![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
This chapter includes:
Neutrino provides a variety of filesystems, so that you can easily access DOS, Linux, as well as native (QNX 4) disks. The Filesystems chapter of the System Architecture guide describes their classes and features.
Under Neutrino:
A desktop Neutrino system starts the appropriate block filesystems on booting; you start other filesystems as standalone managers. The default block filesystem is the QNX 4 filesystem.
When you boot your machine, the system detects partitions on the block I/O devices and automatically starts the appropriate filesystem for each partition (see Controlling How Neutrino Starts).
You aren't likely ever to need to stop or restart a block filesystem; if you change any of the filesystem's options, you can use the -e or -u option to the mount command to update the filesystem.
If you need to change any of the options associated with the block I/O device, you can slay the appropriate devb-* driver (being careful not to pull the carpet from under your feet) and restart it, but you'll need to explicitly mount any of the filesystems on it.
To determine how much free space you have on a filesystem, use the df command. For more information, see the Utilities Reference.
The following utilities work with filesystems:
For example, if fs-cifs is already running, you can mount filesystems on it like this:
mount -t cifs -o guest,none //SMB_SERVER:10.0.0.1:/QNX_BIN /bin
See the Utilities Reference for details on usage and syntax.
By an image, we refer to an OS image here, which is a file that contains the OS, your executables, and any data files that might be related to your programs, for use in an embedded system. You can think of the image as a small "filesystem" -- it has a directory structure and some files in it.
The image contains a small directory structure that tells procnto the names and positions of the files contained within it; the image also contains the files themselves. When the embedded system is running, the image can be accessed just like any other read-only filesystem:
# cd /proc/boot # ls .script cat data1 data2 devc-ser8250 esh ls procnto # cat data1 This is a data file, called data1, contained in the image. Note that this is a convenient way of associating data files with your programs.
The above example actually demonstrates two aspects of having the OS image function as a filesystem. When we issue the ls command, the OS loads ls from the image filesystem (pathname /proc/boot/ls). Then, when we issue the cat command, the OS loads cat from the image filesystem as well, and opens the file data1.
You can create an OS image by using mkifs (MaKe Image FileSystem). For more information, see Building Embedded Systems, and mkifs in the Utilities Reference.
Neutrino provides a simple RAM-based filesystem that allows read/write files to be placed under /dev/shmem. This filesystem isn't a true filesystem because it lacks features such as subdirectories. It also doesn't include . and .. entries for the current and parent directories.
The files in the /dev/shmem directory are advertised as "name-special" files (S_IFNAM), which fools many utilities -- such as gzip and more -- that expect regular files (S_IFREG). For this reason, many utilities might not work for the RAM filesystem.
This filesystem is mainly used by the shared memory system of procnto. In special situations (e.g. when no filesystem is available), you can use the RAM filesystem to store file data. There's nothing to stop a file from consuming all free RAM; if this happens, other processes might have problems.
You'll use the RAM filesystem mostly in tiny embedded systems where you need a small, fast, temporary-storage filesystem, but you don't need persistent storage across reboots.
The filesystem comes for free with procnto and doesn't require any setup or device driver. You can simply create files under /dev/shmem and grow them to any size (depending on RAM resources).
Although the RAM filesystem itself doesn't support hard or soft links or directories, you can create a link to it by using process-manager links. For example, you could create a link to a RAM-based /tmp directory:
ln -sP /dev/shmem /tmp
This tells procnto to create a process-manager link to /dev/shmem known as /tmp. Most application programs can then open files under /tmp as if it were a normal filesystem.
 |
In order to minimize the size of the RAM filesystem code inside the process manager, this filesystem specifically doesn't include "big filesystem" features such as file locking and directory creation. |
The QNX 4 filesystem -- the default for Neutrino -- uses the same on-disk structure as in the QNX 4 operating system. This filesystem is implemented by the fs-qnx4.so shared object and is automatically loaded by the devb-* drivers when mounting a QNX 4 filesystem.
You can create a QNX disk partition by using the fdisk and dinit utilities.
This filesystem implements a robust design, using an extent-based, bitmap allocation scheme with fingerprint control structures to safeguard against data loss and to provide easy recovery. Features include:
For information about the implementation of the QNX 4 filesystem, see "QNX 4 disk structure" in the Backing Up and Recovering Data chapter in this guide.
In the QNX 4 filesystem, regular files and directory files are stored as a sequence of extents, contiguous sequences of blocks on a disk. The directory entry for a file keeps track of the file's extents. If the filesystem needs more than one extent to hold a file, it uses a linked list of extent blocks to store information about the extents.
When a file needs more space, the filesystem tries to extend the file contiguously on the disk. If this isn't possible, the filesystem allocates a new extent, which may require allocating a new extent block as well. When it allocates or expands an extent, the filesystem may overallocate space, under the assumption that the process will continue to write and fill the extra space. When the file is closed, any extra space is returned.
This design ensures that when files -- even several files at one time -- are written, they're as contiguous as possible. Since most hard disk drives implement track caching, this not only ensures that files are read as quickly as possible from the disk hardware, but also serves to minimize the fragmentation of data on disk.
For more information about performance, see Fine-Tuning Your System.
The original QNX 4 filesystem supported filenames no more than 48 characters long. This limit has now increased to 505 characters via a backwards-compatible extension that's enabled by default. The same on-disk format is retained; new systems see the longer name, but old ones see a truncated 48-character name.
Long filenames are supported by default when you create a QNX 4 filesystem; to disable them, specify the -N option to dinit. To add long filename support to an existing QNX 4 filesystem, login as root and create an empty, read-only file named .longfilenames, owned by root in the root directory of the filesystem:
cd root_dir touch .longfilenames chmod a=r .longfilenames chown root:root .longfilenames
|
After creating the .longfilenames file, you must restart the filesystem for it to enable long filenames. |
You can determine the maximum filename length that a filesystem supports by using the getconf utility:
getconf _PC_NAME_MAX root_dir
where root_dir is the root directory of the filesystem.
You can't use the characters 0x00-0x1F, 0x7F, and 0xFF in filenames. In addition, / (0x2F) is the pathname separator, and can't be in a filename component. You can use spaces, but you have to "quote" them on the command line; you also have to quote any wildcard characters that the shell supports. For more information, see "Quoting special characters" in Using the Command Line.
File data is stored distinctly from its name and can be referenced by more than one name. Each filename, called a link, points to the actual data of the file itself. (There are actually two kinds of links: hard links, which we refer to simply as "links," and symbolic links, which are described in the next section.)
In order to support links for each file, the filename is separated from the other information that describes a file. The nonfilename information is kept in a storage table called an inode (for "information node").
If a file has only one link (i.e. one filename), the inode information (i.e. the nonfilename information) is stored in the directory entry for the file. If the file has more than one link, the inode is stored as a record in a special file named /.inodes -- the file's directory entry points to the inode record.
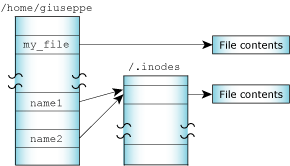
One file referenced by two links.
Note that you can create a link to a file only if the file and the link are in the same filesystem.
There are two other situations in which a file can have an entry in the /.inodes file:
When a file is created, it is given a link count of one. As you add and remove links to the file, this link count is incremented and decremented. The disk space occupied by the file data isn't freed and marked as unused in the bitmap until its link count goes to zero and all programs using the file have closed it. This allows an open file to remain in use, even though it has been completely unlinked. This behavior is part of that stipulated by POSIX and common UNIX practice.
Although you can't create hard links to directories, each directory has two hard-coded links already built in:
The filename "dot" refers to the current directory; "dot dot" refers to the previous (or parent) directory in the hierarchy.
Note that if there's no predecessor, "dot dot" also refers to the current directory. For example, the "dot dot" entry of / is simply / -- you can't go further up the path.
|
There's no POSIX requirement for a filesystem to include . or .. entries; some filesystems, including flash filesystems and /dev/shmem, don't. |
A symbolic link is a special file that usually has a pathname as its data. When the symbolic link is named in an I/O request--by open(), for example--the link portion of the pathname is replaced by the link's "data" and the path is reevaluated.
Symbolic links are a flexible means of pathname indirection and are often used to provide multiple paths to a single file. Unlike hard links, symbolic links can cross filesystems and can also link to directories.
In the following example, the directories /net/node1/usr/fred and /net/node2/usr/barney are linked even though they reside on different filesystems--they're even on different nodes (see the following diagram). You can't do this using hard links, but you can with a symbolic link, as follows:
ln -s /net/node2/usr/barney /net/node1/usr/fred
Note how the symbolic link and the target directory need not share the same name. In most cases, you use a symbolic link for linking one directory to another directory. However, you can also use symbolic links for files, as in this example:
ln -s /net/node1/usr/src/game.c /net/node1/usr/eric/src/sample.c
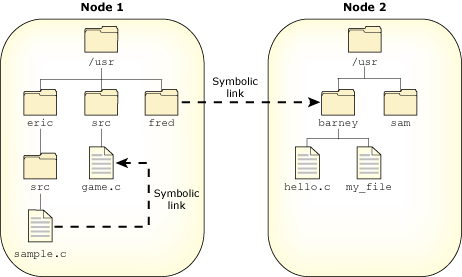
Symbolic links.
|
Removing a symbolic link deletes only the link, not the target. |
Several functions operate directly on the symbolic link. For these functions, the replacement of the symbolic element of the pathname with its target is not performed. These functions include unlink() (which removes the symbolic link), lstat(), and readlink().
Since symbolic links can point to directories, incorrect configurations can result in problems, such as circular directory links. To recover from circular references, the system imposes a limit on the number of hops; this limit is defined as SYMLOOP_MAX in the <limits.h> include file.
The QNX 4 filesystem achieves high throughput without sacrificing reliability. This has been accomplished in several ways.
While most data is held in the buffer cache and written after only a short delay, critical filesystem data is written immediately. Updates to directories, inodes, extent blocks, and the bitmap are forced to disk to ensure that the filesystem structure on disk is never corrupt (i.e. the data on disk should never be internally inconsistent).
Sometimes all of the above structures must be updated. For example, if you move a file to a directory and the last extent of that directory is full, the directory must grow. In such cases, the order of operations has been carefully chosen such that if a catastrophic failure (e.g. a power failure) occurs when the operation is only partially completed, the filesystem, upon rebooting, would still be "intact." At worst, some blocks may have been allocated, but not used. You can recover these for later use by running the chkfsys utility. For more information, see the Backing Up and Recovering Data chapter.
The DOS filesystem provides transparent access to DOS disks, so you can treat DOS filesystems as though they were Neutrino (POSIX) filesystems. This transparency lets processes operate on DOS files without any special knowledge or work on their part.
The fs-dos.so shared object (see the Utilities Reference) lets you mount DOS filesystems (FAT12, FAT16, and FAT32) under Neutrino. This shared object is automatically loaded by the devb-* drivers when mounting a DOS FAT filesystem. If you want to read and write to a DOS floppy disk, mount it by typing something like this:
mount -t dos /dev/fd0 /fd
For information about valid characters for filenames in a DOS filesystem, see the Microsoft Developer Network at http://msdn.microsoft.com. FAT 8.3 names are the most limited; they're uppercase letters, digits, and $%'-_@{}~#(). VFAT names relax it a bit and add the lowercase letters and [];,=+. Neutrino's DOS filesystem silently converts FAT 8.3 filenames to uppercase, to give the illusion that lowercase is allowed ( but it doesn't preserve the case).
For more information on the DOS filesystem manager, see fs-dos.so in the Utilities Reference and Filesystems in the System Architecture guide.
Neutrino's CD-ROM filesystem provides transparent access to CD-ROM media, so you can treat CD-ROM filesystems as though they were POSIX filesystems. This transparency lets processes operate on CD-ROM files without any special knowledge or work on their part.
The fs-cd.so shared object provides filesystem support for the ISO 9660 standard as well as a number of extensions, including Rock Ridge (RRIP), Joliet (Microsoft), and multisession (Kodak Photo CD, enhanced audio). This shared object is automatically loaded by the devb-* drivers when mounting an ISO-9660 filesystem.
The CD-ROM filesystem accepts any characters that it sees in a filename; it's read-only, so it's up to whatever prepares the CD image to impose appropriate restrictions. Strict adherence to ISO 9660 allows only 0-9A-Z_, but Joliet and Rockridge are far more lenient.
For information about burning CDs, see Backing Up and Recovering Data.
The Ext2 filesystem provided in Neutrino provides transparent access to Linux disk partitions. Not all Ext2 features are supported, including the following:
The fs-ext2.so shared object provides filesystem support for Ext2. This shared object is automatically loaded by the devb-* drivers when mounting an Ext2 filesystem.
|
Although Ext2 is the main filesystem for Linux systems, we don't recommend that you use fs-ext2.so as a replacement for the QNX 4 filesystem. Currently, we don't support booting from Ext2 partitions. Also, the Ext2 filesystem relies heavily on its filesystem checker to maintain integrity; this and other support utilities (e.g. mke2fs) aren't currently available for Neutrino. |
If an Ext2 filesystem isn't unmounted properly, a filesystem checker is usually responsible for cleaning up the next time the filesystem is mounted. Although the fs-ext2.so module is equipped to perform a quick test, it automatically mounts the filesystem as read-only if it detects any significant problems (which should be fixed using a filesystem checker).
This filesystem allows the same characters in a filename as the QNX 4 filesystem; see "Filenames," earlier in this chapter.
The Neutrino flash filesystem drivers implement a POSIX-compatible filesystem on NOR flash memory devices. The flash filesystem drivers are standalone executables that contain both the flash filesystem code and the flash device code. There are versions of the flash filesystem driver for different embedded systems hardware as well as PCMCIA memory cards.
|
Flash filesystems don't include . and .. entries for the current and parent directories. |
The naming convention for the drivers is devf-system, where system describes the embedded system. For example, the devf-800fads driver is for the 800FADS PowerPC evaluation board. For information about these drivers, see the devf-* entries in the Utilities Reference.
For more information on the way Neutrino handles flash filesystems, see:
CIFS, the Common Internet File System protocol, lets a client workstation perform transparent file access over a network to a Windows system or a UNIX system running an SMB server. It was formerly known as SMB or Server Message Block protocol, which was used to access resources in a controlled fashion over a LAN. File access calls from a client are converted to CIFS protocol requests and are sent to the server over the network. The server receives the request, performs the actual filesystem operation, and then sends a response back to the client. CIFS runs on top of TCP/IP and uses DNS.
The fs-cifs filesystem manager is a CIFS client operating over TCP/IP. To use it, you must have an SMB server and a valid login on that server. The fs-cifs utility is primarily intended for use as a client with Windows machines, although it also works with any SMB server, e.g. OS/2 Peer, LAN Manager, and SAMBA.
The fs-cifs filesystem manager requires a TCP/IP transport layer, such as the one provided by io-net with the full TCP/IP stack, npm-tcpip.so.
|
The CIFS filesystem manager doesn't work properly with the tiny TCP/IP transport layer provided by npm-ttcpip.so. |
For information about passwords -- and some examples -- see fs-cifs in the Utilities Reference.
If you want to start a CIFS filesystem when you boot your system, put the appropriate command in /etc/host_cfg/$HOSTNAME/rc.d/rc.local or /etc/rc.d/rc.local. For more information, see the description of /etc/rc.d/rc.sysinit in Controlling How Neutrino Starts.
The Network File System (NFS) protocol is a TCP/IP application that supports networked filesystems. It provides transparent access to shared filesystems across networks.
NFS lets a client workstation operate on files that reside on a server across a variety of NFS-compliant operating systems. File access calls from a client are converted to NFS protocol (see RFC 1094 and RFC 1813) requests, and are sent to the server over the network. The server receives the request, performs the actual filesystem operation, and sends a response back to the client.
In essence, NFS lets you graft remote filesystems -- or portions of them -- onto your local namespace. Directories on the remote systems appear as part of your local filesystem, and all the utilities you use for listing and managing files (e.g. ls, cp, mv) operate on the remote files exactly as they do on your local files.
This filesystem allows the same characters in a filename as the QNX 4 filesystem; see "Filenames," earlier in this chapter.
NFS consists of:
|
The procedures used in Neutrino for setting up clients and servers may differ from those used in other implementations. To set up clients and servers on a non-Neutrino system, see the vendor's documentation and examine the initialization scripts to see how the various programs are started on that system. |
It's actually the clients that do the work required to convert the generalized file access that servers provide into a file access method that's useful to applications and users.
If you want to start an NFS filesystem when you boot your system, put the appropriate command in /etc/host_cfg/$HOSTNAME/rc.d/rc.local or /etc/rc.d/rc.local. For more information, see the description of /etc/rc.d/rc.sysinit in Controlling How Neutrino Starts.
An NFS server handles requests from NFS clients that want to access filesystems as NFS mountpoints. For the server to work, you need to start the following programs:
| Name: | Purpose: |
|---|---|
| rpcbind | Remote procedure call (RPC) server |
| nfsd | NFS server and mountd daemon |
The rpcbind server maps RPC program/version numbers into TCP and UDP port numbers. Clients can make RPC calls only if rpcbind is running on the server.
The nfsd daemon reads the /etc/exports file, which lists the filesystems that can be exported and optionally specifies which clients those filesystems can be exported to. If no client is specified, any requesting client is given access.
The nfsd daemon services both NFS mount requests and NFS requests, as specified by the exports file. Upon startup, nfsd reads the /etc/exports.hostname file (or, if this file doesn't exist, /etc/exports) to determine which mountpoints to service. Changes made to this file don't take affect until you restart nfsd.
An NFS client requests that a filesystem exported from an NFS server be grafted onto its local namespace. For the client to work, you need to start the version 2 or 3 of the NFS filesystem manager (fs-nfs2 or fs-nfs3) first. The file handle in version 2 is a fixed-size array of 32 bytes. With version 3, it's a variable-length array of 64 bytes.
The fs-nfs2 or fs-nfs3 filesystem manager is also the NFS 2 or NFS 3 client daemon operating over TCP/IP. To use it, you must have an NFS server and you must be running a TCP/IP transport layer such as that provided by io-net with npm-ttcpip.so. It also needs socket.so and libc.so.
You can create NFS mountpoints with the mount command by specifying nfs for the type and -o ver3 as an option. You must start fs-nfs3 or fs-nfs3 before creating mountpoints in this manner. If you start fs-nfs2 or fs-nfs3 without any arguments, it runs in the background so you can use mount.
To make the request, the client uses the mount utility, as in the following examples:
mount -t nfs 10.1.0.22:/home /mnt/home
mount -t nfs -o ver3 server_node:/qnx_bin /bin
In the first example, the client requests that the /home directory on an IP host be mounted onto the local namespace as /mnt/home. In the second example, NFS protocol version 3 is used for the network filesystem.
Here's another example of a command line that starts and mounts the client:
fs-nfs3 10.7.0.197:/home/bob /homedir
|
Although NFS 2 is older than POSIX, it was designed to emulate UNIX filesystem semantics and happens to be relatively close to POSIX. |
Neutrino's package filesystem is a virtual filesystem manager that presents a customized view of a set of files and directories to a client. The real files are present on some media; the package filesystem presents a virtual view of selected files to the client.
|
Neutrino doesn't start the package filesystem by default, but you can use it if you wish. |
The package filesystem is implemented as fs-pkg (see the Utilities Reference). For an overview of the package filesystem, see "Virtual filesystems" in the Filesystems chapter of the System Architecture guide.
The purpose of the package filesystem is to manage packages in their repositories. It ensures that various nodes can pick and choose a custom set of files and directories they want to use. In essence, the package filesystem creates a virtual filesystem that redirects access requests to a "real" filesystem based on a set of user-selected packages. The contents of the various packages determine what the virtual filesystem looks like.
For example, consider a system that includes two packages, Core and Util, where the Core Package contains:
and the Util package contains:
The actual filesystem looks like this:
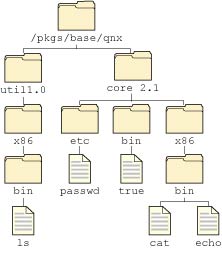
Actual filesystem using the package filesystem.
but the virtual filesystem that the package filesystem presents to the user looks like this:
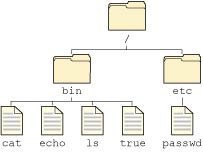
Virtual filesystem using the package filesystem.
When an open-style request comes to the virtual filesystem, a lookup is performed. The lookup determines if the file is indeed managed by the package filesystem. If it is, then the system redirects the request to the real location of the file inside the appropriate package. The real location could be on any filesystem (QNX 4, Linux, DOS), across the network (via NFS, CIFS), or even cached locally (a shadow filesystem). You should use the package filesystem manager, fs-pkg, to control which packages your node sees.
|
This style of redirection is similar to symbolic link. Once the file is opened, all I/O requests go directly to the file's filesystem manager, bypassing the package filesystem. This way, the package filesystem doesn't interfere with read/write performance. |
Your node creates a configuration file, typically called /etc/system/package or /etc/host_cfg/$HOSTNAME/etc/system/packages, where the HOSTNAME environment variable specifies the name of the client node. This file tells the package filesystem which packages are to be presented to the client node and where they should be placed.
To get information about a package, use the pkgctl utility.
The packages are read-only and immutable. The intent is to ensure that you can install packages such that there's never a collision between files in the repositories. This lets multiple versions of software coexist on any one machine.
If you try to change a file that the package filesystem manages, the file is transferred to the spill directory, which contains all local modifications that have been made to used packages. This operation is (not surprisingly) known as spilling, and the files that you've changed are called spilled files.
If the package filesystem's configuration file doesn't specify a location for the spill directory, the package filesystem operates as a read-only filesystem. The default spill directory is /var/pkg/spill.
As an example of spilling, consider the passwd file. After installing Neutrino, you should choose a password for the root user (it initially has no password). When the passwd utility opens the passwd file for writing, the package filesystem copies the file to the spill directory, From this point on, the package filesystem forwards all requests to the spill location rather than to the original file location in the package.
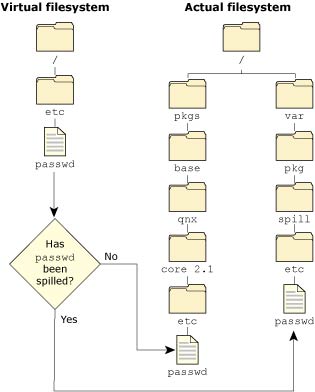
Working with the spill directory.
If you want to restore a spilled file to its original version in the package, use the pkgctl command. For more information, see the Utilities Reference.
There must be a filesystem underneath the redirection layer of the package filesystem.
If you want to copy a file to one of the virtual directories (e.g. /bin), then the package filesystem creates the appropriate structure on the underlying filesystem and then lets the original access request simply fall through to the next server.
If there's no underlying filesystem, then new files can't be added to the virtual filesystem without first generating a package for them.
The package filesystem uses these control files:
The package filesystem also supports patching. When patches are issued between releases, the files for the patch are placed into a package as well. The patch package overrides existing files from other packages without actually deleting them.
Neutrino provides an inflator virtual filesystem. It's a resource manager that sits in front of other filesystems and decompresses files that were previously compressed by the deflate utility.
You typically use inflator when the underlying filesystem is a flash filesystem. Using it can almost double the effective size of the flash memory.
For more information, see the Utilities Reference.
Here are some problems that you might have with filesystems:
flashctl -p raw_mountpoint -u mount -t flash -r raw_mountpoint /mountpoint
where raw_mountpoint indicates the partition (e.g. /dev/fs0px).
find /proc/mount \ -name '[-0-9]*,[-0-9]*,[-0-9]*,[-0-9]*,[-0-9]*' \ -prune -print >mountpoints
cut -d, -f2 <mountpoints | sort | uniq | \
xargs -i "pidin -P{} -FanQ" <pidlist | \
grep -v "pid name"
grep pid mountpoints
use -i /drivername
This procedure (which approximates the functionality of the Windows XP driverquery command) shows the drivers (programs that have mountpoints in the pathname space) that are currently running; it doesn't show those that are merely installed.
|
|
|
|