In this appendix, we'll discuss what filesystems are, and how they're implemented within the resource-manager framework. This chapter is written as a tutorial, starting from the basic operations required, and proceeding into detailed implementation. We'll cover the basic concepts used by the RAM disk and the .tar filesystem. The RAM disk and .tar filesystems themselves are covered in their own chapters, presented earlier in this book.
This appendix includes:
Before delving deeply into such topics as inodes and attributes structures and symbolic links, let's step back a little and discuss what a filesystem is. At the most basic level, a filesystem is usually a hierarchical arrangement of data. I say “usually” because several (historical) filesystems were flat filesystems — there was no hierarchical ordering of the data. An example of this is the old floppy-based MS-DOS 1.00 and 1.10 filesystems. A nonhierarchical filesystem is a subset of a hierarchical one.
The concept of a hierarchical arrangement for filesystems dates back to the dawn of modern computing history. And no, it wasn't invented by Microsoft in MS-DOS 2.00. :-)
The hierarchy, or layering, of the filesystem is accomplished by directories. By definition, a directory can contain zero or more subdirectories, and zero or more data elements. (We're not counting the two directories . and .. here.) On UNIX (and derived) systems, pathnames are constructed by having each component separated by a forward slash. (On other systems, like VAX/VMS for example, pathname components were placed in square brackets and separated by periods.) Each slash-separated component represents a directory, with the last component representing a directory or a data element. Only directories can contain further subdirectories and data elements.
Since a directory can contain subdirectories, and the subdirectories can contain further subsubdirectories, this “chain” can theoretically go on forever. Practically, however, there are limits to the length of this chain, because utilities need to be able to allocate buffers big enough to deal with the longest possible pathname. It's for this reason that the names of the individual components (be they directories or data elements) have a maximum length as well.
So far, I've been talking about “data elements” rather than the more familiar term “file.” That's because a directory can contain not just files, but also symbolic links, named special devices, block devices, and so on. I wanted to distinguish between directories and everything else — that's because only directories can have subdirectories and data elements (although symlinks can “appear” to have sub-directories, but that's a topic for later).
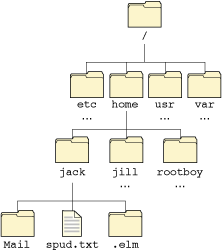
A filesystem is often represented as an inverted tree — the root of the tree is shown on the top, and the trunk and branches grow downwards.
A small portion of a filesystem tree.
 |
Note that I've used an ellipsis (…) to indicate that there are other entries, but they're not shown. Do not confuse this with the two standard directories . and .., which are also not shown! |
Here we see the root directory contains etc, home, usr, and var, all of which are directories. The home directory contains users' home directories, and one of these directories is shown, jack, as containing two other directories (Mail and .elm) and a file called spud.txt.
A Neutrino system may have many filesystems within it — there's no reason that there should be only one filesystem. Examples of filesystems are things like CD-ROMs, hard disks, foreign filesystems (like an MS-DOS, EXT2, or QNX 2 partition), network filesystems, and other, more obscure things. The important thing to remember, though, is that these filesystems have their root at a certain location within Neutrino's filesystem space. For example, the CD-ROM filesystem might begin at /fs/cd0. This means that the CD-ROM itself is mounted at /fs/cd0. Everything under /fs/cd0 is said to belong to the CD-ROM filesystem. Therefore, we say that the CD-ROM filesystem is mounted at /fs/cd0.
Now that we've looked at the components of a filesystem, we need to understand the basic functionality. A filesystem is a way of organizing data (the hierarchical nature of directories, and the fact that directories and data elements have names), as well as a way of storing data (the fact that the data elements contain useful information).
There are many types of filesystems. Some let you create files and directories within the filesystem, others (called read-only) don't. Some store their data on a hard-disk, others might manufacture the data on-the-fly when you request it. The length of the names of data elements and directories varies with each filesystem. The characters that are valid for the names of data elements and directories vary as well. Some let you create links to directories, some do not. And so on.
Filesystems are implemented as resource managers under Neutrino.
At the highest level, the mount point is represented by the mount structure, iofunc_mount_t. Directories and data elements (files, symlinks, etc.) are represented by the attributes structure, iofunc_attr_t, which is almost always extended with additional information pertaining to the filesystem.
Note that this representation may look almost exactly, or nothing like, the on-disk data structures (if there even are any). For example, the disk structures corresponding to an MS-DOS filesystem have no concept of Neutrino's iofunc_attr_t, even though the filesystem itself has concepts for files and directories. Part of the magic of a filesystem resource manager is that it arranges the attributes structures to mimic the perceived organization of the on-media (if any) data structures.
|
Effectively, the resource manager builds an internal representation of the underlying filesystem, by using the Neutrino data structures. This is key to understanding Neutrino filesystem implementations. |
In our previous example, the filesystem might be represented internally as follows:
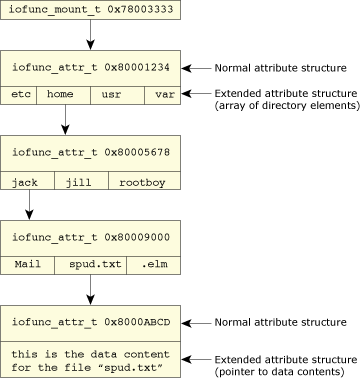
Internal resource manager view of a filesystem.
The example above shows the data structures leading up to the file /home/jack/spud.txt. The numbers in hexadecimal (e.g. 0x7800333) are sample addresses of the data structures, to emphasize the point that these things live in memory (and not on a disk somewhere).
As you can see, we've used extended versions of the regular resource manager structures. This is because the regular structures have no concepts of things like directories, so we need to add that kind of information. Our attributes structure extensions are of two types, one for directories (to contain the names of the components within that directory) and another for data elements (to contain, in this example, the data itself).
Note that the attributes structure for the data element is shown containing the data directly (this would be the case, for example, with the RAM disk — the data is stored in RAM, so the extended attributes structure would simply contain a pointer to the block or blocks that contain the data). If, on the other hand, the data was stored on media, then instead of storing a pointer to the data, we might store the starting disk block number instead. This is an implementation detail we'll discuss later.
There are several distinct operations carried out by a filesystem resource manager:
Most of these operations are either very trivial or nonexistent in a non-filesystem manager. For example, a serial port driver doesn't worry about mount point, pathname, or directory management. Its data element content management consists of managing the circular buffer that's common between the resource manager and the interrupt service routine that's interfacing to the serial port hardware. In addition, the serial port driver may worry about things like devctl() functionality, something that's rarely used in filesystem managers.
Regardless of whether the filesystem that we're discussing is based on a traditional disk-based medium, or if it's a virtual filesystem, the operations are the same. (A virtual filesystem is one in which the files or directories aren't necessarily tied directly to the underlying media, perhaps being manufactured on-demand.)
Let's look at the operations of the filesystem in turn, and then we'll take a look at the detailed implementation.
A filesystem needs to have a mount point — somewhere that we consider to be the root of the filesystem. For a traditional disk-based filesystem, this often ends up being in several places, with the root directory (i.e. /) being one of the mount points. On your Neutrino system, other filesystems are mounted by default in /fs. The .tar filesystem, just to give another example, may be mounted in the same directory as the .tar file it's managing.
The exact location of the mount point isn't important for our discussion here. What is important is that there exists some mount point, and that the top level directory (the mount point itself) is called the root of the filesystem. In our earlier example, we had a CD-ROM filesystem mounted at /fs/cd0, so we said that the directory /fs/cd0 is both the “mount point” for the CD-ROM filesystem, and is also the “root” of the CD-ROM filesystem.
One of the first things that the filesystem must do, therefore, is to register itself at a given mount point. There are actually three registrations that need to be considered:
All three registrations are performed with the resource manager function resmgr_attach(), with variations given in the arguments. For reference, here's the prototype of the resmgr_attach() function (from <sys/dispatch.h>):
int resmgr_attach (
dispatch_t *dpp,
resmgr_attr_t *attr,
const char *path,
enum _file_type file_type,
unsigned flags,
const resmgr_connect_funcs_t *connect_funcs,
const resmgr_io_funcs_t *io_funcs,
RESMGR_HANDLE_T *handle);
Of interest for this discussion are path, file_type, and flags.
The purpose of the unnamed mount registration is to serve as a place to “listen” for mount messages. These messages are generated from the command-line mount command (or the C function mount(), which is what the command-line version uses).
To register for the unnamed mount point, you supply a NULL for the path (because it's unnamed), a _FTYPE_MOUNT for the file_type, and the flags _RESMGR_FLAG_DIR | _RESMGR_FLAG_FTYPEONLY for the flags field.
The special device is used for identifying your filesystem driver so that it can serve as a target for mounts and other operations. For example, if you have two CD-ROMs, they'll show up as /dev/cd0 and /dev/cd1. When you mount one of those drives, you'll need to specify which drive to mount from. The special device name is used to make that determination.
Together with the unnamed mount registration, the special device registration lets you get the mount message and correctly determine which device should be mounted, and where.
Once you've made that determination, you'd call resmgr_attach() to perform the actual mount point registration (see the next section below).
The special device is registered with a valid name given to path (for example, /dev/ramdisk), a flag of _FTYPE_ANY given to file_type, and a 0 passed to flags.
The final step in mounting your filesystem is the actual mount point registration where the filesystem will manifest itself. The preceding two steps (the unnamed and the special device registration) are optional — you can write a perfectly functioning filesystem that doesn't perform those two steps, but performs only this mount point registration (e.g. the RAM-disk filesystem).
Apart from the initial setup of the filesystem, the unnamed and special device registration mount points are almost never used.
Once you've called resmgr_attach() to create your filesystem's mount point, you can handle requests for the filesystem. The resmgr_attach() function is called with a valid path given to path (for example, /ramdisk), a flag of _FTYPE_ANY given to file_type, and a flag of _RESMGR_FLAG_DIR given to flags (because you will support directories within your mount point).
The next function that your filesystem must perform is called pathname resolution. This is the process of accepting an arbitrary pathname, and analyzing the components within the pathname to determine if the target is accessible, possibly creating the target, and eventually resolving the target into an attributes structure.
While this may sound fairly trivial, it's actually a fair bit of work to get it just right, especially if you want to handle symbolic links correctly along the way. :-)
The algorithm can be summarized as follows. Break up the pathname into components (each component is delimited by the forward slash / character). For each pathname component, perform the following:
If all of the above steps proceeded without problems, we've effectively performed “pathname resolution.” We now have either a pointer to an attributes structure that identifies the target (and, for convenience, the target's parent attributes structure as well), or we have a pointer to just the parent attributes structure. The reason we might not have a pointer to the target is when we're creating the target. We need to verify that we can actually get to where the target will be, but obviously we don't expect the target to exist.
Returning to our example of /home/jack/spud.txt, let's imagine a user trying to open that file for reading. Here's the diagram we used earlier:
Internal resource manager view of filesystem.
We see that the root of this filesystem is the attributes structure at address 0x80001234. We're assuming (for simplicity) that this filesystem is mounted at the root of the filesystem space. The first component we see in /home/jack/spud.txt is home. Because we have the address of the attributes structure (0x80001234), we can look at the array of directory elements and see if we can find the component home. According to our first rule, since there are additional components after this one (in fact, they are jack/spud.txt), we know that home must be a directory. So we check the attributes structure's mode member, and discover that home is indeed a directory.
Next, we need to look at the attributes structure's uid, gid, and mode fields to verify that the user doing the open() call (to open the file for reading) is actually allowed to perform that operation. Note that we look at all the pathname components along the way, not just the final one! We assume this passes. We repeat the process for the attributes structure at 0x80005678, and this time search for the next component, jack. We find it, and we have the appropriate permissions. Next we perform this process again for the attributes structure at 0x80009000, and find spud.txt (and once again assume permissions are OK). This leads us to the attributes structure at 0x8000ABCD, which contains the data that we're after. Since we're only doing an open(), we don't actually return any data. We bind our OCB to the attributes structure at 0x8000ABCD and declare the open() a terrific success.
The example walkthrough above hinted at a few of the directory management features; we need to have the contents of the directories stored somewhere where we can search them, and we need to have the individual directory entries point to the attributes structures that contain information for that entry.
|
So far, we've made it look as if all possible files and directories need to be stored in RAM at all times. This is not the case! Almost all disks these days are far, far, bigger than available memory, so storing all possible directory and file entries is just not possible. Typically, attributes structures are cached, with only a fixed number of them being present in memory at any one time. When an attributes structure is no longer needed, its space is reused (or it's free()'d). The notable exception to this is, of course, a RAM disk, where all the data (including the contents!) must be stored in RAM. |
The extended attributes structure shown in the diagram earlier implies that all of the directory entries are stored within the attributes structure itself, in some kind of an array. The actual storage method (array, linked list, hash table, balanced tree, whatever) is entirely up to your imagination; I just showed a simple one for discussion. The two examples in this book, the RAM disk and the .tar filesystem, use the array method; again, purely for simplicity.
You must be able to search in a directory, and you also need to be able to add, remove, and move (rename) entries. An entry is added when a file or directory is created; an entry is removed when the file or directory is deleted; and an entry is moved (renamed) when the name of the entry is changed. Depending on the complexity of your filesystem, you may allow or disallow moving directory entries from one directory entry to another. A simple rename, like mv spud.txt abc.txt, is supported by almost all filesystems. A more complex rename, like mv spud.txt tmp/ may or may not be supported. The RAM-disk filesystem supports complex renames.
Finally, the last aspect of directory management that your filesystem must support is the ability to return information about the contents of directories. This is accomplished in your io_read() handler (when the client calls readdir()), and is discussed thoroughly in the RAM-disk Filesystem chapter.
Finally, your filesystem might just contain some actual files! There's no requirement to do this — you can have perfectly legal and useful filesystems that have only symlinks (and no files), for example.
Data element content management consists of binding data to the attributes structure, and providing some access to the data. There's a range of complexity involved here. In the RAM disk, the simplest thing to do is allocate or deallocate space as the size of the file changes (using a block allocator for efficiency), and store the new contents in the allocated space. It's more complicated if you're dealing with an actual disk-based filesystem, since you'll need to allocate blocks on disk, make records of which blocks you allocated, perhaps link them together, and so on. You can see the details of the io_read() handlers in both the RAM disk and the .tar filesystem, and the io_write() handler in the RAM disk filesystem (the .tar filesystem is read-only and therefore doesn't support writing).
The following references apply to this chapter.
See the chapters on the RAM-disk filesystem, the .tar filesystem, and the web counter resource manager for examples of filesystem resource managers.
Getting Started with QNX Neutrino: A Guide For Realtime Programmers by Robert Krten contains the basics of resource managers, message passing, etc.