This chapter includes:
In this chapter, we'll take a look at the concept of high availability (HA). We'll discuss the definition of availability, examine the terms and concepts, and take a look at how we can make our software more highly available.
All software has bugs, and bugs manifest themselves in a variety of ways. For example, a module could run out of memory and not handle it properly, or leak memory, or get hit with a SIGSEGV, and so on. This leads to two questions:
Obviously, it's not a satisfactory solution to simply say to the customer, “What? Your system crashed? Oh, no problem, just reboot your computer!”
For the second point, it's also not a reasonable thing to suggest to the customer that they shut everything down, and simply “upgrade” everything to the latest version, and then restart it.
Some customers simply cannot afford the downtime presented by either of those “solutions.”
Let's define some terms, and then we'll talk about how we can address these (very important) concerns.
You can measure the amount of time that a system is up and running, before it fails. You can also measure the amount of time that it takes you to repair a failed system.
The first number is called MTBF, and stands for Mean Time Between Failures. The second number is called MTTR, and stands for Mean Time To Repair.
Let's look at an example. If your system can, on average, run for 1000 hours (roughly 41 days), and then fails, and then if it takes you one hour to recover, then you have a system with an MTBF of 1000 hours, and an MTTR of one hour. These numbers are useful on their own, but they are also used to derive a ratio called the availability — what percentage of the time your system is available.
This is calculated by the formula:
availability = MTBF / (MTBF + MTTR)
If we do the math, with an MTBF of 1000 hours and an MTTR of one hour, your system will have an availability of:
availability = 1000 / (1000 + 1)
or 0.999 (which is usually expressed as a percentage, so 99.9%). Since ideally the number of leading nines will be large, availability numbers are generally stated as the number of nines — 99.9% is often called “three nines.”
Is three nines good enough? Can we achieve 100% reliability (also known as “continuous availability”)?
Both answers are “no” — the first one is subjective, and depends on what level of service your customers expect, and the second is based on simple statistics — all software (and hardware) has bugs and reliability issues. No matter how much redundancy you put in, there is always a non-zero probability that you will have a catastrophic failure.
It's an interesting phenomenon to see how the human mind perceives reliability. A survey done in the mid 1970s sheds some light. In this survey, the average person on the street was asked, “Would you be satisfied with your telephone service working 90% of the time?” You'd be surprised how many people looked at the number 90, and thought to themselves, “Wow, that's a pretty high number! So, yes, I'd be happy with that!” But when the question was reversed, “Would you be satisfied if your telephone service didn't work 10% of the time?” they were inclined to change their answer even though it's the exact same question!
To understand three, four, or more nines, you need to put the availability percentage into concrete terms — for example, a “down times per year” scale. With a three nines system, your unavailability is 1 - 0.999, or 0.001%. A year has 24 × 365 = 8760 hours. A three nines system would be unavailable for 0.001 × 8760 = 8.76 hours per year.
Some ISPs boast that their end-user availability is an “astounding” 99% — but that's 87.6 hours per year of downtime, over 14 minutes of downtime per day!
This confirms the point that you need to pay careful attention to the numbers; your gut reaction to 99% availability might be that it's pretty good (similar to the telephone example above), but when you do the math, 14 minutes of downtime per day may be unacceptable.
The following table summarizes the downtime for various availability percentages:
| Availability % | Downtime per Year |
|---|---|
| 99 | 3.65 days |
| 99.9 | 8.76 hours |
| 99.99 | 52.56 minutes |
| 99.999 | 5.256 minutes |
| 99.9999 | 31.5 seconds |
This leads to the question of how many nines are required. Looking at the other end of the reliability spectrum, a typical telephone central office is expected to have six nines availability — roughly 20 minutes of downtime every 40 years. Of course, each nine that you add means that the system is ten times more available.
There are two ways to increase the availability:
If we took the three nines example above and made the MTTR only six minutes (0.1 hours for easy calculations) our availability would now be:
availability = 1000 / (1000 + 0.1)
which is 0.9999, or four nines — ten times better!
Increasing the MTBF, or the overall reliability of the system, is an expensive operation. That doesn't mean that you shouldn't do it, just that it involves a lot of testing, defensive programming, and hardware considerations.
Effectively, the goal here is to eliminate all bugs and failures. Since this is generally unfeasible (i.e. will take a near-infinite amount of time and money) in any reasonably sized system, the best you can do is approach that goal.
When my father worked at Bell-Northern Research (later part of Nortel Networks), he was responsible for coming up with a model to predict bug discovery rates, and a model for estimating the number of bugs remaining. As luck would have it, a high-profile prediction of when the next bug would be discovered turned out to be bang on and astonished everyone, especially management who had claimed “There are no more bugs left in the software!”
Once you've established a predicted bug discovery rate, you can then get a feeling for how much it is going to cost you in terms of test effort to discover some percentage of the bugs. Armed with this knowledge, you can then make an informed decision based on a cost model of when it's feasible to declare the product shippable. Note that this will also be a trade-off between when your initial public offering (IPO) is, the status of your competition, and so on. An important trade-off is the cost to fix the problem once the system is in the field. Using the models, you can trade off between testing cost and repair cost.
A much simpler and less expensive alternative, though, is to decrease the MTTR. Recall that the MTTR is in the denominator of the availability formula and is what is really driving the availability away from 100% (i.e. if the MTTR was zero, then the availability would be MTBF / MTBF, or 100%, regardless of the actual value of the MTBF.) So anything you can do to make the system recover faster goes a long way towards increasing your availability number.
Sometimes, speed of recovery is not generally thought about until later. This is usually due to the philosophy of “Who cares how long it takes to boot up? Once it's up and running it'll be fast!” Once again, it's a trade off — sometimes taking a long time to boot up is a factor of doing some work “up front” so that the application or system runs faster — perhaps precalculating tables, doing extensive hardware testing up front, etc.
Another important factor is that decreasing MTTR generally needs to be designed into the system right up front. This statement applies to HA in general — it's a lot more work to patch a system that doesn't take HA into account, than it is to design one with HA in mind.
The availability numbers that we discussed are for individual components in a system. For example, you may do extensive testing and analysis of your software, and find that a particular component has a certain availability number. But that's not the whole story — your component is part of a larger system, and will affect the availability of the system as a whole. Consider a system that has several modules. If module A relies on the services of module B, and both modules have a five nines availability (99.999%), what happens when you combine them? What's the availability of the system?
When one module depends on another module, we say that the modules are connected in series — the failure of one module results in a failure of the system:
Aggregate module formed by two modules in series.
If module A has an availability of Xa, and module B has an availability of Xb, the combined availability of a subsystem constructed of modules A and B connected in series is:
availability = Xa × Xb
Practically speaking, if both modules have a five nines availability, the system constructed from connecting the two modules in series will be 99.998%:
availability = 0.99999 * 0.99999
= 0.99998
You need to be careful here, because the numbers don't look too bad, after all, the difference between 0.99999 and 0.99998 is only 0.00001 — hardly worth talking about, right? Well, that's not the case — the system now has double the amount of downtime! Let's do the math.
Suppose we wish to see how much downtime we'll have during a year. One year has 365 × 24 × 60 × 60 seconds (31 and a half million seconds). If we have an availability of five nines, it means that we have an unavailability factor of 0.00001 (1 minus 0.99999)
Therefore, taking the 31 and a half million seconds times 0.00001 gives us 315 seconds, or just over five minutes of downtime per year. If we use our new serial availability, 0.99998, and multiply the unavailability (1 minus 0.99998, or 0.00002), we come up with 630 seconds, or 10.5 minutes of downtime — double the amount of downtime!
The reason the math is counter-intuitive is because in order to calculate downtime, we're using the unavailability number (that is, one minus the availability number).
What if your systems are in parallel? How does that look?
In a parallel system, the picture is as follows:
Aggregate module formed by two modules in parallel.
If module A has an availability of Xa, and module B has an availability of Xb, the combined availability of a subsystem constructed of modules A and B connected in parallel is:
availability = 1 - (1 - Xa) × (1 - Xb)
Practically speaking, if both modules have a five nines availability, the system constructed from connecting the two modules in parallel will be:
availability = 1 - (1 - 0.99999) * (1 - 0.99999)
= 1 - 0.00001 * 0.00001
= 1 - 0.0000000001
= 0.9999999999
That number is ten nines!
The thing to remember here is that you're not extensively penalized for serial dependencies, but the rewards for parallel dependencies are very worthwhile! Therefore, you'll want to construct your systems to have as much parallel flow as possible and minimize the amount of serial flow.
In terms of software, just what is a parallel flow? A parallel flow is one in which either module A or module B (in our example) can handle the work. This is accomplished by having a redundant server, and the ability to seamlessly use either server — whichever one happens to be available. The reason a parallel flow is more reliable is that a single fault is more likely to occur than a double fault.
A double fault isn't impossible, just much less likely. Since the two (or more) modules are operating in parallel, meaning that they are independent of each other, and either will satisfy the request, it would take a double fault to impact both modules.
A hardware example of this is powering your machine from two independent power grids. The chance that both power grids will fail simultaneously is far less than the chance of either power grid failing. Since we're assuming that the hardware can take power from either grid, and that the power grids are truly independent of each other, you can use the availability numbers of both power grids and plug them into the formula above to calculate the likelihood that your system will be without power. (And then there was the North American blackout of August 14, 2003 to reassure everyone of the power grid's stability! :-))
For another example, take a cluster of web servers connected to the same filesystem (running on a RAID box) which can handle requests in parallel. If one of the servers fails, the users will still be able to access the data, even if performance suffers a little. They might not even notice a performance hit.
You can, of course, extend the formula for sub-systems that have more than two components in series or parallel. This is left as an exercise for the reader.
Real, complex systems will have a variety of parallel and serial flows within them. The way to calculate the availability of the entire system is to work with subcomponents. Take the availability numbers of each component, and draw a large diagram with these numbers, making sure that your diagram indicates parallel and serial flows. Then take the serial flows, and collapse them into an aggregate sub-system using the formula. Do the same for parallel flows. Keep doing this until your system has just one flow — that flow will now have the availability number of the entire system.
To create a highly available system, we need to consider the system's failure modes and how we'll maximize the MTBF and minimize the MTTR. One thing that won't be immediately obvious in these discussions is the implementation, but I've included an HA example in this book.
In a typical system, the software fits into several natural layers. The GUI is at the topmost level in the hierarchy, and might interact with a database or a control program layer. These layers then interact with other layers, until finally, the lowest layer controls the hardware.
What happens when a process in the lowest layer fails? When this happens, the next layer often fails as well — it sees that its driver is no longer available and faults. The layer above that notices a similar condition — the resource that it depends on has gone away, so it faults. This can propagate right up to the highest layer, which may report some kind of diagnostic, such as “database not present.” One of the problems is that this diagnostic masks the true cause of the problem — it wasn't really a problem with the database, but rather it was a problem with the lowest-level driver.
We call this a cascade failure — lower levels causing higher levels to fail, with the failure propagating higher and higher until the highest level fails.
In this case, maximizing the MTBF would mean making not only the lower-level drivers more stable, but also preventing the cascade failure in the first place. This also decreases the MTTR because there are fewer things to repair. When we talk about in-service upgrades, below, we'll see that preventing cascade failures also has some unexpected benefits.
To prevent a cascade failure, you can:
What might not be immediately obvious is that these two points are interrelated. It does little good to have a higher-level layer prepared to deal with an outage of a lower-level layer, if the lower-level layer takes a long time to recover. It also doesn't help much if the low-level driver fails and its standby takes over, but the higher-level layer isn't prepared to gracefully handle that momentary outage.
A point that arises directly out of our cascade failure discussion has to do with system startup. Often, even an HA system is designed such that starting up the system and the normal running operation are two distinct things.
When you stop to think about this, they really don't need to be — what's the difference between a system that's starting up, and a system where every component has crashed? If the system is designed properly, there might not be any difference. Each component restarts (and we'll see how that's done below). When it starts up, it treats the lack of a lower-layer component as if the lower-layer component had just failed. Soon, the lower-layer component will start up as well, and operation can resume as if the layer below it suffered a brief outage.
An important component in an HA system is an overlord or Big Brother process (as in Orwell, not the TV show). This process is responsible for ensuring that all of the other processes in the system are running. When a process faults, we need to be able to restart it or make a standby process active.
That's the job of the overlord process. It monitors the processes for basic sanity (the definition of which is fairly broad — we'll come back to this), and performs an orderly shutdown, restart, fail-over, or whatever else is required for the failed (or failing) component.
One remaining question is “who watches the watcher?” What happens when the overlord process faults? How do we recover from that? There are a number of steps that you should take with the overlord process regardless of anything I'll tell you later on:
However, since the overlord is a piece of software that's more complex than “Hello, world” it will have bugs and it will fail.
It would be a chicken-and-egg problem to simply say that we need an overlord to watch the overlord — this would result in a never-ending chain of overlords.
What we really need is a standby overlord that is waiting for the primary overlord to die or become unresponsive, etc. When the primary fails, the standby takes over (possibly killing the faulty primary), becomes primary, and starts up its own standby version. We'll discuss this mechanism next.
So far, we've said that to make an HA system, we need to have some way of restarting failed components. But we haven't discussed how, or what impact it has.
Recall that when a failure happens, we've just blown the MTBF number — regardless of what the MTBF number is, we now need to focus on minimizing the MTTR. Repairing a component, in this case, simply means replacing the service that the failed component had been providing. There are number of ways of doing this, called cold standby, warm standby, and hot standby.
| Mode | In this standby mode: |
|---|---|
| cold | Repairing the service means noticing that the service has failed and bringing up a new module (i.e., starting an executable by loading it from media), initializing it, and bringing it into service. |
| warm | Repairing the service is the same as in cold standby mode, except the new the service is already loaded in memory, and may have some idea of the state of the service that just failed. |
| hot | The standby service is already running. It notices immediately when the primary service fails, and takes over. The primary and the standby service are in constant communication; the standby receives updates from the primary every time a significant event occurs. In hot standby mode, the standby is available almost immediately to take over — the ultimate reduction in MTTR. |
Cold, warm, and hot standby are points on a spectrum:
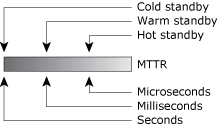
The MTTR spectrum.
The times given above are for discussion purposes only — in your particular system, you may be able to achieve hot standby only after a few hundred microseconds or milliseconds; or you may be able to achieve cold standby after only a few milliseconds.
These broad ranges are based on the following assumptions:
For some systems, a cold standby approach may be sufficient. While the cold standby approach does have a higher MTTR than the other two, it is significantly easier to implement. All the overlord needs to do is notice that the process has failed, and then start a new version of the process.
Usually this means that the newly started process initializes itself in the same way that it would if it was just starting up for the first time — it may read a configuration file, test its dependent subsystems, bind to whatever services it needs, and then advertise itself to higher level processes as being ready to service their requests.
A cold standby process might be something like a serial port driver. If it faults, the overlord simply starts a new version of the serial port driver. The driver initializes the serial ports, and then advertises itself (for example, by putting /dev/ser1 and /dev/ser2 into the pathname space) as being available. Higher-level processes may notice that the serial port seemed to go away for a little while, but that it's back in operation, and the system can proceed.
In warm standby, another instance of the process is already resident in memory, and may be partially initialized. When the primary process fails, the overlord or the standby notices that the primary process has failed, and informs the standby process that it should now assume the duties of the primary process. For this system to work, the newly started process should arrange to create another warm standby copy of itself, in case it meets with an untimely end.
Generally, a warm standby process would be something that might take a long time to initialize (perhaps precalculating some tables), but once called into action can switch over to active mode quickly.
The MTTR of a warm standby process is in between the MTTR of cold standby and hot standby. The implementation of a warm standby process is still relatively straightforward; it works just like a newly started process, except that after it reaches a certain point in its processing, it lies dormant, waiting for the primary process to fail. Then it wakes up, performs whatever further initialization it needs to, and runs.
The reason a warm standby process may need to perform further initialization only after it's been activated is that it may depend on being able to determine the current state of the system before it can service requests, but such determination cannot be made a priori; it can only be made when the standby is about to service requests.
With hot standby, we see a process that minimizes the MTTR, but is also (in the majority of cases) a lot more complicated than either the cold or warm standby.
The reason for the additional complexity is due to a number of factors. The standby process may need to actively:
Of course, as with the warm standby process, the hot standby process needs to create another copy of itself to feed updates to when it becomes primary, in case it fails.
An excellent example of a hot standby process is a database. As transactions to the primary version of the database are occurring, these same transactions are fed to the hot standby process, ensuring that it is synchronized with the primary.
The major problem with any standby software that gets data from an active primary is that, because it's the exact same version of software, any bad data that kills the primary may also kill the secondary, because it will tickle the same software bug.
If you have near-infinite money, the proper way to architect this is to have the primary and the standby developed by two independent teams, so that there will at least be different bugs in the software. This also implies that you have near-infinite money and time to test all possible fail-over scenarios. Of course, there is still a common point of failure, and that's the specification itself that's given to the two independent teams…
There are a number of ways to detect process failure. The overlord process can do this, or, in the case of hot or warm standby, the standby process can do this.
If you don't have the source code for the process, you must resort to either polling periodically (to see if the process is still alive), or arranging for death notification via an obituary.
If you do have the source code for the process, and are willing to modify it, you can arrange for the process to send you obituaries automatically.
Obituaries are quite simple. Recall that a client creates a connection to a server. The client then asks the server to perform various tasks, and the client blocks until the server receives the message and replies. When the server replies, the client unblocks.
One way of receiving an obituary is to have the client send the server a message, stating “please do not reply to this message, ever.” While the server is running, the client thread is blocked, and when the server faults, the kernel will automatically unblock the client with an error. When the client thread unblocks, it has implicitly received an obituary message.
A similar mechanism works in the opposite direction to notify the server of the client's death. In this case, the client calls open() to open the server, and never closes the file descriptor. If the client dies, the kernel will synthesize a close() message, which the server can interpret as an obituary. The kernel's synthetic close() looks just like the client's close() — except that the client and server have agreed that the close() message is an obituary message, and not just a normal close(). The client would never issue a normal close() call, so if the server gets one, it must mean the death of the client.
Putting this into perspective, in the warm and hot standby cases, we can arrange to have the two processes (the primary and the standby) work in a client/server relationship. Since the primary will always create the standby (so the standby can take over in the event of the primary's death), the standby can be a client of, or a server for, the primary. Using the methods outlined above, the standby can receive an instant obituary message when the primary dies.
Should the standby be a client or a server? That depends on the design of your system. In most cases, the primary process will be a server for some other, higher-level processes. This means that the standby process had better be a server as well, because it will need to take over the server functionality of the primary. Since the primary is a server, then we need to look at the warm and hot standby cases separately.
In the warm standby case, we want the secondary to start up, initialize, and then go to sleep, waiting for the primary to fail. The easiest way to arrange this is for the secondary to send a message to the primary telling it to never reply to the message. When the primary dies, the kernel unblocks the secondary, and the secondary can then proceed with becoming a primary.
In the hot standby case, we want the secondary to start up, initialize, and then actively receive updates from the primary, so that it stays synchronized. Either method will work (the secondary can be a client of the primary, as in the warm standby case, or the secondary can be a server for the primary).
Implementing the secondary as a client of the primary is done by having the secondary make requests like “give me the next update,” and block, until the primary hands over the next request. Then, the secondary digests the update, and sends a message asking for the next update.
Implementing the secondary as a server for the primary means that the secondary will be doing almost the exact same work as it would as primary — it will receive requests (in this case, only updates) from the primary, digest them, and then reply with the result. The result could be used by the primary to check the secondary, or it could simply be ignored. The secondary does need to reply in order to unblock the primary.
If the secondary is a client, it won't block the primary, but it does mean that the primary needs to keep track of transactions in a queue somewhere in case the secondary lags behind. If the secondary is a server, it blocks the primary (potentially causing the primary's clients to block as well), but it means that the code path that the secondary uses is the same as that used when it becomes primary.
Whether the secondary is a client or a server is your choice; this is one aspect of HA system design you will need to think about carefully.
To avoid a cascade failure, the clients of a process must be coded so they can tolerate a momentary outage of a lower-level process.
It would almost completely defeat the purpose of having hot standby processes if the processes that used their services couldn't gracefully handle the failure of a lower-level process. We discussed the impacts of cascade failures, but not their solution.
In general, the higher-level processes need to be aware that the lower-level process they rely on may fault. The higher-level processes need to maintain the state of their interactions with the lower-level process — they need to know what they were doing in order to be able to recover.
Let's look at a simple example first. Suppose that a process were using the serial port. It issues commands to the serial port when it starts up:
Suppose that the serial port is supervised by the overlord process, and that it follows the cold standby model.
When the serial port driver fails, the overlord restarts it. Unfortunately, the overlord has no idea of what settings the individual ports should have; the serial port driver will set them to whatever defaults it has, which may not match what the higher-level process expects.
The higher-level process may notice that the serial port has disappeared when it gets an error from a write(), for example. When that happens, the higher-level process needs to determine what happened and recover. This would case a cascade failure in non-HA software — the higher-level process would get the error from the write(), and would call exit() because it didn't handle the error in an HA-compatible manner.
Let's assume that our higher-level process is smarter than that. It notices the error, and because this is an HA system, assumes that someone else (the overlord) will notice the error as well and restart the serial port driver. The main trick is that the higher-level process needs to restore its operating context — in our example, it needs to reset the serial port to 38400 baud, eight data bits, one stop bit, and no parity, and it needs to reset the port to operate in raw mode.
Only after it has completed those tasks can the higher-level process continue where it left off in its operation. Even then, it may need to perform some higher-level reinitialization — not only does the serial port need to be set for a certain speed, but the peripheral that the high-level process was communicating with may need to be reset as well (for example, a modem may need to be hung up and the phone number redialed).
This is the concept of fault tolerance: being able to handle a fault and to recover gracefully.
If the serial port were implemented using the hot standby model, some of the initialization work may not be required. Since the state carried by the serial port is minimal (i.e. the only state that's generally important is the baud rate and configuration), and the serial port driver is generally very small, a cold standby solution may be sufficient for most applications.
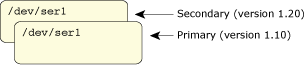
Neutrino's pathname space gives us some interesting choices when the time comes to design our warm or hot standby servers. Recall that the pathname space is maintained by the process manager, which is also the entity responsible for creation and cleanup of processes. One thing that's not immediately apparent is that you can have multiple processes registered for the same pathname, and that you can have a specific order assigned to pathname resolution.
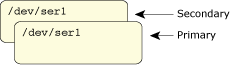
Primary and secondary servers registered for the same pathname.
A common trick for designing warm and hot standby servers is for the secondary to register the same pathname as the primary, but to tell the process manager to register it behind the existing pathname. Any requests to the pathname will be satisfied by the primary (because its pathname is “in front” of the secondary's pathname). When the primary fails, the process manager cleans up the process and also cleans up the pathname registered by the primary — this uncovers the pathname registered by the secondary.
![]()
The secondary server is exposed when the primary fails.
When we say that a client reconnects to the server, we mean that literally. The client may notice that its connection to /dev/ser1 has encountered a problem, and as part of its recovery it tries to open /dev/ser1 again — it can assume that the standby module's registered pathname will be exposed by the failure of the primary.
The most interesting thing that happens when you combine the concepts of fault tolerance and the various standby models is that you get in-service upgrades almost for free.
An in-service upgrade means that you need to be able to modify the version of software running in your system without affecting the system's ability to do whatever it's doing.
As an interesting implementation, and for a bit of contrast, some six nines systems, like central office telephone switches, accomplish this in a unique manner. In the switch, there are two processors running the main software. This is for reliability — the two processors are operating in lock-step synchronization, meaning that they execute the exact same instruction, from the exact same address, at the exact same time. If there is ever any discrepancy between the two CPUs, service is briefly interrupted as both CPUs go into an independent diagnostic mode, and the failing CPU is taken offline (alarm bells ring, logs are generated, the building is evacuated, etc.).
This dual-CPU mechanism is also used for upgrading the software. One CPU is manually placed offline, and the switch runs with only the other CPU (granted, this is a small “asking for trouble” kind of window, but these things are generally done at 3:00 AM on a Sunday morning). The offline CPU is given a new software load, and then the two CPUs switch roles — the currently running CPU goes offline, and the offline CPU with the new software becomes the controlling CPU. If the upgrade passes sanity testing, the offline processor is placed online, and full dual-redundant mode is reestablished. Even scarier things can happen, such as live software patches!
We can do something very similar with software, using the HA concepts that we've discussed so far (and good design — see the Design Philosophy chapter).
What's the real difference between killing a driver and restarting it with the same version, versus killing a driver and restarting a newer version (or, in certain special cases, an older version)? If you've made the versions of the driver compatible, there is no difference. That's what I meant when I said that you get in-service upgrades for free! To upgrade a driver, you kill the current version. The higher level software notices the outage, and expects something like the overlord process to come in and fix things. However, the overlord process not only fixes things, but upgrades the version that it loads. The higher-level software doesn't really notice; it retries its connection to the driver, and eventually discovers that a driver exists and continues running.
Preparation for in-service upgrade; the secondary server has a higher version number.
Of course, I've deliberately oversimplified things to give you the big picture. A botched in-service upgrade is an excellent way to get yourself fired. Here are just some of the kinds of things that can go wrong:
These are things that require testing, testing, and more testing.
Generally speaking, the HA infrastructure presented here is good but there's one more thing that we need to talk about. What if a process dies, and when restarted, dies again, and keeps dying? A good HA system will cover that aspect as well, by providing per-process policies. A policy defines things such as:
While it's a good idea to restart a process when it faults, some processes can be very expensive to restart (perhaps in terms of the amount of CPU the process takes to start up, or the extent to which it ties up other resources).
An overlord process needs to be able to limit how fast and how often a process is restarted. One technique is an exponential back-off algorithm. When the process dies, it's restarted immediately. If it dies again with a certain time window, it's restarted after 200 milliseconds. If it dies again with a certain time window, it's restarted after 400 milliseconds, then 800 milliseconds, then 1600 milliseconds, and so on, up to a certain limit. If it exceeds the limit, another policy is invoked that determines what to do about this process. One possibility is to run the previous version of the process, in case the new version has some new bug that the older version doesn't. Another might be to raise alarms, or page someone. Other actions are left to your imagination, and depend on the kind of system that you're designing.
Modifying a system to be HA after the system is designed can be stupidly expensive, while designing an HA system in the first place is merely moderately expensive.
The question you need to answer is, how much availability do you need? To a large extent this is a business decision (i.e., do you have service-level agreements with your customers? Are you going to be sued if your system faults in the field? What's the availability number for your competition's equipment?); often just thinking about HA can lead to a system that's good enough.
On my home system, I had a problem with one of the servers periodically dying. There didn't seem to be any particular situation that manifested the problem. Once every few weeks this server would get hit with a SIGSEGV signal. I wasn't in a position to fix it, and didn't really have the time to analyze the problem and submit a proper bug report. What I did have time to do, though, was hack together a tiny shell script that functions as an overlord. The script polls once per second to see if the server is up. If the server dies, the script restarts it. Client programs simply reconnect to the server once it's back up. Dead simple, ten lines of shell script, an hour of programming and testing, and the problem is now solved (although masked might be a better term).
Even though I had a system with a poor MTBF, by fixing the situation in a matter of a second or two (MTTR), I was able to have a system that met my availability requirements.
Of course, in a proper production environment, the core dumps from the server would be analyzed, the fault would be added to the regression test suite, and there'd be no extra stock options for the designer of the server. :-)
I've worked at a few companies that have HA systems.
QSSL has the HAT (High Availability Toolkit) and the HAM (High Availability Manager). HAT is a toolkit that includes the HAM, various APIs for client recovery, and many source code examples. HAM is the manager component that monitors processes on your system.
QNX Neutrino includes the /proc filesystem, which is where you get information about processes so you can write your own policies and monitor things that are of interest in your system.
There are several other HA packages available.