 |
This chapter was first published in QNX Software Systems' email magazine, QNX Source, as a two-part series. |
|
This chapter was first published in QNX Software Systems' email magazine, QNX Source, as a two-part series. |
This chapter includes:
When you're first designing a project using Neutrino, a question that often arises is “how should I structure my design?” This chapter answers that question by examining the architecture of a sample application; a security system with door locks, card readers, and related issues. We'll discuss process granularity — what components should be put into what size of containers. That is, what the responsibilities of an individual process should be, and where you draw the line between processes.
Neutrino is advertised as a “message-passing” operating system. Understanding the true meaning of that phrase when it comes to designing your system can be a challenge. Sure, you don't need to understand this for a standard “UNIX-like” application, like a web server, or a logging application. But it becomes an issue when you're designing an entire system. A common problem that arises is design decoupling. This problem often shows up when you ask the following questions:
Here are the short answers, in order:
In this chapter, we're going to look into these issues, using a reasonably simple situation:
Say you're the software architect for a security company, and you're creating the software design for a security system. The hardware consists of swipe-card readers, door lock actuators, and various sensors (smoke, fire, motion, glass-break, etc.). Your company wants to build products for a range of markets — a small security system that's suitable for a home or a small office, up to gigantic systems that are suitable for large, multi-site customers. They want their systems to be upgradable, so that as a customer's site grows, they can just add more and more devices, without having to throw out the small system to buy a whole new medium or large system (go figure!). Finally, any systems should support any device (the small system might be a super-high security area, and require some high-end input devices).
Your first job is to sketch out a high-level architectural overview of the system, and decide how to structure the software. Working from our goals, the implied requirements are that the system must support various numbers of each device, distributed across a range of physical areas, and it must be future-proof so you can add new types of sensors, output devices, and so on as your requirements change or as new types of hardware become available (e.g. retinal scanners).
The first step is to define the functional breakdown and answer the question, “How much work should one process do?”
If we step back from our security example for a moment, and consider a database program, we'll see some of the same concepts. A database program manages a database — it doesn't worry about the media that the data lives on, nor is it worried about the organization of that media, or the partitions on the hard disk, etc. It certainly does not care about the SCSI or EIDE disk driver hardware. The database uses a set of abstract services supplied by the filesystem — as far as the database is concerned, everything else is opaque — it doesn't need to see further down the abstraction chain. The filesystem uses a set of abstract services from the disk driver. Finally, the disk driver controls the hardware. The obvious advantage of this approach is this: because the higher levels don't know the details of the lower levels, we can substitute the lower levels with different implementations, if we maintain the well-defined abstract interfaces.
Thinking about our security system, we can immediately start at the bottom (the hardware) — we know we have different types of hardware devices, and we know the next level in the hierarchy probably does not want to know the details of the hardware. Our first step is to draw the line at the hardware interfaces. What this means is that we'll create a set of device drivers for the hardware and provide a well-defined API for other software to use.
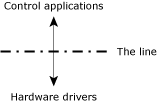
We've drawn the line between the control applications and the hardware drivers.
We're also going to need some kind of control application. For example, it needs to verify that Mr. Pink actually has access to door number 76 at 06:30 in the morning, and if that's the case, allow him to enter that door. We can already see that the control software will need to:
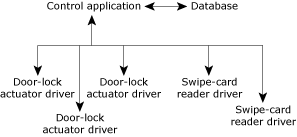
In the next design phase, we've identified some of the hardware components, and slightly refined the control application layer.
Once we have these two levels defined, we can sort out the interface. Since we've analyzed the requirements at a higher level, we know what “shape” our interface will take on the lower level.
For the swipe-card readers, we're going to need to know:
For the door-lock actuator hardware, we're going to need to open the door, and lock the door (so that we can let Mr. Pink get in, but lock the door after him).
Earlier, we mentioned that this system should scale — that is, it should operate in a small business environment with just a few devices, right up to a large campus environment with hundreds (if not thousands) of devices.
When you analyze a system for scalability, you're looking at the following:
As we'll see, these scalability concerns are very closely tied in with the way that we've chosen to break up our design work. If we put too much functionality into a given process (say we had one process that controls all the door locks), we're limiting what we can do in terms of distributing that process across multiple CPUs. If we put too little functionality into a process (one process per function per door lock), we run into the problem of excessive communications and overhead.
So, keeping these goals in mind, let's look at the design for each of our hardware drivers.
We'll start with the door-lock actuators, because they're the simplest to deal with. The only thing we want this driver to do is to let a door be opened, or prevent one from being opened — that's it! This dictates the commands that the driver will take — we need to tell the driver which door lock it should manipulate, and its new state (locked or unlocked). For the initial software prototype, those are the only commands that I'd provide. Later, to offload processing and give us the ability to support new hardware, we might consider adding more commands.
Suppose you have different types of door-lock actuators — there are at least two types we should consider. One is a door release mechanism — when active, the door can be opened, and when inactive, the door cannot be opened. The second is a motor-driven door mechanism — when active, the motor starts and causes the door to swing open; when inactive, the motor releases the door allowing it to swing closed. These might look like two different drivers, with two different interfaces. However, they can be handled by the same interface (but not the same driver).
All we really want to do is let someone go through the door. Naturally, this means that we'd like to have some kind of timer associated with the opening of the door. When we've granted access, we'll allow the door to remain unlocked for, say, 20 seconds. After that point, we lock the door. For certain kinds of doors, we might wish to change the time, longer or shorter, as required.
A key question that arises is, “Where do we put this timer?” There are several possible places where it can go:
This comes back to design decoupling (and is related to scalability).
If we put the timing functionality into the control program, we're adding to its workload. Not only does the control program have to handle its normal duties (database verification, operator displays, etc.), it now also has to manage timers.
For a small, simple system, this probably won't make much of a difference. But once we start to scale our design into a campus-wide security system, we'll be incurring additional processing in one central location. Whenever you see the phrase “one central location” you should immediately be looking for scalability problems. There are a number of significant problems with putting the functionality into the control program:
The short answer here is that the control program really shouldn't have to manage the timers. This is a low-level detail that's ideally suited to being offloaded.
Let's consider the next point. Should we have a process that manages the timers, and then communicates with the door-lock actuators? Again, I'd answer no. The scalability and security aspects raised above don't apply in this case (we're assuming that this timer manager could be distributed across various CPUs, so it scales well, and since it's on the same CPU we can eliminate the communications failure component). The upgradability aspect still applies, however.
But there's also a new issue — functional clustering. What I mean by that is that the timing function is tied to the hardware. You might have dumb hardware where you have to do the timing yourself, or you might have smart hardware that has timers built into it.
In addition, you might have complicated hardware that requires multi-phase sequencing. By having a separate manager handle the timing, it has to be aware of the hardware details. The problem here is that you've split the hardware knowledge across two processes, without gaining any advantages. On a filesystem disk driver, for example, this might be similar to having one process being responsible for reading blocks from the disk while another one was responsible for writing. You're certainly not gaining anything, and in fact you're complicating the driver because now the two processes must coordinate with each other to get access to the hardware.
That said, there are cases where having a process that's between the control program and the individual door locks makes sense.
Suppose that we wanted to create a meta door-lock driver for some kind of complicated, sequenced door access (for example, in a high security area, where you want one door to open, and then completely close, before allowing access to another door). In this case, the meta driver would actually be responsible for cycling the individual door lock drivers. The nice thing about the way we've structured our devices is that as far as the control software is concerned, this meta driver looks just like a standard door-lock driver — the details are hidden by the interface.
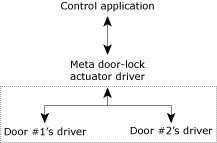
The meta door-lock driver presents the same interface as a regular door-lock driver.
Our security system isn't complete! We've just looked at the door locks and illustrated some of the common design decisions that get made. Our goals for the door-lock driver were for the process to do as much work as was necessary to provide a clean, simple, abstract interface for higher levels of software to use. We used functional clustering (guided by the capabilities of the hardware) when deciding which functions were appropriate for the driver, and which functions should be left to other processes. By implication, we saw some of the issues associated with constructing a large system as a set of small, well-defined building blocks, which could all be tested and developed individually. This naturally led us to design a system that will allow new types of modules to be added seamlessly.
Once you've laid out your initial design, it's important to understand the send hierarchy and its design impact. In this section, we'll examine which processes should be data sources and which should be data sinks, as well as the overall structure of a larger system.
Once the message flow is understood, we'll look at more scalability issues.
Let's focus on the swipe-card readers to illustrate some message flow and scalability concepts.
The swipe-card reader driver is a fairly simple program — it waits for a card to be swiped through the hardware, and then collects the card ID. While the driver itself is reasonably simple, there's a major design point we need to consider that's different than what we've seen so far with the door lock driver. Recall that the door-lock driver acted as a data sink — the control process sent it commands, telling it to perform certain actions. With the swipe-card reader, we don't want it to be a data sink. We don't want to ask the swipe card reader if it has data yet; we want it to tell us when someone swipes their access card. We need the swipe-card reader to be a data source — it should provide data to another application when the data is available.
To understand this, let's think about what happens in the control program. The control program needs to know which user has swiped their card. If the control program kept asking the swipe card reader if anything had happened yet, we'd run into at a scalability problem (via polling), and possibly a blocking problem.
The scalability problem stems from the fact that the control program is constantly inquiring about the status of the swipe card reader. This is analogous to being on a road trip with kids who keep asking “Are we there yet?” It would be more efficient (but far more unlikely) for them to ask (once!) “Tell us when we get there.”
If the control program is continually polling, we're wasting CPU cycles — it costs us to ask, and it costs us to get an answer. Not only are we wasting CPU, but we could also be wasting network bandwidth in a network-distributed system. If we only have one or two swipe-card readers, and we poll them once per second, this isn't a big deal. However, once we have a large number of readers, and if our polling happens faster, we'll run into problems.
Ideally, we'll want to have the reader send us any data that it has as soon as it's available. This is also the intuitive solution; you expect something to happen as soon as you swipe your card.
The blocking problem could happen if the control program sent a message to the reader driver asking for data. If the reader driver didn't have any data, it could block — that is, it wouldn't reply to the client (who is asking for the data) until data became available. While this might seem like a good strategy, the control program might need to ask multiple reader drivers for data. Unless you add threads to the control program (which could become a scalability problem), you'd have a problem — the control program would be stuck waiting for a response from one swipe-card reader. If this request was made on a Friday night, and no one swiped in through that particular card reader until Monday morning, the control program would be sitting there all weekend, waiting for an answer.
Meanwhile, someone could be trying to swipe in on Saturday morning through a different reader. Gratuitously adding threads to the control program (so there's one thread per swipe card reader) isn't necessarily an ideal solution either. It doesn't scale well. While threads are reasonably inexpensive, they still have a definite cost — thread-local memory, some internal kernel data structures, and context-switch overhead. It's the memory footprint that'll have the most impact (the kernel data structures used are relatively small, and the context-switch times are very fast). Once you add these threads to the control program, you'll need to synchronize them so they don't contend for resources (such as the database). The only thing that these threads buy you is the ability to have multiple blocking agents within your control program.
At this point, it seems that the solution is simple. Why not have the swipe-card reader send a message to the control program, indicating that data is available? This way, the control program doesn't have to poll, and it doesn't need a pool of threads. This means that the swipe-card reader is a “data source,” as we suggested above.
There's one subtle but critical point here. If the reader sends a message to the control program, and the control program sends a message to the reader at the same time, we'll run into a problem. Both programs sent messages to each other, and are now deadlocked, waiting for the other program to respond to their messages. While this might be something that only happens every so often, it'll fail during a demo rather than in the lab, or worse, it'll fail in the field.
Why would the control program want to send a message to the swipe-card reader in the first place? Well, some readers have an LED that can be used to indicate if access was allowed or not — the control program needs to set this LED to the correct color. (Obviously, in this example, there are many ways of working around this; however, in a general design, you should never design a system that even has a hint of allowing a deadlock!)
The easiest way around this deadlock is to ensure that it never happens. This is done with something called a send hierarchy. You structure your programs so those at one level always send messages to those at a lower level, but that those at lower levels never send messages to those at higher (or the same) levels. In this way, two programs will never send each other messages at the same time.
Unfortunately, this seems to break the simple solution that we had earlier: letting the swipe-card reader driver send a message to the control program. The standard solution to this is to use a non-blocking message (a Neutrino-specific “pulse”). This message can be sent up the hierarchy, and doesn't violate our rules because it doesn't block the sender. Even if a higher level used a regular message to send data to a lower level at the same time the lower level used the pulse to send data to the higher level, the lower level would receive and process the message from the higher level, because the lower level wouldn't be blocked.
Let's put that into the context of our swipe-card reader. The control program would “prime” the reader by sending it a regular message, telling it to send a pulse back up whenever it has data. Then the control program goes about its business. Some time later, when a card is swiped through the reader, the driver sends a pulse to the control program. This tells the control program that it can now safely go and ask the driver for the data, knowing that data is available, and that the control program won't block. Since the driver has indicated that it has data, the control program can safely send a message to the driver, knowing that it'll get a response back almost instantly.
In the following diagram, there are a number of interactions:
A well-defined message-passing hierarchy prevents deadlocks.
Using this send hierarchy strategy, we have the swipe-card driver at the bottom, with the control program above it. This means that the control program can send to the driver, but the driver needs to use pulses to transfer indications “up” to the control program. We could certainly have this reversed: have the driver at the top, sending data down to the control program. The control program would use pulses to control the LED status on the swipe-card hardware to indicate access granted or denied.
Why would we prefer one organization over the other? What are the impacts and trade-offs?
Let's look at the situation step-by-step to see what happens in both cases.
In the case where the Control Program (Control) is sending data to the Swipe-Card Reader (Swipe), we have the following steps:
In this case, there was one pulse, and three messages. Granted, you would prime the event just once, so the first message can be eliminated.
If we invert the relationship, here's what happens:
In this case, there was one pulse, and just one message.
An important design note is that the LED color change was accomplished with a reply in one case (to change it to green), and a pulse in another case (to change it to red). This may be a key point for your design, depending on how much data you need to carry in the pulse. In our example, simply carrying the color of the LED is well within the capabilities of the pulse.
Let's see what happens when we add a keypad to the system. The purpose of the keypad is for Control to issue a challenge to the person trying to open the door; they must respond with some kind of password.
In the case where Control is sending data to Swipe, in conjunction with a keypad challenge, we have the following steps:
In this case, there were two pulses and six messages. Again, the initial priming message could be discounted.
If we invert the relationship, here's what happens:
In this case, there was one pulse and two messages.
So, by carefully analyzing the transactions between your clients and servers, and by being able to carry useful data within pulses, you can make your transactions much more efficient! This has ramifications over a network connection, where message speeds are much slower than locally.
The next issue we need to discuss is scalability. Scalability can be summarized by the question, “Can I grow this system by an order of magnitude (or more) and still have everything work?” To answer this question, you have to analyze a number of factors:
The first point is probably self-evident. If you're using half of the CPU time and half of the memory of your machine, then you probably won't be able to more than double the size of the system (assuming that the resource usage is linearly increasing with the size of the system).
Closely related to that is the second point — if you're doing a lot of message passing, you will eventually “max out” the message passing bandwidth of whatever medium you're using. If you're only using 10% of the CPU but 90% of the bandwidth of your medium, you'll hit the medium's bandwidth limit first.
This is tied to the third point, which is the real focus of the scalability discussion here.
If you're using a good chunk of the resources on a particular machine (also called a node under Neutrino), the traditional scalability solution is to share the work between multiple nodes. In our security example, let's say we were scaling up to a campus-wide security system. We certainly wouldn't consider having one CPU responsible for hundreds (or thousands) of door lock actuators, swipe card readers, etc. Such a system would probably die a horrible death immediately after a fire drill, when everyone on the campus has to badge-in almost simultaneously when the all-clear signal is given.
What we'd do instead is set up zone controllers. Generally, you'd set these up along natural physical boundaries. For example, in the campus that you're controlling, you might have 15 buildings. I'd immediately start with 15 controller CPUs; one for each building. This way, you've effectively reduced most of the problem into 15 smaller problems — you're no longer dealing with one, large, monolithic security system, but instead, you're dealing with 15 individual (and smaller) security systems.
During your design phase, you'd figure out what the maximum capacity of a single CPU was — how many door-lock actuators and swipe-card readers it could handle in a worst-case scenario (like the fire drill example above). Then you'd deploy CPUs as appropriate to be able to handle the expected load.
While it's good that you now have 15 separate systems, it's also bad — you need to coordinate database updates and system-level monitoring between the individual systems. This is again a scalability issue, but at one level higher. (Many commercial off-the-shelf database packages handle database updates, high availability, fail-overs, redundant systems, etc. for you.)
You could have one CPU (with backup!) dedicated to being the master database for the entire system. The 15 subsystems would all ask the one master database CPU to validate access requests. Now, it may turn out that a single CPU handling the database would scale right up to 200 subsystems, or it might not. If it does, then your work is done — you know that you can handle a fairly large system. If it doesn't, then you need to once again break the problem down into multiple subsystems.
In our security system example, the database that controls access requests is fairly static — we don't change the data on a millisecond-to-millisecond basis. Generally, we'd update the data only when a new employee joins the company, one gets terminated, someone loses their card, or the access permissions for an employee change.
To distribute this database, we can simply have the main database server send out updates to each of its “mirror” servers. The mirror servers are the ones that then handle the day-to-day operations of access validation. This nicely addresses the issue of a centralized outage — if the main database goes down, all of the mirror servers will still have a fairly fresh update. Since you've designed the central database server to be redundant, it'll come back up real soon, and no one will notice the outage.
For purposes of illustration, let's say that the data did in fact change very fast. How would we handle that? The standard solution here is “distributed processing.”
We'd have multiple database servers, but each one would handle only a certain subset of the requests. The easiest way to picture this is to imagine that each of the swipe cards has a 32-bit serial number to identify the swipe card.
If we needed to break the database server problem down into, say, 16 sub-problems, then you could do something very simple. Look at the four least significant bits of the serial number, and then use that as a server address to determine which server should handle the request. (This assumes that the 32-bit serial numbers have an even distribution of least-significant four-bit addresses; if not, there are plenty of other hashing algorithms.) Need to break the problem into 32 “sub-problems?” Just look at the five least significant bits of the serial number, and so on.
This kind of approach is done all the time at trade shows — you'll see several registration desks. One might have “Last Name A-H,” “Last Name I-P,” and “Last Name Q-Z” to distribute the hoards of people into three separate streams. Depending on where you live, your local driver's license bureau may do something similar — your driver's license expires on your birthday. While there isn't necessarily a completely even distribution of birthdays over the days of the year, it does distribute the problem somewhat evenly.
I've shown you some of the basic implications of message passing, notably the send hierarchy and how to design with it in mind to avoid deadlocks. We've also looked at scalability and distributed processing, noting that the idea is to break the problem down into a number of sub-problems that can be distributed among multiple CPUs.