![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
This chapter covers the following topics:
The Filesystem Manager (Fsys) provides a standardized means of storing and accessing data on disk subsystems. Fsys is responsible for handling all requests to open, close, read, and write files.
In QNX, a file is an object that can be written to, read from, or both. QNX implements at least six types of files; five of these are managed by Fsys:
All of these filetypes are described in detail in this chapter. The sixth filetype, the character special file, is managed by the Device Manager. Other filetypes may be managed by other managers.
Fsys maintains four different times for each file:
Access to regular files and directories is controlled by mode bits stored in the file's inode (see the section on "Links and inodes"). These bits permit read, write, and execute capability based on effective user and group IDs. There are three access qualifiers:
A process can also run with the user ID or group ID of a file rather than those of its parent process. The mechanism that allows this is referred to as setuid (set user ID on execution) and setgid (set group ID on execution).
QNX views a regular file as a randomly accessible sequence of bytes that has no other predefined internal structure. Application programs are responsible for understanding the structure and content of any specific regular file.
Regular files constitute the majority of files found in filesystems. Filesystems are supported by the Filesystem Manager and are implemented on top of the block special files that define disk partitions (see the section on "Raw volumes").
A directory is a file that contains directory entries. Each directory entry associates a filename with a file. A filename is the symbolic name that lets you identify and access a file. A file may be identified by more than one filename (see the sections on "Links and inodes" and "Symbolic links").
The following diagram shows how the directory structure is navigated to locate the file /usr/bill/file2.
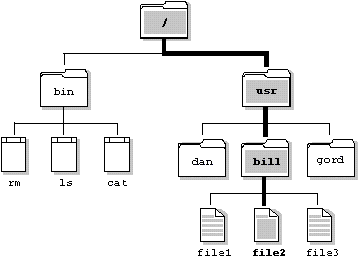
The path through the QNX directory structure to the file usr/bill/file2.
Although a directory behaves much like a standard file, the Filesystem Manager imposes some restrictions on the operations you can perform on a directory. Specifically, you can't open a directory for writing, nor can you link to a directory with the link() function.
To read directory entries, you use a set of POSIX-defined functions that provide access to directory entries in an OS-independent fashion. These functions include:
Since QNX directories are simply files that contain "known" information, you can also read directory entries directly using the open() and read() functions. This technique isn't portable, however -- the format of directory entries varies from operating system to operating system.
In QNX, regular files and directory files are stored as a sequence of extents. An extent is a contiguous set of blocks on disk.
Files that have only a single extent store the extent information in the directory entry. But if more than one extent is needed to hold the file, the extent location information is stored in one or more linked extent blocks. Each extent block can hold location information for up to 60 extents.
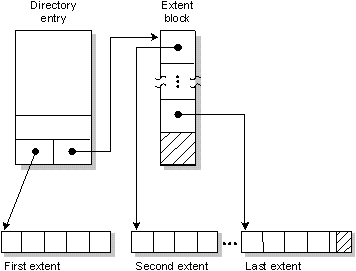
A file consisting of multiple consecutive regions on a disk -- called extents in QNX.
When the Filesystem Manager needs to extend a file whose last extent is full, it first tries to extend the last extent, even if only by one block. But if the last extent can't be extended, a new extent is allocated to extend the file.
To allocate new extents, the Filesystem Manager uses a "first fit" policy. A special table in the Filesystem Manager contains an entry for each block represented in the /.bitmap file (this file is described in the section on "Key components of a QNX partition"). Each of these entries defines the largest contiguous free extent in the area defined by its corresponding block. The Filesystem Manager chooses the first entry in this table large enough to satisfy the request for a new extent.
In QNX, file data can be referenced by more than one name. Each filename is called a link. (There are actually two kinds of links: hard links, which we refer to simply as "links," and symbolic links. Symbolic links are described in the next section.)
In order to support links for each file, the filename is separated from the other information that describes a file. The non-filename information is kept in a storage table called an inode (for "information node").
If a file has only one link (i.e. one filename), the inode information (i.e. the non-filename information) is stored in the directory entry for the file. If the file has more than one link, the inode is stored as a record in a special file named /.inodes, as are the file's directory entry points to the inode record.
Note that you can create a link to a file only if the file and the link are in the same filesystem.
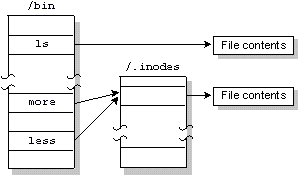
The same file is referenced by two links named "more" and "less."
There are two other situations in which a file can have an entry in the /.inodes file:
| If you want to: | Use the: |
|---|---|
| Create links from within the Shell | ln utility |
| Create links from within programs | link() function |
When a file is created, it is given a link count of one. As links to the file are added, this link count is incremented; as links are removed, the link count is decremented. The filespace isn't removed from disk until its link count goes to zero and all programs using the file have closed it. This allows an open file to remain in use, even though it has been completely unlinked.
| If you want to: | Use the: |
|---|---|
| Remove links from within the Shell | rm utility |
| Remove links from within programs | remove() or unlink() functions |
Although you can't create hard links to directories, each directory has two hard-coded links already built in:
The filename "dot" specifies the current directory; "dot dot" specifies the directory above the current one.
Note that the "dot dot" entry of "/" is simply "/" -- you can't go further up the path.
A symbolic link is a special file that has a pathname as its data. When the symbolic link is named in an I/O request -- by open(), for example -- the link portion of the pathname is replaced by the link's "data" and the path is re-evaluated. Symbolic links are a flexible means of pathname indirection and are often used to provide multiple paths to a single file. Unlike hard links, symbolic links can cross filesystems and can also create links to directories.
In the following example, the directories //1/usr/fred and //2/usr/barney are linked even though they reside on different filesystems -- they're even on different nodes (see the following diagram). This couldn't be done using hard links:
//1/usr/fred --> //2/usr/barney
Note how the symbolic link and the target directory need not share the same name. In most cases, you use a symbolic link for linking one directory to another directory. However, you can also use symbolic links for files, as in this example:
//1/usr/eric/src/test.c --> //1/usr/src/game.c
| If you want to: | Use this utility: |
|---|---|
| Create symbolic links | ln (with -s option) |
| Remove symbolic links* | rm |
| Query whether a file is a symbolic link | ls |
* Remember that removing a symbolic link acts on the link, not the target.
Several functions operate directly on the symbolic link. For these functions, the replacement of the symbolic element of the pathname with its target is not performed. These functions include unlink() (which removes the symbolic link), lstat(), and readlink().
Since symbolic links can point to directories, incorrect configurations can result in problems such as circular directory links. To recover from circular references, the system imposes a limit on the number of hops; this limit is defined as SYMLOOP_MAX in the <limits.h> include file.
A pipe is an unnamed file that serves as an I/O channel between two or more cooperating processes -- one process writes into the pipe, the other reads from the pipe. The Filesystem Manager takes care of buffering the data. The buffer size is defined as PIPE_BUF in the <limits.h> file. A pipe is removed once both of its ends have closed.
Pipes are normally used when two processes want to run in parallel, with data moving from one process to the other in a single direction. (If bidirectional communication is required, messages should be used instead.)
A typical application for a pipe is connecting the output of one program to the input of another program. This connection is often made by the Shell. For example:
ls | more
directs the standard output from the ls utility through a pipe to the standard input of the more utility.
| If you want to: | Use the: |
|---|---|
| Create pipes from within the Shell | pipe symbol ("|") |
| Create pipes from within programs | pipe() or popen() functions |
 |
On diskless workstations, you can run the Pipe Manager (Pipe) in place of the Filesystem Manager when only pipes are required. The Pipe Manager is optimized for pipe I/O and may achieve better pipe throughput than the Filesystem Manager. |
FIFOs are essentially the same as pipes, except that FIFOs are named permanent files that are stored in filesystem directories.
| If you want to: | Use the: |
|---|---|
| Create FIFOs from within the Shell | mkfifo utility |
| Create FIFOs from within programs | mkfifo() function |
| Remove FIFOs from within the Shell | rm utility |
| Remove FIFOs from within programs | remove() or unlink() function |
The Filesystem Manager has several features that contribute to high-performance disk access:
Elevator seeking minimizes the overall seek time required to read or write data from or to disk. Outstanding I/O requests are ordered such that they can all be performed with one sweep of the disk head assembly, from the lowest to the highest disk address.
Elevator seeking also has integrated enhancements to ensure that multi-sector I/O is performed whenever possible.
The buffer cache is an intelligent buffer between the Filesystem Manager and the disk driver. The buffer cache attempts to store filesystem blocks in order to minimize the number of times the Filesystem Manager has to access the disk. By default, the size of the cache is determined by total system memory, but you can specify a different size via an option to Fsys.
Read operations are synchronous. Write operations, on the other hand, are usually asynchronous. When the data enters the cache, the Filesystem Manager replies to the client process to indicate that the data is written. The data is then written to the disk as soon as possible, typically less than five seconds later.
Applications can modify write behavior on a file-by-file basis. For example, a database application can cause all writes for a given file to be performed synchronously. This would ensure a high level of file integrity in the face of potential hardware or power problems that might otherwise leave a database in an inconsistent state.
The Filesystem Manager is a multi-threaded process. That is, it can manage several I/O requests simultaneously. This allows the Filesystem Manager to fully exploit potential parallelism since it can do both of the following:
The Filesystem Manager may have its priority driven by the priority of the processes that send it messages. When the Filesystem Manager receives a message, its priority is set to that of the process that sent the message. For more information, see "Process scheduling" in Chapter 2.
QNX has a performance option for opening temporary files that are written and then reread in a short period of time. For such files, the Filesystem Manager attempts to keep the data blocks in the cache and will write the blocks to disk only if absolutely necessary.
The Filesystem Manager has an integrated ramdisk capability that allows up to 8M of memory to be used as a simulated disk. Since the Filesystem Manager uses highly efficient multipart messaging, data moves from the ramdisk directly to the application buffers.
The Filesystem Manager is able to bypass the buffer cache because the ramdisk is built in, not implemented as a driver. (For information on multipart messaging, see the section on "Advanced facilities" in Chapter 2.)
Because they eliminate the delays of physical hardware and don't rely on the filesystem cache, ramdisks provide greater determinism in read/write operations than hard disks.
The QNX filesystem achieves high throughput without sacrificing reliability. This has been accomplished in several ways.
While most data is held in the buffer cache and written after only a short delay, critical filesystem data is written immediately. Updates to directories, inodes, extent blocks, and the bitmap are forced to disk to ensure that the filesystem structure on disk is never corrupt (i.e. the data on disk should never be internally inconsistent).
Sometimes all of the above structures must be updated. For example, if you move a file to a directory and the last extent of that directory is full, the directory must grow. In such cases, the order of operations has been carefully chosen such that if a catastrophic failure occurs with the operation only partially completed (e.g. a power failure), the filesystem, upon rebooting, would still be "sane." At worst, some blocks may have been allocated, but not used. You can recover these for later use by running the chkfsys utility.
Even in the best systems, true catastrophes such as these may happen:
So that you can recover as many of your files as possible if such events ever occur, unique "signatures" have been written on the disk to aid in the automatic identification and recovery of the critical filesystem pieces. The inodes file (/.inodes), as well as each directory and extent block, all contain unique patterns of data that the chkfsys utility can use to reassemble a truly damaged filesystem.
For details on filesystem recovery, see the documentation for the chkfsys utility.
The Filesystem Manager manages block special files. These files define disks and disk partitions.
QNX considers each physical disk on a computer to be a block special file. As a block special file, a disk is viewed by a QNX filesystem as a sequential set of blocks, each 512 bytes in size, regardless of the size and capacities of the disk. Blocks are numbered, beginning with the first block on the disk (block 1).
Because each disk is a block special file, it can be opened as an entity for raw-level access using standard POSIX C functions such as open(), close(), read(), and write(). At the level of a block special file that defines an entire disk, QNX makes absolutely no assumptions about any data structure that may reside on the disk.
A computer running QNX may have one or more disk subsystems. Each disk subsystem consists of a controller and one or more disks. You start a device driver process for each disk subsystem that is to be managed by the Filesystem Manager.
QNX complies with a de facto industry standard that allows a number of operating systems to share the same physical disk. According to this standard, a partition table can define up to four primary partitions on the disk. The table is stored on the first disk block.
Each partition must be given a "type" recognized by the operating system prepared to handle that partition. The following list shows some of the partition types that are currently used:
| Type | Filesystem |
|---|---|
| 1 | DOS (12-bit FAT) |
| 4 | DOS (16-bit FAT; partitions <32M) |
| 5 | DOS Extended Partition |
| 6 | DOS 4.0 (16-bit FAT; partitions >=32M) |
| 7 | OS/2 HPFS |
| 7 | Previous QNX version 2 (pre-1988) |
| 8 | QNX 1.x and 2.x ("qny") |
| 9 | QNX 1.x and 2.x ("qnz") |
| 11 | DOS 32-bit FAT; partitions up to 2047G |
| 12 | Same as Type 11, but uses Logical Block Address Int 13h extensions |
| 14 | Same as Type 6, but uses Logical Block Address Int 13h extensions |
| 15 | Same as Type 5, but uses Logical Block Address Int 13h extensions |
| 77 | QNX POSIX partition |
| 78 | QNX POSIX partition (secondary) |
| 79 | QNX POSIX partition (secondary) |
| 99 | UNIX |
If you want more than one QNX 4.x partition on a single physical disk, you would use type 77 for your first QNX partition, type 78 for your second QNX partition, and type 79 for your third QNX partition. You can use other types for your second and third partitions, but 78 and 79 are preferred. To mark any of these partitions as bootable, you use the fdisk utility.
At boot time, the QNX boot loader (optionally installed by fdisk) lets you override the default boot partition selection in the partition table.
You can use the fdisk utility to create, modify, or delete partitions.
Because QNX treats each partition on a disk as a block special file, you can access either of the following:
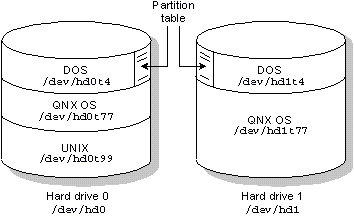
Two physical disk drives. The first drive contains DOS, QNX, and UNIX partitions. The second has DOS and QNX partitions.
The names of all block special files are placed in the prefix tree for the computer where the block special files reside (the prefix tree is described in Chapter 3, I/O Namespace). When a device driver for a disk subsystem is started, the Filesystem Manager automatically registers prefixes that define a block special file for each physical drive attached to the disk subsystem. The mount utility is then used to register a prefix for a block special file for each partition on the disk subsystem.
For example, let's say you have a standard IDE interface with two attached drives. On one drive, you want to mount a DOS partition, a QNX partition, and a UNIX partition. On the other drive, you want to mount a DOS partition and a QNX partition.
The Filesystem Manager would define the block special files /dev/hd0 and /dev/hd1 for the two drives on the controller where the driver was started.
You would then use the mount utility to define a block special file for each partition. For example:
mount -p /dev/hd0 -p /dev/hd1
would yield the following block special files:
| OS partition: | Block special file: |
|---|---|
| DOS partition on drive hd0 | /dev/hd0t4 |
| QNX partition on drive hd0 | /dev/hd0t77 |
| UNIX partition on drive hd0 | /dev/hd0t99 |
| DOS partition on drive hd1 | /dev/hd1t4 |
| QNX partition on drive hd1 | /dev/hd1t77 |
Note that the tn convention is used to refer to disk partitions used by certain operating systems. For example a DOS partition is t4, a UNIX partition is t99, etc.
You typically mount a QNX filesystem on a block special file. To mount a filesystem, you again use the mount utility -- it lets you specify the prefix that identifies the filesystem. For example:
mount /dev/hd0t77 /
mounts a filesystem with a prefix of / on the partition defined by the block special file named hd0t77.
|
If a disk has been partitioned, you must mount a partition block special file (e.g. /dev/hd0t77 that defines a QNX 4.x partition, not the base block special file that defines the entire raw disk (e.g. /dev/hd0. If you attempt to mount the base block special file for the entire disk, you'll get a "corrupt filesystem" message when you try to access the filesystem. |
To unmount a filesystem you use the umount utility. For example, the following command will unmount the filesystem on your primary QNX partition:
umount /dev/hd0t77
Once a filesystem is unmounted, files on that partition are no longer accessible.
Several key components found at the beginning of every QNX partition tie the filesystem together:
These structures are created when you initialize the filesystem with the dinit utility.
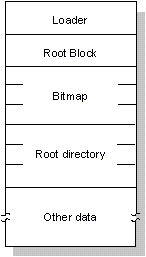
Structure of a QNX filesystem within a disk partition.
This is the first physical block of a disk partition. This block contains the code that is loaded and then executed by the BIOS of the computer to load an operating system from the partition. If a disk hasn't been partitioned (e.g. as in a floppy diskette), this block is the first physical block on the disk.
The root block is structured as a standard directory. It contains inode information for these four special files:
The files /.boot and /.altboot contain images of the operating system that can be loaded by the QNX bootstrap loader.
Normally, the QNX loader loads the OS image stored in the /.boot file. But if the /.altboot file isn't empty, you'll be given the option to load the image stored in the /.altboot file.
To allocate space on a disk, QNX uses a bitmap stored in the /.bitmap file. This file contains a map of all the blocks on the disk, indicating which blocks are used. Each block is represented by a bit. If the value of a bit is 1, its corresponding block on the disk is being used.
The root directory of a partition behaves as a normal directory file with two exceptions:
In QNX, the I/O namespace is managed through prefixes that direct file requests to the appropriate manager process. A process that takes advantage of this is the DOS Filesystem Manager (Dosfsys). Dosfsys administers the /dos namespace prefix and presents DOS drives within the QNX namespace as "guest" filesystems.
Dosfsys provides transparent access to DOS disks, so you can treat DOS filesystems as though they were QNX filesystems. This transparency allows processes to operate on DOS files without any special knowledge or work on their part. Standard I/O library functions, such as open(), close(), read(), and write(), operate identically for a file on a DOS partition as for a file on a QNX partition. For example, to copy a file from your QNX partition to your DOS partition, you would simply enter:
cp /usr/luc/file.dat /dos/c/file.dat
Note that /dos/c is the pathname of the DOS drive C. The cp command contains no special code to detect whether the file it's copying is located on a DOS disk. Other commands also work with equal transparency (e.g. cd, ls, mkdir).
If there's no DOS equivalent to a QNX feature, such as mkfifo() or link(), an appropriate error code (i.e. errno) is returned by Dosfsys.
Dosfsys works both with floppies and with hard disk partitions. All of the low-level disk access that Dosfsys requires is done using standard functions provided by the Filesystem Manager. Thus, with no low-level code, Dosfsys is able to integrate a seamless interface between QNX applications and a DOS filesystem.
The CD-ROM Filesystem, Iso9660fsys, provides transparent access to CD-ROM media, so you can treat CD-ROM filesystems as though they were POSIX filesystems. This transparency allows processes to operate on CD-ROM files without any special knowledge or work on their part.
Iso9660fsys implements the ISO 9660 standard, including Rock Ridge extensions. DOS and Windows Compact Discs follow this standard. In addition to normal files, Iso9660fsys also supports audio.
The Flash filesystem manager, Efsys.*, was explicitly designed to work with Flash memory, whether built-in or removable. Files written to removable Flash media (PC-Card cards) are portable to other systems that also support this standard.
Efsys.* combines the functions of a filesystem manager and a device driver to manage a Flash filesystem on memory-based media. Because Efsys.* includes the device driver for controlling the hardware, there are separate versions of Efsys.* for different embedded systems hardware. For example:
The functionality of the filesystem is restricted by the memory devices used. For example, if the medium contains ROM devices only, the filesystem is read-only.
Memory-based Flash devices have restrictions on file writing. You can only append to the file. In addition, file access times aren't updated. Currently, these restrictions apply even if devices such as SRAM are used.
Efsys.* stores directories and files using linked lists of data structures, rather than the fixed-size disk blocks used in traditional rotating-medium filesystems. When a directory or file is deleted, the data structures representing it are marked as deleted, but aren't removed. This avoids continuously erasing and rewriting the medium.
Eventually, the medium will run out of free space and the filesystem manager will perform space reclamation (or "garbage collection"). During this process, Efsys.* recovers the space occupied by deleted files and directories. To perform space reclamation, the filesystem manager requires at least one spare block on the medium. The mkffs utility automatically reserves one spare block when you make a filesystem.
Efsys.* supports decompression, which increases the amount of data that can be stored on a medium. Decompression operates transparently to applications.
For files to be decompressed transparently by the filesystem manager, you must compress them explicitly before using mkffs. You do this with the bpe utility. If you copy a compressed file to a live Flash filesystem, it will remain compressed when it's read from the filesystem.
If you disable the POSIX extensions, file ownership is permanently set to root and all permissions are set to rwx. The chgrp, chmod, and chown commands won't work.
You can set mountpoints only when initializing the partitions or when starting the filesystem manager.
When you start Efsys.*, it creates a special device file in the /dev directory for each medium. In a system with two memory-based media, Efsys.* would create the special files /dev/skt1 and /dev/skt2. The special device ignores the partitioning, allowing raw device access to the medium.
An image filesystem partition can be accessed only as a raw device. For each image filesystem partition, Efsys.* creates a special file in the format /dev/sktXimgY, where X is the medium socket number and Y is the number of the image filesystem partition in that medium.
Originally developed by Sun Microsystems, the Network File System (NFS) is a TCP/IP application that has since been implemented on most DOS and Unix systems. You should find the QNX implementation invaluable for transparently accessing filesystems on other operating systems that support NFS.
|
QNX inherently supports networked filesystems. You need to use NFS only if you're accessing non-QNX NFS filesystems, or if you want to let NFS clients access your QNX namespace. |
NFS lets you graft remote filesystems -- or portions of them -- onto your local namespace. Directories on the remote systems appear as part of your local filesystem and all the utilities you use for listing and managing files (e.g. ls, cp, mv) operate on the remote files exactly as they do on your local files.
|
In QNX 4, NFS requires the Socket manager, which implements the networking protocols used in TCP/IP for QNX. Note that a "lighter" version of the socket manager, known as Socklet, is also available if you don't need NFS. |
SMBfsys implements the SMB (Server Message Block) file-sharing protocol, which is used by a number of different servers such as Windows NT, Windows 95, Windows for Workgroups, LAN Manager, and Samba. SMBfsys allows a QNX client to transparently access remote drives residing on such servers.
SMBfsys implements this protocol using NetBIOS on TCP/IP only, not NetBEUI. Accordingly, you need TCP/IP installed on both the QNX and remote server side. Once SMBfsys is running and a remote server has been mounted, the server's filesystem appears in the local directory structure.
|
|
|
|