threads. What “keeps everything together” is the priority-based preemptive scheduling in Neutrino, which ensures that time-critical tasks are dealt with by the right thread or process at the right time.
|
|
|
|