![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
Making an OS image involves a number of steps, depending on the hardware and configuration of your target system.
In this chapter, we'll take a look at the steps necessary to build an OS image. Then we'll examine the steps required to get that image to the target, whether it involves creating a boot disk/floppy, a network boot, or burning the image into an EPROM or flash device. We'll also discuss how to put together some sample systems to show you how to use the various drivers and resource managers that we supply.
For more information on using the various utilities described in this chapter, see the Utilities Reference.
In the embedded Neutrino world, an "image" can mean either of the following:
| Image type | Description |
|---|---|
| OS image | A bootable or nonbootable structure that contains files; created by the mkifs utility. |
| Flash filesystem image | A structure that can be used in a read-only, read/write, or read/write/reclaim flash filesystem; created by the mkefs utility. |
An OS image is simply a file. When you've created your executables (programs) that you want your embedded system to run, you need to place them somewhere where they can be loaded from. An OS image is the file that contains the OS, your executables, and any data files that might be related to your programs. Actually, you can think of the image as a small "filesystem" -- it has a directory structure and some files in it.
An image can be bootable or nonbootable. A bootable image is one that contains the startup code that the IPL can transfer control to (see the chapter on customizing IPL programs in this book). Generally, a small embedded system will have only the one (bootable) OS image.
A nonbootable image is usually provided for systems where a separate, configuration-dependent setup may be required. Think of it as a second "filesystem" that has some additional files in it (we'll discuss this in more depth later). Since it's nonbootable, this image will typically not contain the OS, startup file, etc.
As previously mentioned, the OS image can be thought of as a filesystem. In fact, the image contains a small directory structure that tells procnto the names and positions of the files contained within it; the image also contains the files themselves. When the embedded system is running, the image can be accessed just like any other read-only filesystem:
# cd /proc/boot
# ls
.script ping cat data1 pidin
ksh ls ftp procnto devc-ser8250-ixp2400
# cat data1
This is a data file, called data1, contained in the image.
Note that this is a convenient way of associating data
files with your programs.
The above example actually demonstrates two aspects of having the OS image function as a filesystem. When we issued the ls command, the OS loaded ls from the image filesystem (pathname /proc/boot/ls). Then, when we issued the cat command, the OS loaded cat from the image filesystem as well, and opened the file data1.
Let's now take a look at how we configure the image to contain files.
The OS image is created by a program called mkifs (make image filesystem), which accepts information from two main sources: its command line and a buildfile.
 |
For more information, see mkifs in the Utilities Reference. |
Let's look at a very simple buildfile, the one that generated the OS image used in the example above:
# A simple "ls", "ping", and shell.
# This file is "shell.bld"
[virtual=armbe,srec] .bootstrap = {
startup-ixdp425
PATH=/proc/boot procnto -vv
}
[+script] .script = {
procmgr_symlink ../../proc/boot/libc.so.2 /usr/lib/ldqnx.so.2
devc-ser8250-ixp2400 -F -e -c14745600 -b115200 0xc8000000 ^2,15 &
reopen
display_msg Serial Driver Started
}
[type=link] /dev/console=/dev/ser1
[type=link] /tmp=/dev/shmem
libc.so
[data=copy]
devc-ser8250-ixp2400
ksh
ls
cat
data1
ping
ftp
pidin
|
In a buildfile, a pound sign (#) indicates a comment; anything between it and the end of the line is ignored. Make sure there's a space between a buildfile command and the pound sign. |
This buildfile consists of these sections:
Although the three sections in the buildfile above seem to be distinct, in reality all three are similar in that they're lists of files.
Notice also how the buildfile itself is structured:
optional_attributes filename optional_contents
For example, the line:
[virtual=armbe,srec] .bootstrap = {
has an attribute of [virtual=armbe,srec], a filename of .bootstrap, and an optional_contents part (from the = { to the corresponding closing brace).
Let's examine these elements in some detail.
The first part (starting with [virtual=armbe,srec]) specifies that a virtual address system is being built. The CPU type appears next; "armbe" indicates a big-endian ARM processor. Then after the comma comes the name of the bootfile (srec).
The rest of the line specifies an inline file (as indicated by the open brace) named ".bootstrap", which consists of the following:
startup-ixdp425 PATH=/proc/boot procnto -vv
The second part starts with the [+script] attribute -- this tells mkifs that the specified file is a script file, a sequence of commands--including the microkernel, procnto--that should be executed when the Process Manager has completed its startup.
|
Script files look just like regular shell scripts, except
that:
|
In this case, the script file is, again, another inline file (again indicated by the open brace). The file (which happens to be called ".script") contains the following:
devc-ser8250-ixp2400 -F -e -c14745600 -b115200 0xc8000000^2,15 & reopen [+session] PATH=:/proc/boot esh &
This script file begins by starting a serial driver (devc-ser8250-ixp2400) in edited mode with hardware flow control disabled at a baud rate of 115200bps at a particular physical memory address. The script then does a reopen to redirect standard input, output, and error. The last line tells mkifs to make the embedded shell program (esh) a session leader (as per POSIX).
|
|
To generate the image file from our sample buildfile, you could execute the command:
mkifs shell.bld shell.ifs
This tells mkifs to use the buildfile shell.bld to create the image file shell.ifs.
Let's return to our example. Notice the "list of files" (i.e. from "[type=link] /dev/console=/dev/ser1" to "pidin").
In the example above, we specified that the files at the end were to be part of the image, and mkifs somehow magically found them. Actually, it's not magic -- mkifs simply looked for the environment variable MKIFS_PATH. This environment variable contains a list of places to look for the files specified in the buildfile. If the environment variable doesn't exist, then the following are searched in this order:
(The ${PROCESSOR} component is replaced with the name of the CPU, e.g. arm.)
Since none of the filenames that we used in our example starts with the "/" character, we're telling mkifs that it should search for files (on the host) within the path list specified by the MKIFS_PATH environment variable as described above. Regardless of where the files came from on the host, in our example they'll all be placed on the target under the /proc/boot directory (there are a few subtleties with this, which we'll come back to).
For our example, devc-con will appear on the target as the file /proc/boot/devc-con, even though it may have come from the host as ${QNX_TARGET}/armbe/sbin/devc-con.
To include files from locations other than those specified in the MKIFS_PATH environment variable, you have a number of options:
By specifying the [search=newpath] attribute, we can cause mkifs to look in places other than what the environment variable MKIFS_PATH specifies. The newpath component is a colon-separated list of pathnames and can include environment variable expansion. For example, to augment the existing MKIFS_PATH pathname to also include the directory /mystuff, you would specify:
[search=${MKIFS_PATH}:/mystuff]
Let's assume that one of the files used in the example is actually stored on your development system as /release/data1. If you simply put /release/data1 in the buildfile, mkifs would include the file in the image, but would call it /proc/boot/data1 on the target system, instead of /release/data1.
Sometimes this is exactly what you want. But at other times you may want to specify the exact pathname on the target (i.e. you may wish to override the prefix of /proc/boot). For example, specifying /etc/passwd would place the host filesystem's /etc/passwd file in the target's pathname space as /proc/boot/passwd -- most likely not what you intended. To get around this, you could specify:
/etc/passwd = /etc/passwd
This tells mkifs that the file /etc/passwd on the host should be stored as /etc/passwd on the target.
On the other hand, you may in fact want a different source file (let's say /home/joe/embedded/passwd) to be the password file for the embedded system. In that case, you would specify:
/etc/passwd = /home/joe/embedded/passwd
For our tiny data1 file, we could just as easily have included it in line -- that is to say, we could have specified its contents directly in the buildfile itself, without the need to have a real data1 file reside somewhere on the host's filesystem. To include the contents in line, we would have specified:
data1 = {
This is a data file, called data1, contained in the image.
Note that this is a convenient way of associating data
files with your programs.
}
A few notes. If your inline file contains the closing brace ("}"), then you must escape that closing brace with a backslash ("\"). This also means that all backslashes must be escaped as well. To have an inline file that contains the following:
This includes a {, a }, and a \ character.
you would have to specify this file (let's call it data2) as follows:
data2 = {
This includes a {, a \}, and a \\ character.
}
Note that since we didn't want the data2 file to contain leading spaces, we didn't supply any in the inline definition. The following, while perhaps "better looking," would be incorrect:
# This is wrong, because it includes leading spaces!
data2 = {
This includes a {, a \}, and a \\ character.
}
If the filename that you're specifying has "weird" characters in it, then you must quote the name with double quote characters ("). For example, to create a file called I "think" so (note the spaces and quotation marks), you would have to specify it as follows:
"I \"think\" so" = ...
But naming files like this is discouraged, since the filenames are somewhat awkward to type from a command line (not to mention that they look goofy).
The files that we included (in the example above) had the owner, group ID, and permissions fields set to whatever they were set to on the host filesystem they came from. The inline files (data1 and data2) got the user ID and group ID fields from the user who ran the mkifs program. The permissions are set according to the user's umask.
If we wanted to explicitly set these fields on particular files within the buildfile, we would prefix the filenames with an attribute:
[uid=0 gid=0 perms=0666] file1 [uid=5 gid=1 perms=a+xr] file2
This marks the first file (file1) as being owned by root (the user ID 0), group zero, and readable and writable by all (the mode of octal 666). The second file (file2) is marked as being owned by user ID 5, group ID 1, and executable and readable by all (the a+xr permissions).
Notice how when we combine attributes, we place all of the attributes within one open-square/close-square set. The following is incorrect:
# Wrong way to do it! [uid=0] [gid=0] [perms=0666] file1
If we wanted to set these fields for a bunch of files, the easiest way to do that would be to specify the uid, gid, and perms attributes on a single line, followed by the list of files:
[uid=5 gid=1 perms=0666] file1 file2 file3 file4
which is equivalent to:
[uid=5 gid=1 perms=0666] file1 [uid=5 gid=1 perms=0666] file2 [uid=5 gid=1 perms=0666] file3 [uid=5 gid=1 perms=0666] file4
If we wanted to include a large number of files, perhaps from a preconfigured directory, we would simply specify the name of the directory instead of the individual filenames. For example, if we had a directory called /release_1.0, and we wanted all the files under that directory to be included in the image, our buildfile would have the line:
/release_1.0
This would put all the files that reside under /release_1.0 into /proc/boot on the target. If there were subdirectories under /release_1.0, then they too would be created under /proc/boot, and all the files in those subdirectories would also be included in the target.
Again, this may or may not be what you intend. If you really want the /release_1.0 files to be placed under /, you would specify:
/=/release_1.0
This tells mkifs that it should grab everything from the /release_1.0 directory and put it into a directory called /. As another example, if we wanted everything in the host's /release_1.0 directory to live under /product on the target, we would specify:
/product=/release_1.0
The script file stored on the target isn't the same as the original specification of the script file within the buildfile. That's because a script file is "special" -- mkifs parses the text commands in the script file and stores only the parsed output on the target, not the original ASCII text. The reason we did this was to minimize the work that the process manager has to do at runtime when it starts up and processes the script file -- we didn't want to have to include a complete shell interpreter within the process manager!
You can now specify which CPU to bind processes when launching processes from the startup script through the [CPU=] attribute.
The [CPU=] is used as any other attribute, and specifies the CPU on which to launch the following process (or , if the attribute is used alone on a line without a command, sets the default CPU for all following processes). The CPU is specified as a (Octal-based) processor number, a value of * resets this.
cpu=processor cpu=*
Example:
cpu=1
If, at boot time, the given CPU is not valid, a warning message will be displayed and the command will be launched without any runmask restriction. Note that due to a limitation in the boot image records, this syntax allows only the specification of a single CPU and not a more generic runmask.
Use the on utility to spawn a process within a fully specified runmask.
Along the lines of the startup script file, our bootstrap specification:
[virtual=armbe,srec] .bootstrap = {
startup-ixdp425
PATH=/proc/boot procnto -vv
}
also constructs an inline file (.bootstrap) that contains two lines: startup-ixdp425 and PATH=/proc/boot procnto -vv.
You can bind in optional modules to procnto by using the [module=...] attribute. For example, to bind in the adaptive partitioning scheduler, change the procnto line to this:
[module=aps] PATH=/proc/boot procnto -vv
|
|
As with the script filename, the actual name of the bootstrap file is irrelevant. However, nowhere else in the buildfile did we specify those two files -- they're included automatically when specified by a [virtual] or [physical] attribute.
The "virtual" attribute (and its sibling the "physical" attribute) specifies the target processor (in our example, the armbe part) and the bootfile (the srec part), a very small amount of code between the IPL and startup programs. The target processor is put into the environment variable $PROCESSOR and is used during pathname expansion. You can omit the target processor specification, in which case it defaults to the same as the host processor. For example:
[virtual=bios] .bootstrap = {
...
would assume an ARM target if you're on an ARM host system.
Both examples find a file called $PROCESSOR/sys/bios.boot (the .boot part is added automatically by mkifs), and process it for configuration information.
While we're looking at the bootstrap specification, it's worth mentioning that you can apply the +compress attribute to compress the entire image. The image is automatically uncompressed before being started. Here's what the first line would look like:
[virtual=armbe,srec +compress] .bootstrap = {
As mentioned above, you can also specify command-line options to mkifs. Since these command-line options are interpreted before the actual buildfile, you can add lines before the buildfile. You would do this if you wanted to use a makefile to change the defaults of a generic buildfile.
The following sample changes the address at which the image starts to 64K (hex 0x10000):
mkifs -l "[image=0x10000]" buildfile image
For more information, see mkifs in the Utilities Reference.
If you'd like to see the contents of an image, you can use the dumpifs utility. The output from dumpifs might look something like this:
Offset Size Name
0 100 Startup-header flags1=0x1 flags2=0 paddr_bias=0x80000000
100 a008 startup.*
a108 5c Image-header mountpoint=/
a164 264 Image-directory
---- ---- Root-dirent
---- 12 usr/lib/ldqnx.so.2 -> /proc/boot/libc.so
---- 9 dev/console -> /dev/ser1
a3c8 80 proc/boot/.script
b000 4a000 proc/boot/procnto
55000 59000 proc/boot/libc.so.2
---- 9 proc/boot/libc.so -> libc.so.2
ae000 7340 proc/boot/devc-ser8250
b6000 4050 proc/boot/esh
bb000 4a80 proc/boot/ls
c0000 14fe0 proc/boot/data1
d5000 22a0 proc/boot/data2
Checksums: image=0x94b0d37b startup=0xa3aeaf2
The more -v ("verbose") options you specify to dumpifs, the more data you'll see.
For more information on dumpifs, see its entry in the Utilities Reference.
If your application requires a writable filesystem and you have flash memory devices in your embedded system, then you can use a Neutrino flash filesystem driver to provide a POSIX-compatible filesystem. The flash filesystem drivers are described in the filesystems chapter of the System Architecture guide. The chapter on customizing the flash filesystem in this book describes how you can build a flash filesystem driver for your embedded system.
You have two options when creating a flash filesystem:
In this section we describe how to create a flash filesystem image file using the mkefs (for make embedded filesystem) utility and a buildfile. How to transfer the flash filesystem image onto your target system is described in the "Embedding an image" section. For details on how to use the flash filesystem drivers, see the Utilities Reference.
The mkefs utility takes a buildfile and produces a flash filesystem image file. The buildfile is a list of attributes and files to include in the filesystem.
The syntax of the buildfile is similar to that for mkifs, but mkefs supports a different set of attributes, including the following:
Refer to the Utilities Reference for a complete description of the buildfile syntax and attributes supported by mkefs.
Here's a very simple example of a buildfile:
[block_size=128k spare_blocks=1 filter=inflator/deflate] /home/ejm/products/sp1/callp/imagedir
In this example, the attributes specify that the flash devices have a block size of 128 KB, that there should be one spare block, and that all the files should be processed using the inflator and deflate utilities, which will compress/decompress the files. A single directory is given. Just as with mkifs, when we specify a directory, all files and subdirectories beneath it are included in the resulting image. Most of the other filename tricks shown above for mkifs also apply to mkefs.
The value you should specify for the block_size attribute depends on the physical block size of the flash device given in the manufacturer's data sheet and on how the flash device is configured in your hardware (specifically the interleave).
Here are some examples:
| If you have: | Set block_size to: |
|---|---|
| an 8-bit flash interface and are using an 8-bit device with a 64K block size | 64K |
| a 16-bit flash interface and are using two interleaved 8-bit flash devices with a 64K block size | 128K |
| a 16-bit flash interface and are using a 16-bit flash device with a 64K block size | 64K |
| a 32-bit flash interface and are using four interleaved 8-bit flash devices with a 64K block size | 256K |
Notice that you don't have to specify any details (other than the block size) about the actual flash devices used in your system.
The spare_blocks attribute indicates how many blocks should be left as spare. A spare block isn't used by the filesystem until it's time to perform a reclaim operation. A nonspare block is then selected for "reclamation" -- the data contained in that block is coalesced into one contiguous region in the spare block. The nonspare block is then erased; it becomes the new spare block. The former spare block takes the place of the reclaimed block.
|
If you specify a spare block (i.e. for the spare_blocks attribute) equal to 0, then the flash filesystem driver won't be able to reclaim space -- it won't have any place to put the new copy of the data. Therefore, you'll be left with a read/write filesystem, which will eventually fill up since there's no way to reclaim space. |
You can use the flashcmp utility to compress files in the flash filesystem. You can do this from a shell or you can use the filter attribute to mkefs.
The flash filesystem drivers know how to transparently decompress files that have been compressed with flashcmp, which means that you can access compressed files in the flash filesystem without having to decompress them first. This can result in significant space savings. But there's a tradeoff to file access performance -- compressed files will be accessed a bit slower.
The file compression mechanism provided with our flash filesystem is a convenient way to cut flash memory costs for customers. The flash filesystem uses popular deflate/inflate algorithms for fast and efficient compression/decompression.
In short, the deflate algorithm is a combination of two algorithms. The first one takes care of removing data duplication in files; the second algorithm advantages data sequences that appear the most often by giving them shorter symbols.
Those two algorithms combined provide excellent lossless compression of data and executable files. The inflate algorithm, which is actually part of the flash filesystem per se, reverses what the deflate algorithm does.
The flash filesystem never compresses any files. It only detects compressed files on the media and decompresses them as they are accessed. An abstraction layer embedded in the flash filesystem code achieves efficiency and preserves POSIX compliance. Special compressed data headers on top of the flash files provide fast seek times.
This layering is quite straightforward. Specific I/O functions include handling the three basic access calls for compressed files:
The compression headers contain a synchronization cue, flags, compressed size, and normal size for the data that follows the header. These headers can be used by the three basic access calls to read decompressed data, seek into the file using a virtual offset, and find the effective size of the file.
This is where compression gets tricky. A compressed file will have two sizes:
As a convenience, our flash filesystems offer a handy namespace that totally replicates the regular flash file's namespace, but gives the media sizes when the files are stat()'ed (rather than the virtual or effective size). Using this new namespace, files are never decompressed, so read operations will yield raw compressed data instead of the decompressed data. This namespace is accessible by default through the .cmp mountpoint directory, right under the regular flash mountpoint.
For instance, running the disk usage utility du would be practically meaningless under a flash directory with data that is decompressed on the fly. It wouldn't reflect flash media usage at all. But running the du utility under .cmp would render a better approximation of media usage.
As mentioned earlier, you can compress files by using any of these methods:
The first method, which is the high-runner case, is to use the mkefs utility. The flashcmp utility can be used as a filter for mkefs to compress the files that get built into the flash filesystem. The files can also be pre-compressed by the flashcmp utility -- this will be detected by mkefs and the data will be put on the flash filesystem with the proper information. What information? A simple bit that tells the flash filesystem that the file should be handled by the flash decompression layer.
This line builds a 16-megabyte filesystem with compression:
[block_size=128K spare_blocks=1 min_size=16m filter=flashcmp] /bin/
The mkefs utility detects a compression signature in the files listed in the buildfile. This means that when files are precompressed, the filter can be omitted. When this signature is detected, the proper bit is set in the metadata area for on-the-fly decompression.
The second method is to put compressed files on the media by using flashcmp, but on board, straight with the flash filesystem. This is where the .cmp mountpoint is reused. Any file created under this mountpoint will have the compressed attribute bit. Needless to say, these files should be written using the compression headers, which the flashcmp utility does well.
In this example, we use flashcmp at the command line to compress the ls file from the image filesystem into a flash filesystem:
$ flashcmp /proc/boot/ls > /fs0p0/.cmp/ls
Note that the .cmp mountpoint is used for the flash filesystem. This tells the flash filesystem to set the compression bit in the metadata area, enabling further decompression on the fly.
You use the .cmp mountpoint to create previously compressed files, write previously compressed data, and check the size of compressed files. If you read a file from this mountpoint, the file won't be decompressed for you, as it is in the regular mountpoint. Now this is where we start talking about rules. All this reading and getting the size of files is fairly simple; things get ugly when it's time to write those files.
What if you need to write uncompressed data to a compressed file? You can do this, but it has to be from the regular mountpoint. And the append-only rule applies for this file as well.
|
Writing uncompressed data to a compressed file can be quite wasteful, because the uncompressed data will still be encapsulated into compressed headers, so a layer of code will be used for nothing. This means that at system design time, files that are meant to be writable during the product life should not be compressed. Preferably, compressed files will remain read-only. |
As a convenience, though, it's still possible to append compressed or uncompressed data to compressed files. But we have to emphasize that this might not always be the most efficient way to store data. Actually, the compression algorithms need a minimum data set to be able to compress, so the result has to be good enough to justify the header abstraction overhead. Buffering isn't possible with compressed files, so there can't be any assumptions for limited overhead when appending to compressed files.
|
Although it's possible to write uncompressed data without the header overhead to a compressed file (provided if done from the .cmp namespace), this isn't a very good idea. The file will loose the capability of rendering virtual uncompressed size and will become unseekable to positions after the first chunk of uncompressed data. The file data will still be readable, but the lost POSIX functionality should dissuade you from trying this. |
So those are the rules, and here is the exception. Truncation is a special case. If a compressed file is opened with O_TRUNC from the regular virtual namespace, the file status will become just as if it were created from this namespace. This gives you full POSIX capabilities and no compression with accompanying restrictions.
The opposite is true: If a non-compressed file is opened with truncation on the .cmp side, then compression rules apply. By the way, the ftruncate() functionality isn't provided with compressed files, but is supported with regular files.
The buffer size is also selectable. This buffer represents the decompressed data size that will be associated with each compression header. Of course, a larger buffer size might allow better compression, but RAM usage will be increased for the flash filesystem driver. The default buffer size is 4K.
On a slightly different note, don't be tempted to reuse the flash filesystem as a decompression engine over a block-oriented or a network filesystem. These filesystems are often available in very high-storage capacity and high-bandwidth formats. Compression over these media is pure overkill and will always be a waste of CPU resources. The flash filesystem with compression is really meant for restrained systems -- the best approach for long-term life of a product is to read Moore's Law* carefully. This law is true for flash as well, so plan ahead.
| * | In 1965, Intel co-founder Gordon Moore observed that the pace of microchip technology change is such that the amount of data storage a microchip can hold doubles every year. |
Always consider the slowdown of compressed data access and increased CPU usage when designing a system. We've seen systems with restricted flash budget increase their boot time by large factors when using compression.
To compress files, you can also use the inflator and deflate pair of utilities, which can compress/decompress files for any filesystem, including flash. For details, see their entries in the Utilities Reference.
After you've created your bootable OS image on the host system, you'll want to transfer it to the target system so that you can boot Neutrino on the target. The various ways of booting the OS on a target system are described in the chapter on customizing IPL programs in this guide.
If you're booting the OS from flash, then you'll want to write the image into the flash devices on the target. The same applies if you have a flash filesystem image -- you'll want to write the image into flash on the target.
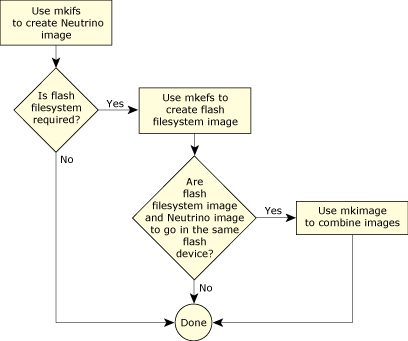
Flash configuration options for your Neutrino-based embedded systems.
Depending on your requirements and the configuration of your target system, you may want to embed:
Also, you may wish to write the boot image and the flash filesystem on the same flash device or different devices. If you want to write the boot image and the flash filesystem on the same device, then you can use the mkimage utility to combine the image files into a single image file.
During the initial development stages, you'll probably need to write the image into flash using a programmer or a download utility. Later on if you have a flash filesystem running on your target, you can then write the image file into a raw flash partition.
If your programmer requires the image file to be in some format other than binary, then you can use the mkrec utility to convert the image file format.
The mkimage utility combines multiple input image files into a single output image file. It recognizes which of the image files contains the boot image and will place this image at the start. Note that instead of using mkimage, some developers rely on a flash programmer to burn the separate images with appropriate alignment.
For example:
mkimage nto.ifs fs.ifs > flash.ifs
will take the nto.ifs and fs.ifs image files and output them to the flash.ifs file.
If you want more control over how the image files are combined, you can use other utilities, such as:
You'll use the System Builder to generate OS images for your target board's RAM or flash. You can create:
For more information about this process, please see the documentation that comes with the QNX Momentics IDE.
The mkrec utility takes a binary image file and converts it to either Motorola S records or Intel hex records, suitable for a flash or EPROM programmer.
For example:
mkrec -s 256k flash.ifs > flash.srec
will convert the image file flash.ifs to an S-record format file called flash.srec. The -s 256k option specifies that the EPROM device is 256K in size.
If you have multiple image files that you wish to download, then you can first use mkimage to combine the image files into a single file before downloading. Or, your flash/EPROM programmer may allow you to download multiple image files at different offsets.
There are many ways to transfer your image into your flash:
The details on how to transfer the image with anything other than the last method is beyond the scope of this document. Using the raw mountpoint is a convenient way that comes bundled with your flash filesystem library. You can actually read and write raw partitions just like regular files, except that when the raw mountpoint is involved, remember to:
For the sake of this discussion, we can use the devf-ram driver. This driver simulates flash using regular memory. To start it, log in as root and type:
# devf-ram &
You can use the flashctl command to erase a partition. You don't need to be root to do this. For instance:
$ flashctl -p /dev/fs0 -e
|
Be careful when you use this command. Make sure you aren't erasing something important on your flash -- like your BIOS! |
On normal flash, the flashctl command on a raw partition should take a while (about one second for each erase block). This command erases the /dev/fs0 raw flash array. Try the hd command on this newly erased flash array; everything should be 0xFF:
$ hd /dev/fs0 0000000: ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ff ................ *
|
For more information on flashctl, see the Utilities Reference. |
Let's make a dummy IPL for the purpose of this example:
$ echo Hello, World! > ipl $ mkrec -s 128k -f full ipl > ipl_image Reset jmps to 0x1FFE0 (jmp 0xFFED) ROM offset is 0x1FFE0
Of course, this IPL won't work for real -- it's just for trying out the flash filesystem. In any event, an IPL wouldn't be very useful in RAM. Let's make a dummy flash filesystem for the purpose of this example (the ^D means Ctrl-D):
$ mkefs -v - flash_image [block_size=128k spare_blocks=1 min_size=384k] /bin/ls /bin/cat ^D writing directory entry -> writing file entry -> ls ** writing file entry -> cat * Filesystem size = 384K block size = 128K 1 spare block(s)
This flash filesystem actually works (unlike the IPL). Now, the flash partition images can be transfered to the flash using any file-transfer utility (such as cp or ftp). We have an IPL image created with mkrec (and properly padded to an erase block boundary) and a flash image created with mkefs, so we can use cat to combine and transfer both images to the flash:
$ cat ipl_image flash_image > /dev/fs0
If you use the hd utility on the raw mountpoint again, you'll see that your flash that had initially all bits set to ones (0xFF) now contains your partition images. To use the flash filesystem partition, you need to slay the driver and start it again so it can recognize the partitions and mount them. For instance, with devf-ram:
$ slay devf-ram $ devf-ram &
From this point, you have a /fs0p1 mountpoint that's in fact a directory and contains the files you specified with mkefs to create your flash image. There's no /fs0p0, because the boot image isn't recognized by the flash filesystem. It's still accessible as a raw mountpoint via /dev/fs0p0. You can do the same operations on /dev/fs0p0 that you could do with /dev/fs0. Even /dev/fs0p1 is accessible, but be careful not to write to this partition while applications are using the flash filesystem at /fs0p1. Try:
$ /fs0p1/ls /fs0p1
You've just executed ls from your flash filesystem and you've listed its contents. To conclude, let's say that what we did in this example is a good starting point for when you customize the flash filesystem to your own platforms. These baby steps should be the first steps to using a full-blown filesystem on your target.
In this section, we'll look at some of the ways you can configure Neutrino systems. Please refer to the Sample Buildfiles appendix in this guide for more detailed examples.
What you want to do will, of course, depend on the type of system you're building. Our purpose in this section is to offer some general guidelines and to help clarify which executables should be used in which circumstances, as well as which shared libraries are required for their respective executables.
The general procedure to set up a system is as follows:
One of the very first things to do in a buildfile is to start a driver that you then redirect standard input, output, and error to. This allows all subsequent drivers and applications to output their startup messages and any diagnostics messages they may emit to a known place where you can examine the output.
Generally, you'd start either the console driver or a serial port driver. The console driver is used when you're developing on a fairly complete "desktop" type of environment; the serial driver is suitable for most "embedded" environments.
But you may not even have any such devices in your deeply embedded system, in which case you would omit this step. Or you may have other types of devices that you can use as your output device, in which case you may require a specialized driver (that you supply). If you don't specify a driver, output will go to the debug output driver provided by the startup code.
This example starts the standard console driver in edited mode (the -e option, which is the default). To set up the output device, you would include the driver in your startup script (the [+script] file). For example:
devc-con -e & reopen /dev/con1
The following starts the 8250 serial port driver in edited mode (the -e option), with an initial baud rate of 115200 baud (the -b option):
devc-ser8250 -e -b115200 & reopen /dev/ser1
In both cases, the reopen command causes standard input, output, and error to be redirected to the specified pathname (either /dev/con1 or /dev/ser1 in the above examples). This redirection holds until otherwise specified with another reopen command.
|
The reopen used above is a mkifs internal command, not the shell builtin command of the same name. |
The next thing you'll want to run are the drivers and/or filesystems that will give you access to the hardware. Note that the console or serial port that we installed in the previous section is actually an example of such a driver, but it was a special case in that it should generally be the first one.
We support several types of drivers/filesystems, including:
Which one you install first is generally driven by where your executables reside. One of the goals for the image is to keep it small. This means that you generally don't put all the executables and shared libraries you plan to load directly into the image -- instead, you place those files into some other medium (whether a flash filesystem, rotating disk, or a network filesystem). In that case, you should start the appropriate driver to get access to your executables. Once you have access to your executables on some medium, you would then start other drivers from that medium.
The alternative, which is often found in deeply embedded systems, is to put all the executables and shared libraries directly into the image. You might want to do this if there's no secondary storage medium or if you wanted to have everything available immediately, without the need to start a driver.
Let's examine the steps required to start the disk, flash, and network drivers. All these drivers share a common feature: they rely on one process that loads one or more .so files, with the particular .so files selected either via the command line of the process or via automatic configuration detection.
|
Since the various drivers we're discussing here use .so files (not just their own driver-specific ones, but also standard ones like the C library), these .so files must be present before the driver starts. Obviously, this means that the .so file cannot be on the same medium as the one you're trying to start the driver for! We recommend that you put these .so files into the image filesystem. |
The first thing you need to determine is which hardware you have controlling the disk interface. We support a number of interfaces, including various flavors of SCSI controllers and the EIDE controller. For details on the supported interface controllers, see the various devb-* entries in the Utilities Reference.
The only action required in your buildfile is to start the driver (e.g. devb-aha7). The driver will then dynamically load the appropriate modules (in this order):
The CAM .so files are documented under cam-* in the Utilities Reference. Currently, we support CD-ROMs (cam-cdrom.so), hard disks (cam-disk.so), and optical disks (cam-optical.so).
The io-blk.so module is responsible for dealing with a disk on a block-by-block basis. It includes caching support.
The fs-* modules are responsible for providing the high-level knowledge about how a particular filesystem is structured. We currently support the following:
| Filesystem | Module |
|---|---|
| ISO-9660 CD-ROM | fs-cd.so |
| CIFS (Common Internet File System) | fs-cifs |
| MS-DOS | fs-dos.so |
| Linux | fs-ext2.so |
| NFS (Network File System) | fs-nfs2, fs-nfs3 |
| Neutrino Package Filesystem | fs-pkg |
| QNX4 | fs-qnx4.so |
To run a flash filesystem, you need to select the appropriate flash driver for your target system. For details on the supported flash drivers, see the various devf-* entries in the Utilities Reference.
|
The devf-generic flash driver that can be thought of as a universal driver whose capabilities make it accessible to most flash devices. |
The flash filesystem drivers don't rely on any flash-specific .so files, so the only module required is the standard C library (libc.so).
Since the flash filesystem drivers are written for specific target systems, you can usually start them without command-line options; they'll find the flash for the specific system they were written for.
Network services are started from the io-net command, which is responsible for loading in the required .so files.
|
For dynamic control of network drivers, you can simply use
mount and umount to start and stop
drivers at the command line. For example:
mount -T io-net devn-ne2000.so For more information, see mount in the Utilities Reference. |
Two levels of .so files are started, based on the command-line options given to io-net:
The -d option lets you choose the hardware driver that knows how to talk to a particular card. For example, choosing -d ne2000 will cause io-net to load devn-ne2000.so to access an NE-2000-compatible network card. You may specify additional command-line options after the -d, such as the interrupt vector to be used by the card.
The -p option lets you choose the protocol driver that deals with a particular protocol. For example, choosing -p ttcpip will cause io-net to load npm-ttcpip.so, which will provide the tiny TCP/IP stack. As with the -d option, you would specify command-line options after the -p for the driver, such as the IP address for a particular interface.
For more information about network services, see the devn-*, io-net, and npm-* entries in the Utilities Reference.
We support two types of network filesystems:
|
The CIFS protocol makes no attempt to conform to POSIX. |
Although NFS is primarily a UNIX-based filesystem, you may find some versions of NFS available for Windows.
There's nothing special required to run your applications. Generally, they'll be placed in the script file after all the other drivers have started. If you require a particular driver to be present and "ready," you would typically use the waitfor command in the script.
Here's an example. An application called peelmaster needs to wait for a driver (let's call it driver-spud) to be ready before it should start. The following sequence is typical:
driver-spud & waitfor /dev/spud peelmaster
This causes the driver (driver-spud) to be run in the background (specified by the ampersand character). The expectation is that when the driver is ready, it will register the pathname /dev/spud. The waitfor command tries to stat() the pathname /dev/spud periodically, blocking execution of the script until the pathname appears or a predetermined timeout has occurred. Once the pathname appears in the pathname space, we assume that the driver is ready to accept requests. At that point, the waitfor will unblock, and the next program in the list (in our case, peelmaster) will execute.
Without the waitfor command, the peelmaster program would run immediately after the driver was started, which could cause peelmaster to miss the /dev/spud pathname and fail.
When you're developing embedded systems under some operating systems, you often need to use a hardware debugger, a physical device that connects to target hardware via a JTAG (Joint Test Action Group) interface. This is necessary for development of drivers, and possibly user applications, because they're linked into the same memory space as the kernel. If a driver or application crashes, the kernel and system may crash as a result. This makes using software debuggers difficult, because they depend on a running system.
Debugging target systems with Neutrino is different because its architecture is significantly different from other embeddable realtime operating systems:
Under Neutrino, you typically use:
In other words, you rarely have to use a JTAG hardware debugger, especially if you're using one of our board support packages.
We provide a software debugging agent called pdebug that makes it easier for you to debug system drivers and user applications. The pdebug agent runs on the target system and communicates with the host debugger over a serial or Ethernet connection.
For more information, see "The process-level debug agent" in the Compiling and Debugging chapter of the Programmer's Guide.
The major constraint of using pdebug is that the kernel must already be running on the target. In other words, you can't use pdebug until the IPL and startup have successfully started the kernel.
However, the IPL and startup program run with the CPU in physical mode, so you can use conventional hardware debuggers to debug them. This is the primary function of the JTAG debugger throughout the Neutrino software development phase. You use the hardware debugger to debug the BSP (IPL and startup), and pdebug to debug drivers and applications once the kernel is running. You can also use a hardware debugger to examine registers and view memory while the kernel and applications are running, if you know the physical addresses.
If hardware debuggers, such as SH or AMC have builtin Neutrino awareness, you can use a JTAG to debug applications. These debuggers can interpret kernel information as well as perform the necessary translation between virtual and physical memory addresses to view application data.
You can use hardware debuggers to debug Neutrino IPL and startup programs without any extra information. However, in this case, you're limited to assembly-level debugging, and assembler symbols such as subroutine names aren't visible. To perform full source-level debugging, you need to provide the hardware debugger with the symbol information and C source code.
This section describes the steps necessary to generate the symbol and debug information required by a hardware debugger for source-level debugging. The steps described are based on the PPC (PowerPC) Board Support Package available for Neutrino 6.3.0 for both IPL and startup of the Motorola Sandpoint MPC750 hardware reference platform.
The examples below are described for a Neutrino 6.3.0 self-hosted environment, and assume that you're logged in on the development host with root privileges.
To generate symbol information for the IPL, you must recompile both the IPL library and the Sandpoint IPL with debug information. The general procedure is as follows:
|
Be sure to synchronize the source code, the IPL burned into flash, and the IPL debug symbols. |
To build the IPL library with debug information:
# cd bsp_working_dir/src/hardware/ipl/lib/ppc/a.be # make clean # make CCOPTS=-g # cp libipl.a bsp_working_dir/sandpoint/install/ppcbe/lib # make install
The above steps recompile the PowerPC IPL library (libipl.a) with DWARF debug information and copy this library to the Sandpoint install directory. The Sandpoint BSP is configured to look for this library first in its install directory. The make install is optional, and copies libipl.a to /ppcbe/usr/lib.
The Sandpoint BSP has been set up to work with SREC format files. However, to generate debug and symbol information to be loaded into the hardware debugger, you must generate ELF-format files.
Modify the sandpoint.lnk file to output ELF format:
# cd bsp_working_dir/sandpoint/src/hardware/ipl/boards/sandpoint
Edit the file sandpoint.lnk, changing the first lines from:
TARGET(elf32-powerpc) OUTPUT_FORMAT(srec) ENTRY(entry_vec)
to:
TARGET(elf32-powerpc) OUTPUT_FORMAT(elf32-powerpc) ENTRY(entry_vec)
You can now rebuild the Sandpoint IPL to produce symbol and debug information in ELF format. To build the Sandpoint IPL with debug information:
# cd bsp_working_dir/sandpoint/src/hardware/ipl/boards/sandpoint/ppc/be # make clean # make CCOPTS=-g
The ipl-sandpoint file is now in ELF format with debug symbols from both the IPL library and Sandpoint IPL.
|
To rebuild the BSP, you need to change the sandpoint.lnk file back to outputting SREC format. It's also important to keep the IPL that's burned into the Sandpoint flash memory in sync with the generated debug information; if you modify the IPL source, you need to rebuild the BSP, burn the new IPL into flash, and rebuild the IPL symbol and debug information. |
You can use the objdump utility to view the ELF information. For example, to view the symbol information contained in the ipl-sandpoint file:
# objdump -t ipl-sandpoint | less
You can now import the ipl-sandpoint file into a hardware debugger to provide the symbol information required for debugging. In addition, the hardware debugger needs the source code listings found in the following directories:
To generate symbol information for startup, you must recompile both the startup library and the Sandpoint startup with debug information. The general procedure is as follows:
To build the startup library with debug information:
# cd bsp_working_dir/src/hardware/startup/lib/ppc/a.be # make clean # make CCOPTS=-g # cp libstartup.a bsp_working_dir/sandpoint/install/ppcbe/lib # make install
The above steps recompile the PowerPC startup library (libstartup.a) with DWARF debug information and copy this library to the Sandpoint install directory. The Sandpoint BSP is configured to look for this library first in its install directory. The make install is optional, and copies libstartup.a to /ppcbe/usr/lib.
To build the Sandpoint startup with debugging information:
# cd bsp_working_dir/sandpoint/src/hardware/startup/boards/sandpoint/ppc/be # make clean # make CCOPTS=-g # make install
The above steps generate the file startup-sandpoint with symbol and debug information. Again, you can use the -gstabs+ debug option instead of -g. The make install is necessary, and copies startup-sandpoint into the Sandpoint install directory, bsp_working_dir/sandpoint/install/ppcbe/boot/sys.
|
You can't load the startup-sandpoint ELF file into the hardware debugger to obtain the debug symbols, because the mkifs utility adds an offset to the addresses defined in the symbols according to the offset specified in the build file. |
Modify the build file to include the +keeplinked attribute for startup:
# cd bsp_working_dir/sandpoint/images
Modify the startup line of your build file to look like:
[image=0x10000]
[virtual=ppcbe,binary +compress] .bootstrap = {
[+keeplinked] startup-sandpoint -vvv -D8250
PATH=/proc/boot procnto-600 -vv
}
The +keeplinked option makes mkifs generate a symbol file that represents the debug information positioned within the image filesystem by the specified offset.
To rebuild the image to generate the symbol file:
# cd bsp_working_dir/sandpoint/images # make clean
Then, if you're using one of the provided .build files:
# make all
otherwise:
# mkifs -v -r ../install myfile.build image
These commands create the symbol file, startup-sandpoint.sym. You can use the objdump utility to view the ELF information.
To view the symbol information contained in the startup-sandpoint.sym file:
# objdump -t startup-sandpoint.sym | less
You can now import the startup-sandpoint.sym file into a hardware debugger to provide the symbol information required for debugging startup. In addition, the hardware debugger needs the source code listings found in the following directories:
|
|
|
|