The ASR uses various modules to perform tasks such as audio capture and import and to provide prompt services.
ASR services are launched through PPS when the user activates the Push-to-Talk tab on the HMI taskbar. These services use different ASR modules.
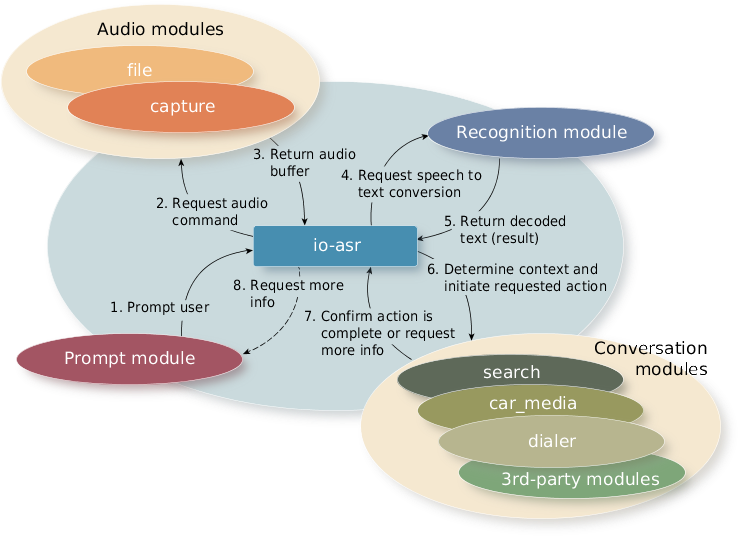 Figure 1. A typical ASR sequence to manage speech commands
Figure 1. A typical ASR sequence to manage speech commandsAudio capture module
The audio capture module detects the spoken command, including the beginning and end of sentences, and then forwards the audio stream to the third-party recognition modules.
Audio file module
The audio file module imports audio from a file, which it can save for future use. This module is used primarily for testing.
Recognition modules
The recognition module converts a spoken command (utterance) to text. It collects the audio sample, passes it to a third-party recognizer for processing, and converts the vendor-specific result data (dictation) to the format required by the ASR. The ASR service then passes this result on to the Natural Language Adaptation Layer (NLAL). The NLAL uses the grammar provided by the conversation module to produce intent information, which it adds to the data in the original result structure.
For example, the recognition module would take the utterance "search media for Hero" and create a results structure with the dictation as follows:
- Result Type: Dictation
- Utterance: "search media for Hero"
- start-rule: search#media-search
- confidence: 600
From this dictation, the NLAL would add intent information to the structure:
- Result Type: Intent
- Utterance: "search media for Hero"
- Start-rule: search-media
- Confidence: 600
- Intent entries: 2
- Field: search-type, value: media
- Field: search-term, value: "Hero"
Confidence is a value from 0 to 1000 (0 means no confidence; 1000 means complete confidence).
- The conversation modules need the intent fields to understand the meaning of an utterance; without them a conversation is impossible.
- Some recognition modules can produce intent results directly, bypassing the NLAL. The intents that are extracted by the NLAL are predicated by a grammar that must be provided with the conversation module.
Conversation modules
The conversation modules are responsible for:
- determining the domain (e.g., navigation, phone)
- determining whether the conversation is complete or whether another recognition pass is required
- creating and/or modifying PPS objects as required
Apps such as Media Player and Navigation subscribe to PPS objects for changes. For example, if the user presses the Push-to-Talk tab and says "play Arcade Fire", the recognition modules parse the command. The Media conversation module then activates the media engine, causing tracks from the desired artist to play.
Prompt modules
Used primarily by conversation modules, prompt modules provide audio and visual prompt services. Specifically, these modules provide notification of nonspeech responses to onscreen notifications (e.g., selecting an option or canceling a command). Prompts come from prerecorded WAV files or from Text-To-Speech (TTS).