This resource manager is something I've been wanting to do for a long time. Since I wrote the first book on Neutrino, I've noticed that a lot of people still ask questions in the various newsgroups about resource managers, such as “How, exactly, do I support symbolic links?” or “How does the io_rename() callout work?”
I've been following the newsgroups, and asking questions of my own, and the result of this is the following RAM-disk filesystem manager.
The code isn't necessarily the best in terms of data organization for a RAM-disk filesystem — I'm sure there are various optimizations that can be done to improve speed, cut down on memory, and so on. My goal with this chapter is to answer the detailed implementation questions that have been asked over the last few years. So, consider this a “reference design” for a filesystem resource manager, but don't consider this the best possible design for a RAM disk.
In the next chapter, I'll present a variation on this theme — a TAR filesystem manager. This lets you cd into a .tar (or, through the magic of the zlib compression library, a .tar.gz) file, and perform ls, cp, and other commands, as if you had gone through the trouble of (optionally uncompressing and) unpacking the .tar file into a temporary directory.
In the Filesystems appendix, I present background information about filesystem implementation within the resource manager framework. Feel free to read that before, during, or after you read this chapter.
This chapter includes:
The requirements for this project are fairly simple: “Handle all of the messages that a filesystem would handle, and store the data in RAM.” That said, let me clarify the functions that we will be looking at here.
The RAM disk supports the following connect functions:
The RAM disk supports the following I/O functions:
We won't be looking at functions like io_lseek(), for example, because the QSSL-supplied default function iofunc_lseek_default() does everything that we need.
Other functions are not generally used, or are understood only by a (very) few people at QSSL (e.g. io_mmap()). :-)
Some aspects of the design are apparent from the Filesystems appendix; I'll just note the ones that are different.
The design of the RAM-disk filesystem was done in conjunction with the development, so I'll describe the design in terms of the development path, and then summarize the major architectural features.
The development of the RAM disk started out innocently enough. I implemented the io_read() and io_write() functions to read from a fixed (internal) file, and the writes went to the bit bucket. The nice thing about the resource manager library is that the worker functions (like io_read() and io_write()) can be written independently of things like the connect functions (especially c_open()). That's because the worker functions base all of their operations on the OCB and the attributes structure, regardless of where these actually come from.
The next functionality I implemented was the internal in-memory directory structure. This let me create files with different names, and test those against the already-existing io_read() and io_write() functions. Of course, once I had an in-memory directory structure, it wasn't too long before I added the ability to read the directory structure (as a directory) from within io_read(). Afterward, I added functionality like a block allocator and filled in the code for the io_write() function.
Once that was done, I worked on functions like the c_open() in order to get it to search properly through multiple levels of directories, handle things like the O_EXCL and O_TRUNC flags, and so on. Finally, the rest of the functions fell into place.
The main architectural features are:
Notice that we didn't need to extend the OCB.
Before we dive into the code, let's look at the major data structures.
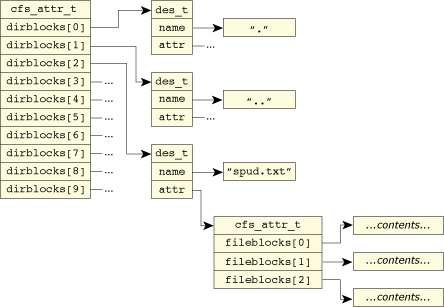
The first is the extended attributes structure:
typedef struct cfs_attr_s
{
iofunc_attr_t attr;
int nels;
int nalloc;
union {
struct des_s *dirblocks;
iov_t *fileblocks;
char *symlinkdata;
} type;
} cfs_attr_t;
As normal, the regular attributes structure, attr, is the first member. After this, the three fields are:
For reference, here is the struct des_s directory entry type:
typedef struct des_s
{
char *name; // name of entry
cfs_attr_t *attr; // attributes structure
} des_t;
It's the name of the directory element (i.e. if you had a file called spud.txt, that would be the name of the directory element) and a pointer to the attributes structure corresponding to that element.
From this we can describe the organization of the data stored in the RAM disk.
The root directory of the RAM disk contains one cfs_attr_t, which is of type struct des_s and holds all of the entries within the root directory. Entries can be files, other directories, or symlinks. If there are 10 entries in the RAM disk's root directory, then nels would be equal to 10 (nalloc would be 64 because that's the “allocate-at-once” size), and the struct des_s member dirblocks would be an array with 64 elements in it (with 10 valid), one for each entry in the root directory.
Each of the 10 struct des_s entries describes its respective element, starting with the name of the element (the name member), and a pointer to the attributes structure for that element.
A directory, with subdirectories and a file, represented by the internal data types.
If the element is a text file (our spud.txt for example), then its attributes structure would use the fileblocks member of the type union, and the content of the fileblocks would be a list of iov_ts, each pointing to the data content of the file.
 |
A direct consequence of this is that we do not support sparse files.
A sparse file is one with “gaps” in the allocated space.
Some filesystems support this notion. For example, you may write 100 bytes of data at the
beginning of the file, lseek() forward 1000000 bytes
and write another 100 bytes of data.
The file will occupy only a few kilobytes on disk, rather than the expected megabyte, because the filesystem
didn't store the “unused” data.
If, however, you write one megabyte worth of zeros instead of using lseek(),
then the file would actually consume a megabyte of disk storage.
We don't support that, because all of our iov_ts are implicitly contiguous. As an exercise, you could modify the filesystem to have variable-sized iov_ts, with the constant NULL instead of the address member to indicate a “gap.” |
If the element was a symbolic link, then the symlinkdata union member is used instead; the symlinkdata member contains a strdup()'d copy of the contents of the symbolic link. Note that in the case of symbolic links, the nels and nalloc members are not used, because a symbolic link can have only one value associated with it.
The mode member of the base attributes structure is used to determine whether we should look at the dirblocks, fileblocks, or symlinkdata union member. (That's why there appears to be no “demultiplexing” variable in the structure itself; we rely on the base one provided by the resource manager framework.)
A question that may occur at this point is, “Why isn't the name stored in the attributes structure?” The short answer is: hard links. A file may be known by multiple names, all hard-linked together. So, the actual “thing” that represents the file is an unnamed object, with zero or more named objects pointing to it. (I said “zero” because the file could be open, but unlinked. It still exists, but doesn't have any named object pointing to it.)
Probably the easiest function to understand is the io_read() function. As with all resource managers that implement directories, io_read() has both a file personality and a directory personality.
The decision as to which personality to use is made very early on, and then branches out into the two handlers:
int
cfs_io_read (resmgr_context_t *ctp, io_read_t *msg,
RESMGR_OCB_T *ocb)
{
int sts;
// use the helper function to decide if valid
if ((sts = iofunc_read_verify (ctp, msg, ocb, NULL)) != EOK) {
return (sts);
}
// decide if we should perform the "file" or "dir" read
if (S_ISDIR (ocb -> attr -> attr.mode)) {
return (ramdisk_io_read_dir (ctp, msg, ocb));
} else if (S_ISREG (ocb -> attr -> attr.mode)) {
return (ramdisk_io_read_file (ctp, msg, ocb));
} else {
return (EBADF);
}
}
The functionality above is standard, and you'll see similar code in every resource manager that has these two personalities. It would almost make sense for the resource manager framework to provide two distinct callouts, say an io_read_file() and an io_read_dir() callout.
|
It's interesting to note that the previous version of the
operating system, QNX 4, did in fact have two separate callouts, one for “read a file”
and one for “read a directory.”
However, to complicate matters a bit, it also had two separate open functions, one to open a file, and one
to open a “handle.”
Win some, lose some. |
To read the directory entry, the code is almost the same as what we've seen in the Web Counter Resource Manager chapter.
I'll point out the differences:
int
ramdisk_io_read_dir (resmgr_context_t *ctp, io_read_t *msg,
iofunc_ocb_t *ocb)
{
int nbytes;
int nleft;
struct dirent *dp;
char *reply_msg;
char *fname;
int pool_flag;
// 1) allocate a buffer for the reply
if (msg -> i.nbytes <= 2048) {
reply_msg = mpool_calloc (mpool_readdir);
pool_flag = 1;
} else {
reply_msg = calloc (1, msg -> i.nbytes);
pool_flag = 0;
}
if (reply_msg == NULL) {
return (ENOMEM);
}
// assign output buffer
dp = (struct dirent *) reply_msg;
// we have "nleft" bytes left
nleft = msg -> i.nbytes;
while (ocb -> offset < ocb -> attr -> nels) {
// 2) short-form for name
fname = ocb -> attr -> type.dirblocks [ocb -> offset].name;
// 3) if directory entry is unused, skip it
if (!fname) {
ocb -> offset++;
continue;
}
// see how big the result is
nbytes = dirent_size (fname);
// do we have room for it?
if (nleft - nbytes >= 0) {
// fill the dirent, and advance the dirent pointer
dp = dirent_fill (dp, ocb -> offset + 1,
ocb -> offset, fname);
// move the OCB offset
ocb -> offset++;
// account for the bytes we just used up
nleft -= nbytes;
} else {
// don't have any more room, stop
break;
}
}
// if we returned any entries, then update the ATIME
if (nleft != msg -> i.nbytes) {
ocb -> attr -> attr.flags |= IOFUNC_ATTR_ATIME
| IOFUNC_ATTR_DIRTY_TIME;
}
// return info back to the client
MsgReply (ctp -> rcvid, (char *) dp - reply_msg, reply_msg,
(char *) dp - reply_msg);
// 4) release our buffer
if (pool_flag) {
mpool_free (mpool_readdir, reply_msg);
} else {
free (reply_msg);
}
// tell resource manager library we already did the reply
return (_RESMGR_NOREPLY);
}
There are four important differences in this implementation compared to the implementations we've already seen:
Apart from the above comments, it's a plain directory-based io_read() function.
To an extent, the basic skeleton for the file-based io_read() function, ramdisk_io_read_file(), is also common. What's not common is the way we get the data. Recall that in the web counter resource manager (and in the atoz resource manager in the previous book) we manufactured our data on the fly. Here, we must dutifully return the exact same data as what the client wrote in.
Therefore, what you'll see here is a bunch of code that deals with blocks and iov_ts. For reference, this is what an iov_t looks like:
typedef struct iovec {
void *iov_base;
uint32_t iov_len;
} iov_t;
(This is a slight simplification; see <sys/target_nto.h> for the whole story.) The iov_base member points to the data area, and the iov_len member indicates the size of that data area. We create arrays of iov_ts in the RAM-disk filesystem to hold our data. The iov_t is also the native data type used with the message-passing functions, like MsgReplyv(), so it's natural to use this data type, as you'll see soon.
Before we dive into the code, let's look at some of the cases that come up during access of the data blocks. The same cases (and others) come up during the write implementation as well.
We'll assume that the block size is 4096 bytes.
When reading blocks, there are several cases to consider:
It's important to understand these cases, especially since they relate to boundary transfers of:
Believe me, I had fun drawing diagrams on the white board as I was coding this. :-)
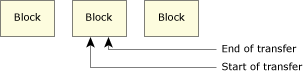
Total transfer originating entirely within one block.
In the above diagram, the transfer starts somewhere within one block and ends somewhere within the same block.
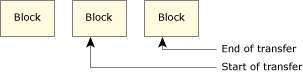
Total transfer spanning a block.
In the above diagram, the transfer starts somewhere within one block, and ends somewhere within the next block. There are no full blocks transferred. This case is similar to the case above it, except that two blocks are involved rather than just one block.
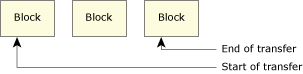
Total transfer spanning at least one full block.
In the above diagram, we see the case of having the first and last blocks incomplete, with one (or more) full intermediate blocks.
Keep these diagrams in mind when you look at the code.
int
ramdisk_io_read_file (resmgr_context_t *ctp, io_read_t *msg,
iofunc_ocb_t *ocb)
{
int nbytes;
int nleft;
int towrite;
iov_t *iovs;
int niovs;
int so; // start offset
int sb; // start block
int i;
int pool_flag;
// we don't do any xtypes here...
if ((msg -> i.xtype & _IO_XTYPE_MASK) != _IO_XTYPE_NONE) {
return (ENOSYS);
}
// figure out how many bytes are left
nleft = ocb -> attr -> attr.nbytes - ocb -> offset;
// and how many we can return to the client
nbytes = min (nleft, msg -> i.nbytes);
if (nbytes) {
// 1) calculate the number of IOVs that we'll need
niovs = nbytes / BLOCKSIZE + 2;
if (niovs <= 8) {
iovs = mpool_malloc (mpool_iov8);
pool_flag = 1;
} else {
iovs = malloc (sizeof (iov_t) * niovs);
pool_flag = 0;
}
if (iovs == NULL) {
return (ENOMEM);
}
// 2) find the starting block and the offset
so = ocb -> offset & (BLOCKSIZE - 1);
sb = ocb -> offset / BLOCKSIZE;
towrite = BLOCKSIZE - so;
if (towrite > nbytes) {
towrite = nbytes;
}
// 3) set up the first block
SETIOV (&iovs [0], (char *)
(ocb -> attr -> type.fileblocks [sb].iov_base) + so, towrite);
// 4) account for the bytes we just consumed
nleft = nbytes - towrite;
// 5) setup any additional blocks
for (i = 1; nleft > 0; i++) {
if (nleft > BLOCKSIZE) {
SETIOV (&iovs [i],
ocb -> attr -> type.fileblocks [sb + i].iov_base,
BLOCKSIZE);
nleft -= BLOCKSIZE;
} else {
// 6) handle a shorter final block
SETIOV (&&iovs [i],
ocb -> attr -> type.fileblocks [sb + i].iov_base, nleft);
nleft = 0;
}
}
// 7) return it to the client
MsgReplyv (ctp -> rcvid, nbytes, iovs, i);
// update flags and offset
ocb -> attr -> attr.flags |= IOFUNC_ATTR_ATIME
| IOFUNC_ATTR_DIRTY_TIME;
ocb -> offset += nbytes;
if (pool_flag) {
mpool_free (mpool_iov8, iovs);
} else {
free (iovs);
}
} else {
// nothing to return, indicate End Of File
MsgReply (ctp -> rcvid, EOK, NULL, 0);
}
// already done the reply ourselves
return (_RESMGR_NOREPLY);
}
We won't discuss the standard resource manager stuff, but we'll focus on the unique functionality of this resource manager.
The main trick was to make sure that there were no boundary or off-by-one conditions in the logic that determines which block to start at, how many bytes to transfer, and how to handle the final block. Once that was worked out, it was smooth sailing as far as implementation.
You could optimize this further by returning the IOVs directly from the extended attributes structure's fileblocks member, but beware of the first and last block — you might need to modify the values stored in the fileblocks member's IOVs (the address and length of the first block, and the length of the last block), do your MsgReplyv(), and then restore the values. A little messy perhaps, but a tad more efficient.
Another easy function to understand is the io_write() function. It gets a little more complicated because we have to handle allocating blocks when we run out (i.e. when we need to extend the file because we have written past the end of the file).
The io_write() functionality is presented in two parts, one is a fairly generic io_write() handler, the other is the actual block handler that writes the data to the blocks.
The generic io_write() handler looks at the current size of the file, the OCB's offset member, and the number of bytes being written to determine if the handler needs to extend the number of blocks stored in the fileblocks member of the extended attributes structure. Once that determination is made, and blocks have been added (and zeroed!), then the RAM-disk-specific write handler, ramdisk_io_write(), is called.
The following diagram illustrates the case where we need to extend the blocks stored in the file:
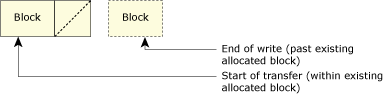
A write that overwrites existing data in the file, adds data to the “unused” portion of the current last block, and then adds one more block of data.
The following shows what happens when the RAM disk fills up. Initially, the write would want to perform something like this:
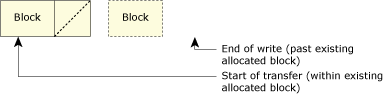
A write that requests more space than exists on the disk.
However, since the disk is full (we could allocate only one more block), we trim the write request to match the maximum space available:
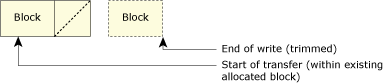
A write that's been trimmed due to lack of disk space.
There was only 4 KB more available, but the client requested more than that, so the request was trimmed.
int
cfs_io_write (resmgr_context_t *ctp, io_write_t *msg,
RESMGR_OCB_T *ocb)
{
cfs_attr_t *attr;
int i;
off_t newsize;
if ((i = iofunc_write_verify (ctp, msg, ocb, NULL)) != EOK) {
return (i);
}
// shortcuts
attr = ocb -> attr;
newsize = ocb -> offset + msg -> i.nbytes;
// 1) see if we need to grow the file
if (newsize > attr -> attr.nbytes) {
// 2) truncate to new size using TRUNCATE_ERASE
cfs_a_truncate (attr, newsize, TRUNCATE_ERASE);
// 3) if it's still not big enough
if (newsize > attr -> attr.nbytes) {
// 4) trim the client's size
msg -> i.nbytes = attr -> attr.nbytes - ocb -> offset;
if (!msg -> i.nbytes) {
return (ENOSPC);
}
}
}
// 5) call the RAM disk version
return (ramdisk_io_write (ctp, msg, ocb));
}
The code walkthrough is as follows:
As mentioned above, the generic io_write() function isn't doing anything that's RAM-disk-specific; that's why it was separated out into its own function.
Now, for the RAM-disk-specific functionality. The following code implements the block-management logic (refer to the diagrams for the read logic):
int
ramdisk_io_write (resmgr_context_t *ctp, io_write_t *msg,
RESMGR_OCB_T *ocb)
{
cfs_attr_t *attr;
int sb; // startblock
int so; // startoffset
int lb; // lastblock
int nbytes, nleft;
int toread;
iov_t *newblocks;
int i;
off_t newsize;
int pool_flag;
// shortcuts
nbytes = msg -> i.nbytes;
attr = ocb -> attr;
newsize = ocb -> offset + nbytes;
// 1) precalculate the block size constants...
sb = ocb -> offset / BLOCKSIZE;
so = ocb -> offset & (BLOCKSIZE - 1);
lb = newsize / BLOCKSIZE;
// 2) allocate IOVs
i = lb - sb + 1;
if (i <= 8) {
newblocks = mpool_malloc (mpool_iov8);
pool_flag = 1;
} else {
newblocks = malloc (sizeof (iov_t) * i);
pool_flag = 0;
}
if (newblocks == NULL) {
return (ENOMEM);
}
// 3) calculate the first block size
toread = BLOCKSIZE - so;
if (toread > nbytes) {
toread = nbytes;
}
SETIOV (&newblocks [0], (char *)
(attr -> type.fileblocks [sb].iov_base) + so, toread);
// 4) now calculate zero or more blocks;
// special logic exists for a short final block
nleft = nbytes - toread;
for (i = 1; nleft > 0; i++) {
if (nleft > BLOCKSIZE) {
SETIOV (&newblocks [i],
attr -> type.fileblocks [sb + i].iov_base, BLOCKSIZE);
nleft -= BLOCKSIZE;
} else {
SETIOV (&newblocks [i],
attr -> type.fileblocks [sb + i].iov_base, nleft);
nleft = 0;
}
}
// 5) transfer data from client directly into the ramdisk...
resmgr_msgreadv (ctp, newblocks, i, sizeof (msg -> i));
// 6) clean up
if (pool_flag) {
mpool_free (mpool_iov8, newblocks);
} else {
free (newblocks);
}
// 7) use the original value of nbytes here...
if (nbytes) {
attr -> attr.flags |= IOFUNC_ATTR_MTIME | IOFUNC_ATTR_DIRTY_TIME;
ocb -> offset += nbytes;
}
_IO_SET_WRITE_NBYTES (ctp, nbytes);
return (EOK);
}
Possibly the most complex function, c_open() performs the following:
We'll look at the individual sub-tasks listed above, and then delve into the code walkthrough for the c_open() call itself at the end.
In order to find the target, it seems that all we need to do is simply break the pathname apart at the / characters and see if each component exists in the dirblocks member of the extended attributes structure. While that's basically true at the highest level, as the saying goes, “The devil is in the details.”
Permission-checks complicate this matter slightly. Symbolic links complicate this matter significantly (a symbolic link can point to a file, a directory, or another symbolic link). And, to make things even more complicated, under certain conditions the target may not even exist, so we may need to operate on the directory entry above the target instead of the target itself.
So, the connect function (c_open()) calls connect_msg_to_attr(), which in turn calls pathwalk().
The pathwalk() function is called only by connect_msg_to_attr() and by the rename function (c_rename(), which we'll see later). Let's look at this lowest-level function first, and then we'll proceed up the call hierarchy.
int
pathwalk (resmgr_context_t *ctp, char *pathname,
cfs_attr_t *mountpoint, int flags, des_t *output,
int *nrets, struct _client_info *cinfo)
{
int nels;
int sts;
char *p;
// 1) first, we break apart the slash-separated pathname
memset (output, 0, sizeof (output [0]) * *nrets);
output [0].attr = mountpoint;
output [0].name = "";
nels = 1;
for (p = strtok (pathname, "/"); p; p = strtok (NULL, "/")) {
if (nels >= *nrets) {
return (E2BIG);
}
output [nels].name = p;
output [nels].attr = NULL;
nels++
}
// 2) next, we analyze each pathname
for (*nrets = 1; *nrets < nels; ++*nrets) {
// 3) only directories can have children.
if (!S_ISDIR (output [*nrets - 1].attr -> attr.mode)) {
return (ENOTDIR);
}
// 4) check access permissions
sts = iofunc_check_access (ctp,
&output [*nrets-1].attr -> attr,
S_IEXEC, cinfo);
if (sts != EOK) {
return (sts);
}
// 5) search for the entry
output [*nrets].attr = search_dir (output [*nrets].name,
output [*nrets-1].attr);
if (!output [*nrets].attr) {
++*nrets;
return (ENOENT);
}
// 6) process the entry
if (S_ISLNK (output [*nrets].attr -> attr.mode)) {
++*nrets;
return (EOK);
}
}
// 7) everything was okay
return (EOK);
}
The pathwalk() function fills the output parameter with the pathnames and attributes structures of each pathname component. The *nrets parameter is used as both an input and an output. In the input case it tells pathwalk() how big the output array is, and when pathwalk() returns, *nrets is used to indicate how many elements were successfully processed (see the walkthrough below). Note that the way that we've broken the string into pieces first, and then processed the individual components one at a time means that when we abort the function (for any of a number of reasons as described in the walkthrough), the output array may have elements that are valid past where the *nrets variable indicates. This is actually useful; for example, it lets us get the pathname of a file or directory that we're creating (and hence doesn't exist). It also lets us check if there are additional components past the one that we're creating, which would be an error.
Detailed walkthrough:
|
Note that we use strtok() which isn't thread-safe; in this resource manager we are single-threaded. We would have used strtok_r() if thread-safety were a concern. |
The job of *nrets is to give the higher-level routines an indication of where the processing stopped. The return value from pathwalk() will tell them why it stopped.
The next-higher function in the call hierarchy is connect_msg_to_attr(). It calls pathwalk() to break apart the pathname, and then looks at the return code, the type of request, and other parameters to make a decision.
You'll see this function used in most of the resource manager connect functions in the RAM disk.
After pathwalk(), several scenarios are possible:
This function accepts two parameters, parent and target, which are used extensively in the upper levels to describe the directory that contains the target, as well as the target itself (if it exists).
int
connect_msg_to_attr (resmgr_context_t *ctp,
struct _io_connect *cmsg,
RESMGR_HANDLE_T *handle,
des_t *parent, des_t *target,
int *sts, struct _client_info *cinfo)
{
des_t components [_POSIX_PATH_MAX];
int ncomponents;
// 1) Find target, validate accessibility of components
ncomponents = _POSIX_PATH_MAX;
*sts = pathwalk (ctp, cmsg -> path, handle, 0, components,
&ncomponents, cinfo);
// 2) Assign parent and target
*target = components [ncomponents - 1];
*parent = ncomponents == 1 ? *target
: components [ncomponents - 2];
// 3) See if we have an error, abort.
if (*sts == ENOTDIR || *sts == EACCES) {
return (1);
}
// 4) missing non-final component
if (components [ncomponents].name != NULL && *sts == ENOENT) {
return (1);
}
if (*sts == EOK) {
// 5) if they wanted a directory, and we aren't one, honk.
if (S_ISDIR (cmsg -> mode)
&& !S_ISDIR (components [ncomponents-1].attr->attr.mode)) {
*sts = ENOTDIR;
return (1);
}
// 6) yes, symbolic links are complicated!
// (See walkthrough and notes)
if (S_ISLNK (components [ncomponents - 1].attr -> attr.mode)
&& (components [ncomponents].name
|| (cmsg -> eflag & _IO_CONNECT_EFLAG_DIR)
|| !S_ISLNK (cmsg -> mode))) {
redirect_symlink (ctp, cmsg, target -> attr,
components, ncomponents);
*sts = _RESMGR_NOREPLY;
return (1);
}
}
// 7) all OK
return (0);
}
Symbolic links complicate the processing greatly.
Let's spend a little more time with the line:
if (
S_ISLNK (components [ncomponents - 1].attr -> attr.mode)
&&
(
components [ncomponents].name
|| (cmsg -> eflag & _IO_CONNECT_EFLAG_DIR)
|| !S_ISLNK (cmsg -> mode)
)
)
{
I've broken it out over a few more lines to clarify the logical relationships. The very first condition (the one that uses the macro S_ISLNK()) gates the entire if clause. If the entry we are looking at is not a symlink, we can give up right away, and continue to the next statement.
Next, we examine a three-part OR condition. We perform the redirection if any of the following conditions is true:
In case we need to follow the symlink, we don't do it ourselves! It's not the job of this resource manager's connect functions to follow the symlink. All we need to do is call redirect_symlink() and it will reply with a redirect message back to the client's open() (or other connect function call). All clients' open() calls know how to handle the redirection, and they (the clients) are responsible for retrying the operation with the new information from the resource manager.
To clarify:
So, it's important to note that after the RAM disk performed the “redirect” function, it was out of the loop after that point.
We've made sure that the pathname is valid, and we've resolved any symbolic links that we needed to. Now we need to figure out the mode flags.
There are a few combinations that we need to take care of:
This may involve creating or truncating the target, or returning error indications. We'll see this in the code walkthrough below.
To bind the OCB and the attributes structures, we simply call the utility functions (see the walkthrough, below).
Now that we understand all of the steps involved in processing the c_open() (and, coincidentally, large chunks of all other connect functions), it's time to look at the code.
int
cfs_c_open (resmgr_context_t *ctp, io_open_t *msg,
RESMGR_HANDLE_T *handle, void *extra)
{
int sts;
des_t parent, target;
struct _client_info cinfo;
// 1) fetch the client information
if (sts = iofunc_client_info (ctp, 0, &cinfo)) {
return (sts);
}
// 2) call the helper connect_msg_to_attr
if (connect_msg_to_attr (ctp, &msg -> connect, handle,
&parent, &target, &sts, &cinfo)) {
return (sts);
}
// if the target doesn't exist
if (!target.attr) {
// 3) and we're not creating it, error
if (!(msg -> connect.ioflag & O_CREAT)) {
return (ENOENT);
}
// 4) else we are creating it, call the helper iofunc_open
sts = iofunc_open (ctp, msg, NULL, &parent.attr -> attr,
NULL);
if (sts != EOK) {
return (sts);
}
// 5) create an attributes structure for the new entry
target.attr = cfs_a_mkfile (parent.attr,
target.name, &cinfo);
if (!target.attr) {
return (errno);
}
// else the target exists
} else {
// 6) call the helper function iofunc_open
sts = iofunc_open (ctp, msg, &target.attr -> attr,
NULL, NULL);
if (sts != EOK) {
return (sts);
}
}
// 7) Target existed or just created, truncate if required.
if (msg -> connect.ioflag & O_TRUNC) {
// truncate at offset zero because we're opening it:
cfs_a_truncate (target.attr, 0, TRUNCATE_ERASE);
}
// 8) bind the OCB and attributes structures
sts = iofunc_ocb_attach (ctp, msg, NULL,
&target.attr -> attr, NULL);
return (sts);
}
The walkthrough is as follows:
How to redirect a symbolic link is an interesting topic.
First of all, there are two cases to consider: either the symlink points to an absolute pathname (one that starts with a leading / character) or it doesn't and hence is relative.
For the absolute pathname, we need to forget about the current path leading up to the symbolic link, and replace the entire path up to and including the symbolic link with the contents of the symbolic link:
ln -s /tmp /ramdisk/tempfiles
In that case, when we resolve /ramdisk/tempfiles, we will redirect the symlink to /tmp. However, in the relative case:
ln -s ../resume.html resume.htm
When we resolve the relative symlink, we need to preserve the existing pathname up to the symlink, and replace only the symlink with its contents. So, in our example above, if the path was /ramdisk/old/resume.htm, we would replace the symlink, resume.htm, with its contents, ../resume.html, to get the pathname /ramdisk/old/../resume.html as the redirection result. Someone else is responsible for resolving /ramdisk/old/../resume.html into /ramdisk/resume.html.
In both cases, we preserve the contents (if any) after the symlink, and simply append that to the substituted value.
Here is the redirect_symlink() function presented with comments so that you can see what's going on:
static void
redirect_symlink (resmgr_context_t *ctp,
struct _io_connect *msg, cfs_attr_t *attr,
des_t *components, int ncomponents)
{
int eflag;
int ftype;
char newpath [PATH_MAX];
int i;
char *p;
struct _io_connect_link_reply link_reply;
// 1) set up variables
i = 1;
p = newpath;
*p = 0;
// 2) a relative path, do up to the symlink itself
if (*attr -> type.symlinkdata != '/') {
// 3) relative -- copy up to and including
for (; i < (ncomponents - 1); i++) {
strcat (p, components [i].name);
p += strlen (p);
strcat (p, "/");
p++;
}
} else {
// 4) absolute, discard up to and including
i = ncomponents - 1;
}
// 5) now substitute the content of the symlink
strcat (p, attr -> type.symlinkdata);
p += strlen (p);
// skip the symlink itself now that we've substituted it
i++;
// 6) copy the rest of the pathname components, if any
for (; components [i].name && i < PATH_MAX; i++) {
strcat (p, "/");
strcat (p, components [i].name);
p += strlen (p);
}
// 7) preserve these, wipe rest
eflag = msg -> eflag;
ftype = msg -> file_type;
memset (&link_reply, 0, sizeof (link_reply));
// 8) set up the reply
_IO_SET_CONNECT_RET (ctp, _IO_CONNECT_RET_LINK);
link_reply.file_type = ftype;
link_reply.eflag = eflag;
link_reply.path_len = strlen (newpath) + 1;
SETIOV (&ctp -> iov [0], &link_reply, sizeof (link_reply));
SETIOV (&ctp -> iov [1], newpath, link_reply.path_len);
MsgReplyv (ctp -> rcvid, ctp -> status, ctp -> iov, 2);
}
So basically, the main trick was in performing the symlink substitution, and setting the flag to indicate redirection.
This is a simple one. You've already seen how symlinks are stored internally in the RAM-disk resource manager. The job of c_readlink() is to return the value of the symbolic link. It's called when you do a full ls, for example:
# ls -lF /my_temp lrwxrwxrwx 1 root root 4 Aug 16 14:06 /my_temp@ -> /tmp
Since this code shares a lot in common with the processing for c_open(), I'll just point out the major differences.
int
cfs_c_readlink (resmgr_context_t *ctp, io_readlink_t *msg,
RESMGR_HANDLE_T *handle, void *reserved)
{
des_t parent, target;
int sts;
int eflag;
struct _client_info cinfo;
int tmp;
// get client info
if (sts = iofunc_client_info (ctp, 0, &cinfo)) {
return (sts);
}
// get parent and target
if (connect_msg_to_attr (ctp, &msg -> connect, handle,
&parent, &target, &sts, &cinfo)) {
return (sts);
}
// there has to be a target!
if (!target.attr) {
return (sts);
}
// 1) call the helper function
sts = iofunc_readlink (ctp, msg, &target.attr -> attr, NULL);
if (sts != EOK) {
return (sts);
}
// 2) preserve eflag...
eflag = msg -> connect.eflag;
memset (&msg -> link_reply, 0, sizeof (msg -> link_reply));
msg -> link_reply.eflag = eflag;
// 3) return data
tmp = strlen (target.attr -> type.symlinkdata);
SETIOV (&ctp -> iov [0], &msg -> link_reply,
sizeof (msg -> link_reply));
SETIOV (&ctp -> iov[1], target.attr -> type.symlinkdata, tmp);
msg -> link_reply.path_len = tmp;
MsgReplyv (ctp -> rcvid, EOK, ctp -> iov, 2);
return (_RESMGR_NOREPLY);
}
The detailed code walkthrough is as follows:
The c_link() function is responsible for soft and hard links. A hard link is the “original” link from the dawn of history. It's a method that allows one resource (be it a directory or a file, depending on the support) to have multiple names. In the example in the symlink redirection, we created a symlink from resume.htm to ../resume.html; we could just as easily have created a hard link:
# ln ../resume.html resume.htm
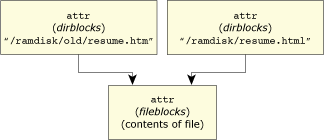
A hard link implemented as two different attributes structures pointing to the same file.
In this case, both ../resume.html and resume.htm would be considered identical; there's no concept of “original” and “link” as there is with symlinks.
When the client calls link() or symlink() (or uses the command-line command ln), our RAM-disk resource manager's c_link() function will be called.
The c_link() function follows a similar code path as all of the other connect functions we've discussed so far (c_open() and c_readlink()), so once again we'll just focus on the differences:
int
cfs_c_link (resmgr_context_t *ctp, io_link_t *msg,
RESMGR_HANDLE_T *handle, io_link_extra_t *extra)
{
RESMGR_OCB_T *ocb;
des_t parent, target;
int sts;
char *p, *s;
struct _client_info cinfo;
if (sts = iofunc_client_info (ctp, 0, &cinfo)) {
return (sts);
}
if (connect_msg_to_attr (ctp, &msg -> connect, handle,
&parent, &target, &sts, &cinfo)) {
return (sts);
}
if (target.attr) {
return (EEXIST);
}
// 1) find out what type of link we are creating
switch (msg -> connect.extra_type) {
// process a hard link
case _IO_CONNECT_EXTRA_LINK:
ocb = extra -> ocb;
p = strdup (target.name);
if (p == NULL) {
return (ENOMEM);
}
// 2) add a new directory entry
if (sts = add_new_dirent (parent.attr, ocb -> attr, p)) {
free (p);
return (sts);
}
// 3) bump the link count
ocb -> attr -> attr.nlink++;
return (EOK);
// process a symbolic link
case _IO_CONNECT_EXTRA_SYMLINK:
p = target.name;
s = strdup (extra -> path);
if (s == NULL) {
return (ENOMEM);
}
// 4) create a symlink entry
target.attr = cfs_a_mksymlink (parent.attr, p, NULL);
if (!target.attr) {
free (s);
return (errno);
}
// 5) write data
target.attr -> type.symlinkdata = s;
target.attr -> attr.nbytes = strlen (s);
return (EOK);
default:
return (ENOSYS);
}
return (_RESMGR_DEFAULT);
}
The following is the code walkthrough for creating hard or symbolic links:
The functionality to perform a rename can be done in one of two ways. You can simply return ENOSYS, which tells the client's rename() that you don't support renaming, or you can handle it. If you do return ENOSYS, an end user might not notice it right away, because the command-line utility mv deals with that and copies the file to the new location and then deletes the original. For a RAM disk, with small files, the time it takes to do the copy and unlink is imperceptible. However, simply changing the name of a directory that has lots of large files will take a long time, even though all you're doing is changing the name of the directory!
In order to properly implement rename functionality, there are two interesting issues:
The rename logic is further complicated by the fact that we are dealing with two paths instead of just one. In the c_link() case, one of the pathnames was implied by either an OCB (hard link) or actually given (symlink) — for the symlink we viewed the second “pathname” as a text string, without doing any particular checking on it.
You'll notice this “two path” impact when we look at the code:
int
cfs_c_rename (resmgr_context_t *ctp, io_rename_t *msg,
RESMGR_HANDLE_T *handle, io_rename_extra_t *extra)
{
// source and destination parents and targets
des_t sparent, starget, dparent, dtarget;
des_t components [_POSIX_PATH_MAX];
int ncomponents;
int sts;
char *p;
int i;
struct _client_info cinfo;
// 1) check for "initial subset" (mv x x/a) case
i = strlen (extra -> path);
if (!strncmp (extra -> path, msg -> connect.path, i)) {
// source could be a subset, check character after
// end of subset in destination
if (msg -> connect.path [i] == 0
|| msg -> connect.path [i] == '/') {
// source is identical to destination, or is a subset
return (EINVAL);
}
}
// get client info
if (sts = iofunc_client_info (ctp, 0, &cinfo)) {
return (sts);
}
// 2) do destination resolution first in case we need to
// do a redirect or otherwise fail the request.
if (connect_msg_to_attr (ctp, &msg -> connect, handle,
&dparent, &dtarget, &sts, &cinfo)) {
return (sts);
}
// 3) if the destination exists, kill it and continue.
if (sts != ENOENT) {
if (sts == EOK) {
if ((sts = cfs_rmnod (&dparent, dtarget.name,
dtarget.attr)) != EOK) {
return (sts);
}
} else {
return (sts);
}
}
// 4) use our friend pathwalk() for source resolution.
ncomponents = _POSIX_PATH_MAX;
sts = pathwalk (ctp, extra -> path, handle, 0, components,
&ncomponents, &cinfo);
// 5) missing directory component
if (sts == ENOTDIR) {
return (sts);
}
// 6) missing non-final component
if (components [ncomponents].name != NULL && sts == ENOENT) {
return (sts);
}
// 7) an annoying bug
if (ncomponents < 2) {
// can't move the root directory of the filesystem
return (EBUSY);
}
starget = components [ncomponents - 1];
sparent = components [ncomponents - 2];
p = strdup (dtarget.name);
if (p == NULL) {
return (ENOMEM);
}
// 8) create new...
if (sts = add_new_dirent (dparent.attr, starget.attr, p)) {
free (p);
return (sts);
}
starget.attr -> attr.nlink++;
// 9) delete old
return (cfs_rmnod (&sparent, starget.name, starget.attr));
}
The walkthrough is as follows:
The functionality of c_mknod() is straightforward. It calls iofunc_client_info() to get information about the client, then resolves the pathname using connect_msg_to_attr(), does some error checking (among other things, calls the helper function iofunc_mknod()), and finally creates the directory by calling the utility function cfs_a_mkdir().
To unlink an entry, the following code is used:
int
c_unlink (resmgr_context_t *ctp, io_unlink_t *msg,
RESMGR_HANDLE_T *handle, void *reserved)
{
des_t parent, target;
int sts;
struct _client_info cinfo;
if (sts = iofunc_client_info (ctp, 0, &cinfo)) {
return (sts);
}
if (connect_msg_to_attr (ctp, &msg -> connect, handle,
&parent, &target, &sts, &cinfo)) {
return (sts);
}
if (sts != EOK) {
return (sts);
}
// see below
if (target.attr == handle) {
return (EBUSY);
}
return (cfs_rmnod (&parent, target.name, target.attr));
}
The code implementing c_unlink() is straightforward as well — we get the client information and resolve the pathname. The destination had better exist, so if we don't get an EOK we return the error to the client. Also, it's a really bad idea (read: bug) to unlink the mount point, so we make a special check against the target attribute's being equal to the mount point attribute, and return EBUSY if that's the case. Note that QNX 4 returns the constant EBUSY, Neutrino returns EPERM, and OpenBSD returns EISDIR. So, there are plenty of constants to choose from in the real world! I like EBUSY.
Other than that, the actual work is done in cfs_rmnod(), below.
int
cfs_rmnod (des_t *parent, char *name, cfs_attr_t *attr)
{
int sts;
int i;
// 1) remove target
attr -> attr.nlink--;
if ((sts = release_attr (attr)) != EOK) {
return (sts);
}
// 2) remove the directory entry out of the parent
for (i = 0; i < parent -> attr -> nels; i++) {
// 3) skip empty directory entries
if (parent -> attr -> type.dirblocks [i].name == NULL) {
continue;
}
if (!strcmp (parent -> attr -> type.dirblocks [i].name,
name)) {
break;
}
}
if (i == parent -> attr -> nels) {
// huh. gone. This is either some kind of internal error,
// or a race condition.
return (ENOENT);
}
// 4) reclaim the space, and zero out the entry
free (parent -> attr -> type.dirblocks [i].name);
parent -> attr -> type.dirblocks [i].name = NULL;
// 5) catch shrinkage at the tail end of the dirblocks[]
while (parent -> attr -> type.dirblocks
[parent -> attr -> nels - 1].name == NULL) {
parent -> attr -> nels--;
}
// 6) could check the open count and do other reclamation
// magic here, but we don't *have to* for now...
return (EOK);
}
Notice that we may not necessarily reclaim the space occupied by the resource! That's because the file could be in use by someone else. So the only time that it's appropriate to actually remove it is when the link count goes to zero, and that's checked for in the release_attr() routine as well as in the io_close_ocb() handler (below).
Here's the walkthrough:
This naturally brings us to the io_close_ocb() function. In most resource managers, you'd let the default library function, iofunc_close_ocb_default(), do the work. However, in our case, we may need to free a resource. Consider the case where a client performs the following perfectly legal (and useful for things like temporary files) code:
fp = fopen ("/ramdisk/tmpfile", "r+");
unlink ("/ramdisk/tmpfile");
// do some processing with the file
fclose (fp);
We cannot release the resources for the /ramdisk/tmpfile until after the link count (the number of open file descriptors to the file) goes to zero.
The fclose() will eventually translate within the C library into a close(), which will then trigger our RAM disk's io_close_ocb() handler. Only when the count goes to zero can we free the data.
Here's the code for the io_close_ocb():
int
cfs_io_close_ocb (resmgr_context_t *ctp, void *reserved,
RESMGR_OCB_T *ocb)
{
cfs_attr_t *attr;
int sts;
attr = ocb -> attr;
sts = iofunc_close_ocb (ctp, ocb, &attr -> attr);
if (sts == EOK) {
// release_attr makes sure that no-one is using it...
sts = release_attr (attr);
}
return (sts);
}
Note the attr -> attr — the helper function iofunc_close_ocb() expects the normal, nonextended attributes structure.
Once again, we rely on the services of release_attr() to ensure that the link count is zero.
Here's the source for release_attr() (from attr.c):
int
release_attr (cfs_attr_t *attr)
{
int i;
// 1) check the count
if (!attr -> attr.nlink && !attr -> attr.count) {
// decide what kind (file or dir) this entry is...
if (S_ISDIR (attr -> attr.mode)) {
// 2) it's a directory, see if it's empty
if (attr -> nels > 2) {
return (ENOTEMPTY);
}
// 3) need to free "." and ".."
free (attr -> type.dirblocks [0].name);
free (attr -> type.dirblocks [0].attr);
free (attr -> type.dirblocks [1].name);
free (attr -> type.dirblocks [1].attr);
// 4) release the dirblocks[]
if (attr -> type.dirblocks) {
free (attr -> type.dirblocks);
free (attr);
}
} else if (S_ISREG (attr -> attr.mode)) {
// 5) a regular file
for (i = 0; i < attr -> nels; i++) {
cfs_block_free (attr,
attr -> type.fileblocks [i].iov_base);
attr -> type.fileblocks [i].iov_base = NULL;
}
// 6) release the fileblocks[]
if (attr -> type.fileblocks) {
free (attr -> type.fileblocks);
free (attr);
}
} else if (S_ISLNK (attr -> attr.mode)) {
// 7) a symlink, delete the contents
free (attr -> type.symlinkdata);
free (attr);
}
}
// 8) return EOK if everything went well
return (EOK);
}
Note that the definition of “empty” is slightly different for a directory. A directory is considered empty if it has just the two entries . and .. within it.
You'll also note that we call free() to release all the objects. It's important that all the objects be allocated (whether via malloc()/calloc() for the dirblocks and fileblocks, or via stdrup() for the symlinkdata).
The code walkthrough is as follows:
In normal (i.e. nonfilesystem) resource managers, the io_devctl() function is used to implement device control functions. We used this in the ADIOS data acquisition driver to, for example, get the configuration of the device.
In a filesystem resource manager, io_devctl() is used to get various information about the filesystem.
A large number of the commands aren't used for anything other than block I/O filesystems; a few are reserved for internal use only.
Here's a summary of the commands:
The DCMD_FSYS_MOUNTED_ON, DCMD_FSYS_MOUNTED_AT, and DCMD_FSYS_MOUNTED_BY commands allow traversal of the filesystem hierarchy by utilities (like df, dinit, and chkfsys) that need to move between the filesystem and the host/image of that filesystem.
For example, consider a disk with /dev/hd0t79 as a partition of /dev/hd0, mounted at the root (/), with a directory /tmp. The table below gives a summary of the responses for each command (shortened to just the two last letters of the command) for each entity:
| Command | /dev/hd0t79 | / | /tmp |
|---|---|---|---|
| ON | /dev/hd0 | /dev/hd0t79 | /dev/hd0t79 |
| AT | /dev/hd0t79 | / | / |
| BY | / |
ENODEV is returned when there is no such entity (for example, an ON query of /dev/hd0, or a BY query of /).
Basically:
The most important command that your filesystem should implement is the DCMD_FSYS_STATVFS. In our io_devctl() handler, this ends up calling the utility function cfs_block_fill_statvfs() (in lib/block.c):
void
cfs_block_fill_statvfs (cfs_attr_t *attr, struct statvfs *r)
{
uint32_t nalloc, nfree;
size_t nbytes;
mpool_info (mpool_block, &nbytes, &r -> f_blocks, &nalloc,
&nfree, NULL, NULL);
// INVARIANT SECTION
// file system block size
r -> f_bsize = nbytes;
// fundamental filesystem block size
r -> f_frsize = nbytes;
// total number of file serial numbers
r -> f_files = INT_MAX;
// file system id
r -> f_fsid = 0x12345678;
// bit mask of f_flag values
r -> f_flag = 0;
// maximum filename length
r -> f_namemax = NAME_MAX;
// null terminated name of target file system
strcpy (r -> f_basetype, "cfs");
// CALCULATED SECTION
if (optm) { // for system-allocated mem with a max
// tot number of blocks on file system in units of f_frsize
r -> f_blocks = optm / nbytes;
// total number of free blocks
r -> f_bfree = r -> f_blocks - nalloc;
// total number of free file serial numbers (approximation)
r -> f_ffree = r -> f_files - nalloc;
} else if (optM) { // for statically-allocated mem with a max
// total #blocks on file system in units of f_frsize
r -> f_blocks = optM / nbytes;
// total number of free blocks
r -> f_bfree = nfree;
// total number of free file serial numbers (approximation)
r -> f_ffree = nfree;
} else { // for unbounded system-allocated memory
// total #blocks on file system in units of f_frsize
r -> f_blocks = nalloc + 1;
// total number of free blocks
r -> f_bfree = r -> f_blocks - nalloc;
// total #free file serial numbers (an approximation)
r -> f_ffree = r -> f_files - nalloc;
}
// MIRROR
// number of free blocks available to non-priv. proc
r -> f_bavail = r -> f_bfree;
// number of file serial numbers available to non-priv. proc
r -> f_favail = r -> f_ffree;
}
The reason for the additional complexity (as opposed to just stuffing the fields directly) is due to the command-line options for the RAM disk. The -m option lets the RAM disk slowly allocate memory for itself as it requires it from the operating system, up to a maximum limit. If you use the -M option instead, the RAM disk allocates the specified memory right up front. Using neither option causes the RAM disk to allocate memory as required, with no limit.
Some of the numbers are outright lies — for example, the f_files value, which is supposed to indicate the total number of file serial numbers, is simply set to INT_MAX. There is no possible way that we would ever use that many file serial numbers (INT_MAX is 9 × 1018)!
So, the job of cfs_block_fill_statvfs() is to gather the information from the block allocator, and stuff the numbers (perhaps calculating some of them) into the struct statvfs structure.
The last function we'll look at is the one that handles mount requests. Handling a mount request can be fairly tricky (there are lots of options), so we've just stuck with a simple version that does everything we need for the RAM disk.
When the RAM-disk resource manager starts up, there is no mounted RAM disk, so you must use the command-line mount command to mount one:
mount -Tramdisk /dev/ramdisk /ramdisk
The above command creates a RAM disk at the mount point /ramdisk.
The code is:
int
cfs_c_mount (resmgr_context_t *ctp, io_mount_t *msg,
RESMGR_HANDLE_T *handle, io_mount_extra_t *extra)
{
char *mnt_point;
char *mnt_type;
int ret;
cfs_attr_t *cfs_attr;
// 1) shortcuts
mnt_point = msg -> connect.path;
mnt_type = extra -> extra.srv.type;
// 2) Verify that it is a mount request, not something else
if (extra -> flags &
(_MOUNT_ENUMERATE | _MOUNT_UNMOUNT | _MOUNT_REMOUNT)) {
return (ENOTSUP);
}
// 3) decide if we should handle this request or not
if (!mnt_type || strcmp (mnt_type, "ramdisk")) {
return (ENOSYS);
}
// 4) create a new attributes structure and fill it
if (!(cfs_attr = malloc (sizeof (*cfs_attr)))) {
return (ENOMEM);
}
iofunc_attr_init (&cfs_attr -> attr, S_IFDIR | 0777,
NULL, NULL);
// 5) initializes extended attribute structure
cfs_attr_init (cfs_attr);
// set up the inode
cfs_attr -> attr.inode = (int) cfs_attr;
// create "." and ".."
cfs_a_mknod (cfs_attr, ".", S_IFDIR | 0755, NULL);
cfs_a_mknod (cfs_attr, "..", S_IFDIR | 0755, NULL);
// 6) attach the new pathname with the new value
ret = resmgr_attach (dpp, &resmgr_attr, mnt_point,
_FTYPE_ANY, _RESMGR_FLAG_DIR,
&connect_func, &io_func,
&cfs_attr -> attr);
if (ret == -1) {
free (cfs_attr);
return (errno);
}
return (EOK);
}
The code walkthrough is:
The inode needs to be unique on a per-device basis, so the easiest way of doing that is to give it the address of the attributes structure.
The following references apply to this chapter.
See the following functions in the Neutrino C Library Reference: