 |
Running more than one pass-through filesystem or resource manager on overlapping pathname spaces might cause deadlocks. |
This chapter includes:
Since a filesystem resource manager may potentially receive long pathnames, it must be able to parse and handle each component of the path properly.
Let's say that a resource manager registers the mountpoint /mount/, and a user types:
ls -l /mount/home
where /mount/home is a directory on the device.
ls does the following:
d = opendir("/mount/home");
while (...) {
dirent = readdir(d);
...
}
If we wanted our resource manager to handle multiple devices, the change is really quite simple. We would call resmgr_attach() for each device name we wanted to register. We would also pass in an attributes structure that was unique to each registered device, so that functions such as chmod() would be able to modify the attributes associated with the correct resource.
Here are the modifications necessary to handle both /dev/sample1 and /dev/sample2:
/*
* MOD [1]: allocate multiple attribute structures,
* and fill in a names array (convenience)
*/
#define NumDevices 2
iofunc_attr_t sample_attrs [NumDevices];
char *names [NumDevices] =
{
"/dev/sample1",
"/dev/sample2"
};
int main ( void )
{
...
/*
* MOD [2]: fill in the attribute structure for each device
* and call resmgr_attach for each device
*/
for (i = 0; i < NumDevices; i++) {
iofunc_attr_init (&sample_attrs [i],
S_IFCHR | 0666, NULL, NULL);
pathID = resmgr_attach (dpp, &resmgr_attr, name[i],
_FTYPE_ANY, 0,
&my_connect_funcs,
&my_io_funcs,
&sample_attrs [i]);
}
...
}
The first modification simply declares an array of attributes, so that each device has its own attributes structure. As a convenience, we've also declared an array of names to simplify passing the name of the device in the for loop. Some resource managers (such as devc-ser8250) construct the device names on the fly or fetch them from the command line.
The second modification initializes the array of attribute structures and then calls resmgr_attach() multiple times, once for each device, passing in a unique name and a unique attribute structure.
Those are all the changes required. Nothing in our io_read or io_write handlers has to change — the iofunc-layer default functions will gracefully handle the multiple devices.
Up until this point, our discussion has focused on resource managers that associate each device name via discrete calls to resmgr_attach(). We've shown how to “take over” a single pathname. (Our examples have used pathnames under /dev, but there's no reason you couldn't take over any other pathnames, e.g. /MyDevice.)
A typical resource manager can take over any number of pathnames. A practical limit, however, is on the order of a hundred — the real limit is a function of memory size and lookup speed in the process manager.
What if you wanted to take over thousands or even millions of pathnames?
The most straightforward method of doing this is to take over a pathname prefix and manage a directory structure below that prefix (or mountpoint).
|
Running more than one pass-through filesystem or resource manager on overlapping pathname spaces might cause deadlocks. |
Here are some examples of resource managers that may wish to do this:
And those are just the most obvious ones. The reasons (and possibilities) are almost endless.
The common characteristic of these resource managers is that they all implement filesystems. A filesystem resource manager differs from the “device” resource managers (that we have shown so far) in the following key areas:
Let's look at these points in turn.
When we specified the flags argument to resmgr_attach() for our sample resource manager, we specified a 0, implying that the library should “use the defaults.”
If we specified the value _RESMGR_FLAG_DIR instead of 0, the library would allow the resolution of pathnames at or below the specified mountpoint.
Once we've specified a mountpoint, it would then be up to the resource manager to determine a suitable response to an open request. Let's assume that we've defined a mountpoint of /sample_fsys for our resource manager:
pathID = resmgr_attach
(dpp,
&resmgr_attr,
"/sample_fsys", /* mountpoint */
_FTYPE_ANY,
_RESMGR_FLAG_DIR, /* it's a directory */
&connect_funcs,
&io_funcs,
&attr);
Now when the client performs a call like this:
fopen ("/sample_fsys/spud", "r");
we receive an _IO_CONNECT message, and our io_open handler will be called. Since we haven't yet looked at the _IO_CONNECT message in depth, let's take a look now:
struct _io_connect {
unsigned short type;
unsigned short subtype; /* _IO_CONNECT_* */
unsigned long file_type; /* _FTYPE_* in sys/ftype.h */
unsigned short reply_max;
unsigned short entry_max;
unsigned long key;
unsigned long handle;
unsigned long ioflag; /* O_* in fcntl.h, _IO_FLAG_* */
unsigned long mode; /* S_IF* in sys/stat.h */
unsigned short sflag; /* SH_* in share.h */
unsigned short access; /* S_I in sys/stat.h */
unsigned short zero;
unsigned short path_len;
unsigned char eflag; /* _IO_CONNECT_EFLAG_* */
unsigned char extra_type; /* _IO_EXTRA_* */
unsigned short extra_len;
unsigned char path[1]; /* path_len, null, extra_len */
};
Looking at the relevant fields, we see ioflag, mode, sflag, and access, which tell us how the resource was opened.
The path_len parameter tells us how many bytes the pathname takes; the actual pathname appears in the path parameter. Note that the pathname that appears is not /sample_fsys/spud, as you might expect, but instead is just spud — the message contains only the pathname relative to the resource manager's mountpoint. This simplifies coding because you don't have to skip past the mountpoint name each time, the code doesn't have to know what the mountpoint is, and the messages will be a little bit shorter.
Note also that the pathname will never have relative (. and ..) path components, nor redundant slashes (e.g. spud//stuff) in it — these are all resolved and removed by the time the message is sent to the resource manager.
When writing filesystem resource managers, we encounter additional complexity when dealing with the pathnames. For verification of access, we need to break apart the passed pathname and check each component. You can use strtok() and friends to break apart the string, and then there's iofunc_check_access(), a convenient iofunc-layer call that performs the access verification of pathname components leading up to the target. (See the QNX Neutrino Library Reference page for the iofunc_open() for information detailing the steps needed for this level of checking.)
|
The binding that takes place after the name is validated requires that every path that's handled has its own attribute structure passed to iofunc_open_default(). Unexpected behavior will result if the wrong attribute is bound to the pathname that's provided. |
When the _IO_READ handler is called, it may need to return data for either a file (if S_ISDIR (ocb->attr->mode) is false) or a directory (if S_ISDIR (ocb->attr->mode) is true). We've seen the algorithm for returning data, especially the method for matching the returned data's size to the smaller of the data available or the client's buffer size.
A similar constraint is in effect for returning directory data to a client, except we have the added issue of returning block-integral data. What this means is that instead of returning a stream of bytes, where we can arbitrarily package the data, we're actually returning a number of struct dirent structures. (In other words, we can't return 1.5 of those structures; we always have to return an integral number.) The dirent structures must be aligned on 4-byte boundaries in the reply.
A struct dirent looks like this:
struct dirent {
#if _FILE_OFFSET_BITS - 0 == 64
ino_t d_ino; /* File serial number. */
off_t d_offset;
#elif !defined(_FILE_OFFSET_BITS) || _FILE_OFFSET_BITS == 32
#if defined(__LITTLEENDIAN__)
ino_t d_ino; /* File serial number. */
ino_t d_ino_hi;
off_t d_offset;
off_t d_offset_hi;
#elif defined(__BIGENDIAN__)
ino_t d_ino_hi;
ino_t d_ino; /* File serial number. */
off_t d_offset_hi;
off_t d_offset;
#else
#error endian not configured for system
#endif
#else
#error _FILE_OFFSET_BITS value is unsupported
#endif
int16_t d_reclen;
int16_t d_namelen;
char d_name[1];
};
The d_ino member contains a mountpoint-unique file serial number. This serial number is often used in various disk-checking utilities for such operations as determining infinite-loop directory links. (Note that the inode value cannot be zero, which would indicate that the inode represents an unused entry.)
In some filesystems, the d_offset member is used to identify the directory entry itself; in others, it's the offset of the next directory entry. For a disk-based filesystem, this value might be the actual offset into the on-disk directory structure.
The d_reclen member contains the size of this directory entry and any other associated information (such as an optional struct stat structure appended to the struct dirent entry; see below).
The d_namelen parameter indicates the size of the d_name parameter, which holds the actual name of that directory entry. (Since the size is calculated using strlen(), the \0 string terminator, which must be present, is not counted.)
|
The dirent structure includes space only for the
first four bytes of the
name; your _IO_READ handler needs to return the name and
the struct dirent as a
bigger structure:
struct {
struct dirent ent;
char namebuf[NAME_MAX + 1 + offsetof(struct dirent, d_name) -
sizeof( struct dirent)];
} entry
or as a union:
union {
struct dirent ent;
char filler[ offsetof( struct dirent, dname ) + NAME_MAX + 1];
} entry;
|
So in our io_read handler, we need to generate a number of struct dirent entries and return them to the client. If we have a cache of directory entries that we maintain in our resource manager, it's a simple matter to construct a set of IOVs to point to those entries. If we don't have a cache, then we must manually assemble the directory entries into a buffer and then return an IOV that points to that.
Instead of returning just the struct dirent in the _IO_READ message, you can also return a struct stat. Although this will improve efficiency, returning the struct stat is entirely optional. If you don't return one, the users of your device will then have to call stat() or lstat() to get that information. (This is basically a usage question. If your device is typically used in such a way that readdir() is called, and then stat() is called, it will be more efficient to return both. See the documentation for readdir() in the QNX Neutrino Library Reference for more information.)
The client can set the xtype member of the message to _IO_XFLAG_DIR_EXTRA_HINT to send a hint to the filesystem to return the extra information, however the filesystem isn't guaranteed to do so. If the resource manager provides the information, it must put it in a struct dirent_extra_stat, which is defined as follows:
struct dirent_extra_stat {
uint16_t d_datalen;
uint16_t d_type;
uint32_t d_reserved;
struct stat d_stat;
};
The resource manager must set d_type to _DTYPE_LSTAT or _DTYPE_STAT, depending on whether or not it resolves symbolic links. For example:
if(msg->i.xtype & _IO_XFLAG_DIR_EXTRA_HINT) {
struct dirent_extra_stat extra;
extra.d_datalen = sizeof extra.d_stat;
extra.d_type = _DTYPE_LSTAT;
extra.d_reserved = 0;
iofunc_stat(ctp, &attr, &extra.d_stat);
...
}
There's a dirent_extra_stat after each directory entry:
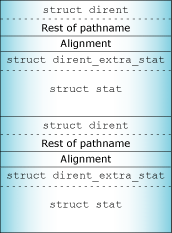
Returning the optional struct dirent_extra_stat along with the struct dirent entry can improve efficiency.
|
The dirent structures must be aligned on 4-byte boundaries, and the dirent_extra_stat structures on 8-byte boundaries. The d_reclen member of the struct dirent must contain the size of both structures, including any space necessary for the pathname and alignment. There must be no more than seven bytes of alignment filler. |
The client has to check for extra data by using the _DEXTRA_*() macros (see the entry for readdir() in the QNX Neutrino Library Reference.) If this check fails, the client will need to call lstat() or stat() explicitly. For example, ls -l checks for extra _DTYPE_LSTAT information; if it isn't present, ls calls lstat(). The ls -L command checks for extra _DTYPE_STAT information; if it isn't present, ls calls stat().