This appendix includes:
If you need to gather information about the processes running on your
machine, you can use the /proc filesystem.
Although there's a section about it in the
Processes chapter of the
QNX Neutrino Programmer's Guide,
this filesystem isn't understood very well.
This appendix describes the main features of the /proc filesystem
so you can use it in your own utilities.
First of all, the /proc filesystem is a virtual filesystem — it doesn't actually exist
on disk; it exists only as a figment of the process manager's imagination.
The /proc filesystem contains a number of entities:
- directories, one per process, for every process running in the system
- the boot subdirectory — a “mini” filesystem that contains the files from the startup image
- the (hidden) mount subdirectory.
Our main focus in this chapter is the first item, the directories describing each process in the system.
We'll describe the functions available to get information about the processes (and their threads).
For completeness, however, we'll just briefly mention the other two items.
By default, the files from the startup image are placed into a read-only filesystem mounted at /, in a directory called /proc/boot.
In a tiny embedded system, for example, this might be used to hold configuration files, or other data files,
without the need for a full-blown filesystem manager, and also without the need for additional storage.
You can get more information about this by looking at the mkifs command in your Neutrino documentation set.
This one is actually pretty neat.
When I say that this filesystem is hidden, I mean that when you do an ls of /proc,
the mount directory doesn't show up.
But you can certainly cd into it and look at its contents.
There are two main types of entities:
- directories with names that are comma-separated numbers
- directories with names corresponding to mounted (i.e., resmgr_attach()'d) entities
This is what /proc/mount looks like on my system:
# ls /proc/mount
ls: No such file or directory (/proc/mount/0,8,1,0,0)
ls: No such file or directory (/proc/mount/0,1,1,2,-1)
0,1,1,10,11/ 0,344083,1,0,11/ 0,6,7,10,0/ proc/
0,1,1,11,0/ 0,360468,1,0,11/ 0,8,1,1,0/ usr/
0,1,1,3,-1/ 0,393228,4,0,11/ dev/
0,12292,1,0,6/ 0,4105,1,0,4/ fs/
0,12292,1,1,8/ 0,6,7,0,11/ pkgs/
Each “numbered” directory name (e.g. 0,344083,1,0,11) consists
of five numbers, separated by commas.
The numbers are, in order:
- node ID,
- process ID,
- channel ID,
- handle, and
- file type.
The node ID is usually zero, indicating “this node.”
The process ID is that of the process.
The channel ID is the number of the channel created via ChannelCreate().
Finally, the handle is an index describing which resmgr_attach() this is.
The last number is the file type (see <sys/ftype.h> for values and meanings).
Together, these five numbers describe a pathname prefix that has been registered in the pathname
space.
The other, “normal” directories are the actual registered paths.
If we examine a random one, say /proc/mount/dev, we'll see directories
corresponding to each of the registered mount points under /dev.
You may be wondering why they are directories, and not the actual devices.
That's because you can register the same pathname multiple times.
Recall that in the
High Availability
chapter we said that in order to achieve
hot-standby mode, we'd want to register two resource managers at the same mount point —
the one “in front” would be the active resource manager, the one registered
“behind” would be the standby resource manager.
If we did this, we'd have two sets of numbers in the subdirectory corresponding to the named device.
For example, currently we have one resource manager managing the serial ports:
# ls /proc/mount/dev/ser1
0,344080,1,0,0
If we had a hot-standby serial port driver (we don't, but play along) the directory listing might
now look something like:
# ls /proc/mount/dev/ser1
0,344080,1,0,0 0,674453,1,0,0
The process ID 344080 is the active serial port driver, and the process ID 674453
is the standby serial port driver.
The order of the pathname resolution is given by the order that the entries are returned by the readdir()
function call.
This means that it's not immediately apparent via the ls above which process is resolved first
(because by default, ls sorts alphabetically by name),
but by calling ls with the -S (“do not sort” option) the order can be
determined.
In the main portion of this appendix, we'll look at the format, contents, and functions you can use
with the remainder of the /proc filesystem.
You may wish to have the <sys/procfs.h>, <sys/syspage.h>, and <sys/debug.h> header
files handy — I'll show important pieces as we discuss them.
A casual ls of /proc yields something like this, right now on my system:
# ls -F /proc
1/ 12292/ 3670087/ 6672454/ 950306/
1011730/ 2/ 3670088/ 6676553/ 950309/
1011756/ 3/ 393228/ 7/ 950310/
1011757/ 344077/ 405521/ 7434315/ 950311/
1011760/ 344079/ 4105/ 7462988/ 950312/
1011761/ 344080/ 442378/ 7467085/ 950313/
1011762/ 344083/ 45067/ 7499854/ 950314/
1011764/ 3551288/ 466965/ 770071/ 950315/
1011769/ 3551294/ 471062/ 8/ 950318/
1011770/ 3571775/ 479246/ 815133/ 950319/
1011773/ 360468/ 4886602/ 831519/ boot/
1015863/ 3608627/ 5/ 831520/ dumper#
1036347/ 3608629/ 548888/ 868382/ self/
1040448/ 3629116/ 593947/ 868387/
1044547/ 3629121/ 6/ 868388/
1044548/ 3649602/ 622620/ 950298/
1093686/ 3649605/ 626713/ 950305/
We've discussed the boot entry above.
The dumper entry is a hook for dumper (the system core dump utility).
Finally, self is a short-form for the current process
(in this case, ls).
The individual numbered directories are more interesting.
Each number is a process ID.
For example, what is process ID 4105?
Doing the following:
# pidin -p4105
pid tid name prio STATE Blocked
4105 1 sbin/pipe 10o RECEIVE 1
4105 2 sbin/pipe 10o RECEIVE 1
4105 4 sbin/pipe 10o RECEIVE 1
4105 5 sbin/pipe 10o RECEIVE 1
shows us that process ID 4105 is the pipe process.
It currently has four threads (thread IDs 1, 2, 4 and 5 —
thread ID 3 ran at some point and died, that's why it's not shown).
Within the /proc directory, doing a:
# ls -l 4105
total 2416
-rw-r--r-- 1 root root 1236992 Aug 21 21:25 as
shows us a file called as (not in the sense of “as if...” but as an abbreviation for address space).
This file contains the addressable address space of the entire process.
The size of the file gives us the size of the addressable address space, so we can see that pipe is
using a little under one and a quarter megabytes of address space.
To further confuse our findings, here's:
# pidin -p4105 mem
pid tid name prio STATE code data stack
4105 1 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
4105 2 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
4105 4 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
4105 5 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
ldqnx.so.2 @b0300000 312K 16K
If you do the math (assuming the stack is 4096 bytes, as indicated) you
come up with:
16 KB + 148 KB + 4 x 132 KB + 312 KB + 16 KB
Or 1020 KB (1,044,480 bytes), which is short by 192,512 bytes.
You'll notice that the sizes don't match up!
That's because the as file totals up all the segments
that have the MAP_SYSRAM flag on in them and uses that as the
size that it reports for a stat().
MAP_SYSRAM can't be turned on by the user
in mmap(), but it indicates that the system allocated
this piece of memory (as opposed to the user specifying a direct
physical address with MAP_PHYS), so when the memory no longer has
any references to it, the system should free the storage (this
total includes memory used by any shared objects that the process
has loaded).
The code in pidin that calculates the pidin mem
sizes is, to put it nicely, a little convoluted.
Given that the as entry is the virtual address space of the process,
what can we do with it?
The as entity was made to look like a file so that
you could perform file-like functions on it (read(), write(),
and lseek()).
For example, if we call lseek() to seek to location 0x80001234, and then
call read() to read 4 bytes, we have effectively read 4 bytes from the
process's virtual address space at 0x80001234. If we then print out this value,
it would be equivalent to doing the following code within that process:
…
int *ptr;
ptr = (int *) 0x80001234;
printf ("4 bytes at location 0x80001234 are %d\n", *ptr);
However, the big advantage is that we can read the data in another process's address space
by calling lseek() and read().
The address space within the entry is discontiguous, meaning that there are “gaps”
in the “file offsets.”
This means that you will not be able to lseek() and then read() or write() to arbitrary locations
— only the locations that are valid within the address space of that process.
This only makes sense, especially when you consider that the process itself has access to only the “valid” portions
of its own address space — you can't construct a pointer to an arbitrary location and expect it to work.
Which brings us to our next point.
The address space that you are dealing with is that of the process under examination, not your own.
It is impossible to map that process's address space on a one-to-one basis into your own (because of
the potential for virtual address conflicts), so you must use lseek(),
read() and write() to access this memory.
 |
The statement about not being able to mmap() the process's address space to your own is true right now (as of version 6.2.1),
but eventually you will be able to use that file as the file descriptor in mmap() (it'll be allowed
as a memory-mapped file).
My sources at QSSL indicate that this is not in the “short term” plan, but something that might
appear in a future version. |
Why is it impossible to map it on a one-to-one basis?
Because the whole point of virtual addressing is that multiple processes could have
their own, independent address spaces.
It would defeat the purpose of virtual addressing if, once a process was assigned a certain address range, that
address range then became unavailable for all other processes.
Since the reason for mapping the address space of the other process to your own would be to use the other process's pointers “natively,”
and since that's not possible due to address conflicts, we'll just stick with the file operations.
Now, in order to be able to read “relevant portions” of the process's address space, we're going to
need to know where these address ranges actually are.
There are a number of devctl()'s that are used in this case
(we'll see these shortly).
Generally, the first thing you need to do is select a particular process (or some set of processes) to perform
further work on.
Since the /proc filesystem contains process IDs, if you already know the process ID, then your
work is done, and you can continue on to the next step
(see “Iterating through the list of processes” below).
However, if all you know is the name of the process, then you need to search through the list of process IDs,
retrieve the names of each process, and match it against the process name you're searching for.
There may be criteria other than the name that you use to select your particular process.
For example, you may be interested in processes that have more than six threads, or processes that have threads in a particular
state, or whatever.
Regardless, you will still need to iterate through the process ID list and select your process(es).
Since the /proc filesystem looks like a normal filesystem, it's appropriate to use the filesystem
functions opendir() and readdir() to iterate through the process IDs.
The following code sample illustrates how to do this:
void
iterate_processes (void)
{
struct dirent *dirent;
DIR *dir;
int r;
int pid;
// 1) find all processes
if (!(dir = opendir ("/proc"))) {
fprintf (stderr, "%s: couldn't open /proc, errno %d\n",
progname, errno);
perror (NULL);
exit (EXIT_FAILURE);
}
while (dirent = readdir (dir)) {
// 2) we are only interested in process IDs
if (isdigit (*dirent -> d_name)) {
pid = atoi (dirent -> d_name);
iterate_process (pid);
}
}
closedir (dir);
}
At this point, we've found all valid process IDs.
We use the standard opendir() function in step 1 to open the /proc filesystem.
In step 2, we read through all entries in the /proc filesystem, using the standard
readdir().
We skip entries that are nonnumeric — as discussed above, there are other things in the /proc filesystem
besides process IDs.
Next, we need to search through the processes generated by the directory functions to see which ones match our criteria.
For now, we'll just match based on the process name — by the end of this appendix, it will be apparent
how to search based on other criteria (short story: ignore the name, and search for your other criteria in a later step).
void
iterate_process (int pid)
{
char paths [PATH_MAX];
int fd;
// 1) set up structure
static struct {
procfs_debuginfo info;
char buff [PATH_MAX];
} name;
sprintf (paths, "/proc/%d/as", pid);
if ((fd = open (paths, O_RDONLY)) == -1) {
return;
}
// 2) ask for the name
if (devctl (fd, DCMD_PROC_MAPDEBUG_BASE, &name,
sizeof (name), 0) != EOK) {
if (pid == 1) {
strcpy (name.info.path, "(procnto)");
} else {
strcpy (name.info.path, "(n/a)");
}
}
// 3) we can compare against name.info.path here...
do_process (pid, fd, name.info.path);
close (fd);
}
In step 1, we set up an extension to the procfs_debuginfo data structure.
The buff buffer is implicitly past the end of the structure, so it's natural to set it up this way.
In step 2, we ask for the name, using DCMD_PROC_MAPDEBUG_BASE.
|
Note that some versions of Neutrino didn't provide a “name” for the process manager.
This is easy to work around, because the process manager is always process ID 1. |
Just before step 3 is a good place to compare the name against whatever it was you're looking for.
By not performing any comparison, we match all names.
If the name matches
(or for all processes, as shown in the code above),
we can call do_process(), which will now work on the process.
Notice that we pass do_process() the opened file descriptor, fd, to save on having to
reopen the as entry again in do_process().
Once we've identified which process we're interested in, one of the first things we need to do is find information about the process.
(We'll look at how to get information about the threads in a process shortly.)
There are six devctl() commands that deal with processes:
- DCMD_PROC_MAPDEBUG_BASE
- Returns the name of the process (we've used this one above, in iterate_process()).
- DCMD_PROC_INFO
- Returns basic information about the process (process IDs, signals, virtual addresses, CPU usage).
- DCMD_PROC_MAPINFO and DCMD_PROC_PAGEDATA
- Returns information about various chunks (“segments,” but not to be confused with x86 segments) of memory.
- DCMD_PROC_TIMERS
- Returns information about the timers owned by the process.
- DCMD_PROC_IRQS
- Returns information about the interrupt handlers owned by the process.
Other devctl() commands deal with processes as well, but they're used for control operations rather than fetching information.
The following information is readily available about the process via the DCMD_PROC_INFO devctl() command:
typedef struct _debug_process_info {
pid_t pid;
pid_t parent;
uint32_t flags;
uint32_t umask;
pid_t child;
pid_t sibling;
pid_t pgrp;
pid_t sid;
uint64_t base_address;
uint64_t initial_stack;
uid_t uid;
gid_t gid;
uid_t euid;
gid_t egid;
uid_t suid;
gid_t sgid;
sigset_t sig_ignore;
sigset_t sig_queue;
sigset_t sig_pending;
uint32_t num_chancons;
uint32_t num_fdcons;
uint32_t num_threads;
uint32_t num_timers;
uint64_t start_time; // Start time in ns
uint64_t utime; // User running time in ns
uint64_t stime; // System running time in ns
uint64_t cutime; // terminated children user time in ns
uint64_t cstime; // terminated children user time in ns
uint8_t priority; // process base priority
} debug_process_t;
This information is filled into the debug_process_t structure by issuing the DCMD_PROC_INFO devctl().
Note that the debug_process_t is the same type as procfs_info (via a typedef in <sys/procfs.h>).
To get this structure:
void
dump_procfs_info (int fd, int pid)
{
procfs_info info;
int sts;
sts = devctl (fd, DCMD_PROC_INFO, &info, sizeof (info), NULL);
if (sts != EOK) {
fprintf(stderr, "%s: DCMD_PROC_INFO pid %d error %d (%s)\n",
progname, pid, sts, strerror (sts));
exit (EXIT_FAILURE);
}
// structure is now full, and can be printed, analyzed, etc.
...
}
As an example, we'll stick with the pipe process.
Here are the contents of the procfs_info structure for the pipe process:
PROCESS ID 4105
Info from DCMD_PROC_INFO
pid 4105
parent 2
flags 0x00000210
umask 0x00000000
child 0
sibling 8
pgrp 4105
sid 1
base_address 0x0000000008048000
initial_stack 0x0000000008047F18
uid 0
gid 0
euid 0
egid 0
suid 0
sgid 0
sig_ignore 0x06800000-00000000
sig_queue 0x00000000-FF000000
sig_pending 0x00000000-00000000
num_chancons 4
num_fdcons 3
num_threads 4
num_timers 0
start_time 0x0EB99001F9CD1EF7
utime 0x0000000016D3DA23
stime 0x000000000CDF64E8
cutime 0x0000000000000000
cstime 0x0000000000000000
priority 10
Let's look at the various fields that are present here.
The pid, parent, child, and sibling fields tell us the relationship
of this process to other processes.
Obviously, pid is the process ID of the process itself, and parent is the process ID of
the process that created this one.
Where things get interesting is the child and sibling entries.
Let's take an example of a process P that created processes A, B,
and C.
Process P is the parent of A, B and C, thus we'd
expect that the parent field would contains the process ID for process P (in each
of the three children processes).
However, you'll notice that the child member is a scalar, and not an array as you may have
been expecting.
This means that P's children are listed as a child/sibling relationship, rather than an
array of children.
So, it may be the case that P's child member is the process ID for process A,
and the other children, B and C are listed as siblings (in the sibling
member) of each other.
So, instead of:
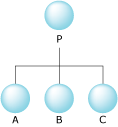
A parent/child relationship.
we'd see a relationship more like:
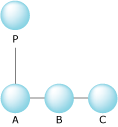
A parent/child/sibling relationship.
It's the same, hierarchically speaking, except that we've avoided having to keep an array of children.
Instead, we have each of the children point to a sibling, thus forming a list.
Additional process information provided is the process group (pgrp), session ID (sid),
and the usual extended user and group information (uid, gid, euid, egid,
suid, and sgid).
The process's base priority is provided in the priority member.
Note that, practically speaking, a process doesn't really have a priority — since threads are the
actual schedulable entities, they will be the ones that “actually” have a priority.
The priority given here is the default priority that's assigned to the process's first thread when
the process started.
New threads that are started can inherit the priority of the creating thread, have a different
priority set via the POSIX thread attributes structure, or can change their priority later.
Finally, the number of threads (num_threads) is provided.
Basic memory information is provided by the base_address and initial_stack members.
Remember, these are the virtual addresses used by the process, and have no meaning for any other process,
nor are they (easily) translatable to physical addresses.
Three fields relating to signals are provided: sig_ignore, sig_queue, and sig_pending,
representing, respectively, the signals that this process is ignoring, the signals that are enqueued on this process,
and the signals that are pending.
A signal is one of these “weird” things that has both a “process” and a “thread”
facet — the fields mentioned here are for the “process” aspect.
Note also that the signals are stored in a sigset_t.
Neutrino implements the sigset_t as an array of two long integers; that's why
I've shown them as a 16-digit hexadecimal number with a dash between the two 32-bit
halves.
Another nice thing that's stored in the structure is a set of CPU usage (and time-related) members:
- start_time
- The time, in nanoseconds since January 1, 1970, when the process was started.
- utime
- The number of nanoseconds spent running in user space (see below).
- stime
- The number of nanoseconds spent running in system space (see below).
- cutime and cstime
- Accumulated time that terminated children have run, in nanoseconds, in user and system space.
The start_time is useful not only for its obvious “when was this process started” information,
but also to detect reused process IDs.
For example, if a process ID X is running and then dies, eventually the same process ID (X)
will be handed out to a new (and hence completely different) process.
By comparing the two process's start_time members, it's possible to determine that the process ID has
in fact been reused.
The utime and stime values are calculated very simply — if the processor is
executing in user space when the timer tick interrupt occurs, time is allocated to the utime
variable; otherwise, it's allocated to the stime variable.
The granularity of the time interval is equivalent to the time tick (e.g. 1 millisecond on an x86 platform
with the default clock setting).
There are a few other miscellaneous members:
- flags
- Process flags, defined as _NTO_PF_* in <sys/neutrino.h>.
For descriptions of them see the entry for
pidin
in the Utilities Reference.
- umask
- The umask file mode mask used for creating files.
- num_chancons
- The number of connected channels.
- num_fdcons
- The number of connected file descriptors.
- num_timers
- The number of timers in use.
The next thing that we can do with a process is look at the memory segments that it has in use.
There are two devctl() commands to accomplish this: DCMD_PROC_MAPINFO and
DCMD_PROC_PAGEDATA.
Both commands use the same data structure (edited for clarity):
typedef struct _procfs_map_info {
uint64_t vaddr;
uint64_t size;
uint32_t flags;
dev_t dev;
off_t offset;
ino_t ino;
} procfs_mapinfo;
The original data structure declaration has #ifdef's for 32 versus 64 bit sizes of the offset and ino members.
The procfs_mapinfo is used in its array form, meaning that we must allocate sufficient space for all of the memory segments that we will be getting information about.
Practically speaking, I've managed just fine with 512 (MAX_SEGMENTS) elements.
When I use this call in code, I compare the number of elements available (returned by the devctl() function) and ensure that it is less than the constant MAX_SEGMENTS.
In the unlikely event that 512 elements are insufficient, you can allocate the array dynamically and reissue the devctl() call with a bigger buffer.
In practice, the 10 to 100 element range is sufficient; 512 is overkill.
Here's how the call is used:
#define MAX_SEGMENTS 512
void
dump_procfs_map_info (int fd, int pid)
{
procfs_mapinfo membufs [MAX_SEGMENTS];
int nmembuf;
int i;
int sts;
// fetch information about the memory regions for this pid
sts = devctl (fd, DCMD_PROC_PAGEDATA, membufs, sizeof (membufs),
&nmembuf);
if (sts != EOK) {
fprintf(stderr, "%s: PAGEDATA process %d, error %d (%s)\n",
progname, pid, sts, strerror (sts));
exit (EXIT_FAILURE);
}
// check to see we haven't overflowed
if (nmembuf > MAX_SEGMENTS) {
fprintf (stderr, "%s: proc %d has > %d memsegs (%d)!!!\n",
progname, pid, MAX_SEGMENTS, nmembuf);
exit (EXIT_FAILURE);
}
for (i = 0; i < nmembuf; i++) {
// now we can print/analyze the data
}
}
Here's the output for the pipe process (I've added blank lines for clarity):
Info from DCMD_PROC_PAGEDATA
Buff# --vaddr--- ---size--- ---flags-- ---dev---- ---ino----
[ 0] 0x07F22000 0x00001000 0x01001083 0x00000002 0x00000001
[ 1] 0x07F23000 0x0001F000 0x01001783 0x00000002 0x00000001
[ 2] 0x07F42000 0x00001000 0x01401783 0x00000002 0x00000001
[ 3] 0x07F43000 0x00001000 0x01001083 0x00000002 0x00000001
[ 4] 0x07F44000 0x0001F000 0x01001783 0x00000002 0x00000001
[ 5] 0x07F63000 0x00001000 0x01401783 0x00000002 0x00000001
[ 6] 0x07F64000 0x00001000 0x01001083 0x00000002 0x00000001
[ 7] 0x07F65000 0x0001F000 0x01001783 0x00000002 0x00000001
[ 8] 0x07F84000 0x00001000 0x01401783 0x00000002 0x00000001
[ 9] 0x07FA6000 0x00001000 0x01001083 0x00000002 0x00000001
[ 10] 0x07FA7000 0x0001F000 0x01001783 0x00000002 0x00000001
[ 11] 0x07FC6000 0x00001000 0x01401783 0x00000002 0x00000001
[ 12] 0x07FC7000 0x00001000 0x01001083 0x00000002 0x00000001
[ 13] 0x07FC8000 0x0007E000 0x01001383 0x00000002 0x00000001
[ 14] 0x08046000 0x00002000 0x01401383 0x00000002 0x00000001
[ 15] 0x08048000 0x00004000 0x00400571 0x00000001 0x00000009
[ 16] 0x0804C000 0x00001000 0x01400372 0x00000001 0x00000009
[ 17] 0x0804D000 0x00024000 0x01400303 0x00000002 0x00000001
[ 18] 0xB0300000 0x0004E000 0x00410561 0x00000004 0xB0300000
[ 19] 0xB034E000 0x00004000 0x01400772 0x00000004 0xB0300000
This tells us that there are 20 memory regions in use, and gives us the virtual address, the size, flags, device number, and inode for each one.
Let's correlate this to the pidin output:
# pidin -p4105 mem
pid tid name prio STATE code data stack
4105 1 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
4105 2 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
4105 4 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
4105 5 sbin/pipe 10o RECEIVE 16K 148K 4096(132K)
ldqnx.so.2 @b0300000 312K 16K
- Regions 0, 3, 6, 9 and 12
- These are the guard pages at the end of the stacks, one for each of the five threads.
- Regions 1, 4, 7, 10 and 13
- These are the growth areas for the stacks, one for each of the five threads.
This memory is physically allocated on demand; these regions serve to reserve the virtual address ranges.
This corresponds to the “(132K)” from the pidin output.
- Regions 2, 5, 8, 11 and 14
- These are the in-use 4 KB stack segments, one for each of the five threads.
Only four threads are alive—we'll discuss this below.
This corresponds to the 4096 from the pidin output.
- Region 15
- This is the 16 KB of code for pipe.
- Regions 16 and 17
- These are the data areas (4 KB and 144 KB, for a total of 148 KB).
- Regions 18 and 19
- These are for the shared object, ldqnx.so.2.
Region 18 is the code area, region 19 is the data area.
These correspond to the ldqnx.so.2 line from the pidin output.
The key to decoding the regions is to look at the flags member.
You'll notice that there are two commands: DCMD_PROC_PAGEDATA and DCMD_PROC_MAPINFO.
Both of these are used to obtain information about memory regions.
However, DCMD_PROC_MAPINFO merges non-PG_* regions together, whereas
DCMD_PROC_PAGEDATA lists them individually.
This also implies that the three PG_* flags (PG_HWMAPPED, PG_REFERENCED,
and PG_MODIFIED are valid only with DCMD_PROC_PAGEDATA).
The flags member is a bitmap, broken down as follows (with each flag's value, defined in
<sys/mman.h>, shown in parentheses):
0 Reserved
0 Reserved
0 Reserved
x MAP_SYSRAM (0x01000000)
0 Reserved
x PG_HWMAPPED (0x00400000)
x PG_REFERENCED (0x00200000)
x PG_MODIFIED (0x00100000)
x MAP_ANON (0x00080000)
x MAP_BELOW16M (0x00040000)
x MAP_NOX64K (0x00020000)
x MAP_PHYS (0x00010000)
0 Reserved
x MAP_NOINIT (0x00004000)
x MAP_BELOW (0x00002000)
x MAP_STACK (0x00001000)
x PROT_NOCACHE (0x00000800)
x PROT_EXEC (0x00000400)
x PROT_WRITE (0x00000200)
x PROT_READ (0x00000100)
x MAP_LAZY (0x00000080)
x MAP_NOSYNCFILE (0x00000040)
x MAP_ELF (0x00000020)
x MAP_FIXED (0x00000010)
0 Reserved
0 Reserved
x See below.
x See below.
The last two bits are used together to indicate these flags:
00 MAP_FILE (0x00000000)
01 MAP_SHARED (0x00000001)
10 MAP_PRIVATE (0x00000002)
11 MAP_PRIVATEANON (0x00000003)
By looking for a “tell-tale” flag, namely MAP_STACK (0x00001000), I was
able to find all of the stack segments (regions 0 through 14).
Having eliminated those, regions 15, 18, and 19 are marked
as PROT_EXEC (0x00000400), so must be executable (the data area of the shared library
is marked executable).
By process of elimination, regions 16 and 17 aren't marked executable; therefore, they're data.
We can find out about the timers that are associated with a process.
We use the DCMD_PROC_TIMERS command, and expect to get back zero or more data structures,
as we did in the DCMD_PROC_PAGEDATA and DCMD_PROC_MAPINFO examples above.
The structure is defined as follows:
typedef struct _debug_timer {
timer_t id;
unsigned spare;
struct _timer_info info;
} debug_timer_t;
This structure relies on the struct _timer_info type (defined
in <sys/platform.h>, and paraphrased slightly):
struct _timer_info {
struct _itimer itime;
struct _itimer otime;
uint32_t flags;
int32_t tid;
int32_t notify;
clockid_t clockid;
uint32_t overruns;
struct sigevent event;
};
This data type, struct _timer_info is used with the
TimerInfo()
function call.
To fetch the data, we utilize code that's almost identical to that used for the memory segments (above):
#define MAX_TIMERS 512
static void
dump_procfs_timer (int fd, int pid)
{
procfs_timer timers [MAX_TIMERS];
int ntimers;
int i;
int sts;
// fetch information about the timers for this pid
sts = devctl (fd, DCMD_PROC_TIMERS, timers, sizeof (timers),
&ntimers);
if (sts != EOK) {
fprintf (stderr, "%s: TIMERS err, proc %d, errno %d (%s)\n",
progname, pid, errno, strerror (errno));
exit (EXIT_FAILURE);
}
if (ntimers > MAX_TIMERS) {
fprintf (stderr, "%s: proc %d has > %d timers (%d) !!!\n",
progname, pid, MAX_TIMERS, ntimers);
exit (EXIT_FAILURE);
}
printf ("Info from DCMD_PROC_TIMERS\n");
for (i = 0; i < ntimers; i++) {
// print information here
}
printf ("\n");
}
Since our pipe command doesn't use timers, let's look at the devb-eide driver instead.
It has four timers; I've selected just one:
Buffer 2 timer ID 2
itime 1063180.652506618 s, 0.250000000 interval s
otime 0.225003825 s, 0.250000000 interval s
flags 0x00000001
tid 0
notify 196612 (0x30004)
clockid 0
overruns 0
event (sigev_notify type 4)
SIGEV_PULSE (sigev_coid 1073741832,
sigev_value.sival_int 0,
sigev_priority -1, sigev_code 1)
The fields are as follows:
- itime
- This represents the time when the timer will fire, if it is active (i.e. the flags member has the bit _NTO_TI_ACTIVE set).
If the timer is not active, but has been active in the past, then this will contain the time that it fired last, or was going to fire (in
case the timer was canceled before firing).
- otime
- Time remaining before the timer expires.
- flags
- One or more of these flags (defined in <sys/neutrino.h>):
- _NTO_TI_ABSOLUTE (the timer is waiting
for an absolute time to occur; otherwise, the timer is considered relative)
- _NTO_TI_ACTIVE (the timer is active)
- _NTO_TI_EXPIRED (the timer has expired)
- _NTO_TI_TARGET_PROCESS (the timer targets the process,
not a specific thread)
- _NTO_TI_TOD_BASED (the timer is based relative to the
beginning of the world (January 1, 1970, 00:00:00 GMT); otherwise,
the timer is based relative to the time that Neutrino was started on the
machine (see the system page qtime boot_time member))
- tid
- The thread to which the timer is directed (or the value 0 if it's directed to the process).
- notify
- The notification type
(only the bottom 16 bits are interesting; the rest are used internally).
- clockid
- This is the clock ID (e.g. CLOCK_REALTIME).
- overruns
- This is a count of the number of timer overruns.
- event
- This is a struct sigevent that indicates the type of event that should be
delivered when the timer fires.
For the example above, it's a SIGEV_PULSE, meaning that a pulse is sent.
The fields listed after the SIGEV_PULSE pertain to the pulse delivery
type (e.g. connection ID, etc.).
In the example above, the flags member has only the bit _NTO_TI_ACTIVE (the value 0x0001) set, which
means that the timer is active.
Since the _NTO_TI_TOD_BASED flag is not set, however, it indicates that the timer is relative to the time that the machine was booted.
So the next time the timer will fire is 1063180.652506618 seconds past the time that the
machine was booted (or 12 days, 7 hours, 19 minutes, and 40.652506618 seconds past the boot time).
This timer might be used for flushing the write cache — at the time the snapshot was taken, the machine had already been up for
12 days, 7 hours, 19 minutes, and some number of seconds.
The notify type (when examined in hexadecimal) shows 0x0004 as the bottom 16 bits, which is a notification
type of SIGEV_PULSE (which agrees with the data in the event structure).
Finally, we can also find out about the interrupts that are associated with a process.
We use the DCMD_PROC_IRQS command, and expect to get back zero or more data structures,
as we did in the DCMD_PROC_PAGEDATA, DCMD_PROC_MAPINFO, and DCMD_PROC_TIMERS examples above.
The structure procfs_irq is the same as the debug_irq_t, which is defined as follows:
typedef struct _debug_irq {
pid_t pid;
pthread_t tid;
const struct sigevent *(*handler)(void *area, int id);
void *area;
unsigned flags;
unsigned level;
unsigned mask_count;
int id;
unsigned vector;
struct sigevent event;
} debug_irq_t;
To fetch the data, we use code similar to what we used with the timers and memory segments:
#define MAX_IRQS 512
static void
dump_procfs_irq (int fd, int pid)
{
procfs_irq irqs [MAX_IRQS];
int nirqs;
int i;
int sts;
// fetch information about the IRQs for this pid
sts = devctl (fd, DCMD_PROC_IRQS, irqs, sizeof (irqs),
&nirqs);
if (sts != EOK) {
fprintf (stderr, "%s: IRQS proc %d, errno %d (%s)\n",
progname, pid, errno, strerror (errno));
exit (EXIT_FAILURE);
}
if (nirqs > MAX_IRQS) {
fprintf (stderr, "%s: proc %d > %d IRQs (%d) !!! ***\n",
progname, pid, MAX_IRQS, nirqs);
exit (EXIT_FAILURE);
}
printf ("Info from DCMD_PROC_IRQS\n");
for (i = 0; i < nirqs; i++) {
// print information here
}
printf ("\n");
}
Since our pipe command doesn't use interrupts either, I've once again selected devb-eide:
Info from DCMD_PROC_IRQS
Buffer 0
pid 8200
tid 2
handler 0x00000000
area 0xEFEA5FF0
flags 0x0000000C
level 14
mask_count 0
id 3
vector 14
event (sigev_notify type 4)
SIGEV_PULSE (sigev_coid 0x40000002,
sigev_value.sival_int 0,
sigev_priority 21, sigev_code 2)
Buffer 1
pid 8200
tid 3
handler 0x00000000
area 0xEFEEFDA0
flags 0x0000000C
level 15
mask_count 0
id 4
vector 15
event (sigev_notify type 4)
SIGEV_PULSE (sigev_coid 0x40000005,
sigev_value.sival_int 0,
sigev_priority 21, sigev_code 2)
The members of the debug_irq_t shown above are as follows:
- pid and tid
- The pid and tid fields give the process ID and the thread ID
(process ID 8200 in this example is devb-eide).
- handler and area
- Indicates the interrupt service routine address, and its associated parameter.
The fact that the interrupt handler address is zero indicates that there is no real interrupt vector
associated with the interrupts; rather, the event (a pulse in both cases) should be
returned (i.e. the interrupt was attached with InterruptAttachEvent() rather than InterruptAttach()).
In the case of the handler being zero, the area member is not important.
- flags
- The flags value is hexadecimal 0x0C, which is composed of the bits
_NTO_INTR_FLAGS_PROCESS and _NTO_INTR_FLAGS_TRK_MSK,
meaning, respectively, that
the interrupt belongs to the process (rather than the
thread), and the kernel should keep track of the number of times
that the interrupt is masked and unmasked.
- level and vector
- This is the interrupt level and vector for this particular interrupt.
For an x86 architecture, they happen to be the same number.
(The level is an internal kernel number and has no meaning for the end-user.)
In our example, devb-eide is attached to two interrupt sources (as defined by the vector
parameter; i.e. interrupts 14 and 15, the two EIDE
controllers on my PC).
- mask_count
- Indicates the number of times the interrupt is masked (0 indicates the interrupt is not masked).
Useful as a diagnostic aid when you are trying to determine why your interrupt fires only once. :-)
- id
- This is the interrupt identification number returned by InterruptAttach() or InterruptAttachEvent().
- event
- A standard struct sigevent that determines what the InterruptAttachEvent() should do when it fires.
Even though we can get a lot of information about processes (above),
in Neutrino a process doesn't actually do anything on its own — it acts as a container for multiple threads.
Therefore, to find out about the threads, we can call devctl() with the following commands:
- DCMD_PROC_TIDSTATUS
- This command gets most of the information about a thread, and also sets the “current thread”
that's used for subsequent operations (except the next two in this list).
- DCMD_PROC_GETGREG
- This returns the general registers for the current thread.
- DCMD_PROC_GETFPREG
- This returns the floating-point registers for the current thread.
There are other commands available for manipulating the thread status (such as starting or stopping
a thread, etc.), which we won't discuss here.
First we need a way of iterating through all the threads in a process.
Earlier in this chapter, we called out to a function do_process(), which was
responsible for the “per-process” processing.
Let's now see what this function does and how it relates to finding
all the threads in the process:
void
do_process (int pid, int fd, char *name)
{
procfs_status status;
printf ("PROCESS ID %d\n", pid);
// dump out per-process information
dump_procfs_info (fd, pid);
dump_procfs_map_info (fd, pid);
dump_procfs_timer (fd, pid);
dump_procfs_irq (fd, pid);
// now iterate through all the threads
status.tid = 1;
while (1) {
if (devctl (fd, DCMD_PROC_TIDSTATUS, &status,
sizeof (status), 0) != EOK) {
break;
} else {
do_thread (fd, status.tid, &status);
status.tid++;
}
}
}
The do_process() function dumps out all the per-process information that we discussed
above, and then iterates through the threads, calling do_thread() for each one.
The trick here is to start with thread number 1 and call the devctl()
with DCMD_PROC_TIDSTATUS until it returns something other than EOK.
(Neutrino starts numbering threads at “1.”)
The magic that happens is that the kernel will return information about the thread specified
in the tid member of status if it has it; otherwise, it will
return information on the next available thread ID (or return something other than
EOK to indicate it's done).
The DCMD_PROC_TIDSTATUS command returns a structure of type procfs_status,
which is equivalent to debug_thread_t:
typedef struct _debug_thread_info {
pid_t pid;
pthread_t tid;
uint32_t flags;
uint16_t why;
uint16_t what;
uint64_t ip;
uint64_t sp;
uint64_t stkbase;
uint64_t tls;
uint32_t stksize;
uint32_t tid_flags;
uint8_t priority;
uint8_t real_priority;
uint8_t policy;
uint8_t state;
int16_t syscall;
uint16_t last_cpu;
uint32_t timeout;
int32_t last_chid;
sigset_t sig_blocked;
sigset_t sig_pending;
siginfo_t info;
// blocking information deleted (see next section)
uint64_t start_time;
uint64_t sutime;
} debug_thread_t;
More information than you can shake a stick at (224 bytes)!
Here are the fields and their meanings:
- pid and tid
- The process ID and the thread ID.
- flags
- Flags indicating characteristics of the thread (see <sys/debug.h> and look for
the constants beginning with _DEBUG_FLAG_).
- why and what
- The why indicates why the thread was stopped (see <sys/debug.h> and look
for the constants beginning with _DEBUG_WHY_) and the what provides
additional information for the why parameter.
For _DEBUG_WHY_TERMINATED, the what variable contains the exit code value,
for _DEBUG_WHY_SIGNALLED and _DEBUG_WHY_JOBCONTROL, what contains the signal number, and
for _DEBUG_WHY_FAULTED, what contains the fault number (see <sys/fault.h> for the values).
- ip
- The current instruction pointer where this thread is executing.
- sp
- The current stack pointer for the thread.
- stkbase and stksize
- The base of the thread's stack, and the stack size.
- tls
- The Thread Local Storage (TLS) data area.
See <sys/storage.h>.
- tid_flags
- See <sys/neutrino.h> constants beginning with _NTO_TF.
- priority and real_priority
- The priority indicates thread priority used for scheduling purposes (may be boosted), and
the real_priority indicates the actual thread priority (not boosted).
- policy
- The scheduling policy (e.g. FIFO, Round Robin).
- state
- The current state of the thread (see <sys/states.h>, e.g. STATE_MUTEX if blocked waiting on a mutex).
- syscall
- Indicates the last system call that the thread made (see <sys/kercalls.h>).
- last_cpu
- The last CPU number that the thread ran on (for SMP systems).
- timeout
- Contains the flags parameter from the last TimerTimeout() call.
- last_chid
- The last channel ID that this thread MsgReceive()'d on.
Used for priority boosting if a client does a MsgSend() and there are
no threads in STATE_RECEIVE on the channel.
- sig_blocked, sig_pending, and info
- These fields all relate to signals — recall that signals have a process aspect
as well as a thread aspect.
The sig_blocked indicates which signals this thread has blocked.
Similarly, sig_pending indicates which signals are pending on this thread.
The info member carries the information for a sigwaitinfo()
function.
- start_time
- The time, in nanoseconds since January 1, 1970, that the thread was started.
Useful for detecting thread ID reuse.
- sutime
- Thread's system and user running times (in nanoseconds).
When a thread is blocked, there's an additional set of fields
that are important (they are within the debug_thread_t, above,
where the comment says “blocking information deleted”).
The deleted content is:
union {
struct {
pthread_t tid;
} join;
struct {
int32_t id;
uintptr_t sync;
} sync;
struct {
uint32_t nd;
pid_t pid;
int32_t coid;
int32_t chid;
int32_t scoid;
} connect;
struct {
int32_t chid;
} channel;
struct {
pid_t pid;
uintptr_t vaddr;
uint32_t flags;
} waitpage;
struct {
uint32_t size;
} stack;
} blocked;
As you can see, there are six major structures (join, sync, connect, channel, waitpage, and stack)
that are unioned together (because a thread can be in only one given blocking state at a time):
- join
- When a thread is in STATE_JOIN, it's waiting to synchronize to the termination
of another thread (in the same process).
This thread is waiting for the termination of the thread identified by the tid member.
- sync
- When a thread is blocked on a synchronization object (such as a mutex, condition variable, or semaphore),
the id member indicates the virtual address of the object, and the sync member indicates the type of object.
- connect
- Indicates who the thread is blocked on (used with STATE_SEND and STATE_REPLY).
- channel
- Indicates the channel ID the thread is blocked in (used with STATE_RECEIVE).
- waitpage
- Indicates the virtual address that the thread is waiting for to be lazy-mapped in (used with STATE_WAITPAGE).
- stack
- Used with STATE_STACK, indicates the thread is waiting for size bytes of virtual address space to be made available for the stack.
These two commands are used to fetch the current general registers and floating-point registers
for the thread.
This will, of course, be architecture-specific.
For simplicity, I've shown the x86 version, and just the general registers.
The data structure is (slightly edited for clarity):
typedef union _debug_gregs {
X86_CPU_REGISTERS x86;
MIPS_CPU_REGISTERS mips;
PPC_CPU_REGISTERS ppc;
ARM_CPU_REGISTERS arm;
SH_CPU_REGISTERS sh;
uint64_t padding [1024];
} debug_greg_t;
The x86 version, (the x86 member), is as follows (from <x86/context.h>):
typedef struct x86_cpu_registers {
uint32_t edi, esi, ebp, exx, ebx, edx, ecx, eax;
uint32_t eip, cs, efl;
uint32_t esp, ss;
} X86_CPU_REGISTERS;
To get the information, a simple devctl() is issued:
static void
dump_procfs_greg (int fd, int tid)
{
procfs_greg g;
int sts;
// set the current thread first!
if ((sts = devctl (fd, DCMD_PROC_CURTHREAD, &tid,
sizeof (tid), NULL)) != EOK) {
fprintf (stderr, "%s: CURTHREAD for tid %d, error %d (%s)\n",
progname, tid, sts, strerror (sts));
exit (EXIT_FAILURE);
}
// fetch information about the registers for this pid/tid
if ((sts = devctl (fd, DCMD_PROC_GETGREG, &g,
sizeof (g), NULL)) != EOK) {
fprintf (stderr, "%s: GETGREG information, error %d (%s)\n",
progname, sts, strerror (sts));
exit (EXIT_FAILURE);
}
// print information here...
}
|
This call, unlike the other calls mentioned so far, requires you to call devctl() with DCMD_PROC_CURTHREAD
to set the current thread.
Otherwise, you'll get an EINVAL return code from the devctl(). |
Here is some sample output:
Info from DCMD_PROC_GETGREG
cs 0x0000001D eip 0xF000EF9C
ss 0x00000099 esp 0xEFFF7C14
eax 0x00000002 ebx 0xEFFFEB00
ecx 0xEFFF7C14 edx 0xF000EF9E
edi 0x00000000 esi 0x00000000
ebp 0xEFFF77C0 exx 0xEFFFEBEC
efl 0x00001006
The following references apply to this chapter.
- <sys/procfs.h>
- Contains the devctl() command constants (e.g. DCMD_PROC_GETGREG) used to fetch information.
- <sys/states.h>
- Defines the states that a thread can be in (see also
“Thread life cycle”
in the System Architecture guide).
- <sys/syspage.h>
- Defines the structure of the system page, which contains system-wide items of interest (e.g. the boot_time member of the qtime structure that
tells you when the machine was booted).
- <sys/debug.h>
- Defines the layout of the various structures in which information is returned.
See the following functions in the Neutrino C Library Reference:
See
pidin
in the Utilities Reference.