![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
This chapter includes:
The adaptive partitioning thread scheduler is an optional thread scheduler that lets you guarantee minimum percentages of the CPU's throughput to groups of threads, processes, or applications. The percentage of the CPU allotted to a partition is called a budget.
The thread scheduler was designed on top of the core QNX Neutrino architecture to primarily solve two problems in embedded systems design:
We call our partitions “adaptive” because their contents are dynamic:
The adaptive partitioning thread scheduler throttles CPU usage by measuring the average CPU usage of each partition. The average is computed over an averaging window (typically 100 milliseconds), a value that is configurable.
However, the thread scheduler doesn't wait 100 milliseconds to compute the average. In fact, it calculates it very often. As soon as 1 millisecond passes, the usage for this 1 millisecond is added to the usage of the previous 99 milliseconds to compute the total CPU usage over the averaging window (i.e. 100 milliseconds).
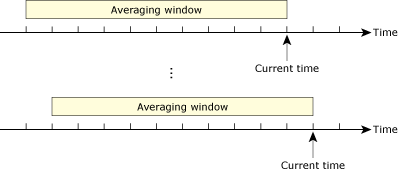
The averaging window moves forward as time advances.
The window size defines the averaging time over which the thread scheduler attempts to balance the partitions to their guaranteed CPU limits. You can set the averaging window size to any value from 8 milliseconds to 400 milliseconds.
Different choices of the window size affect both the accuracy of load balancing and, in extreme cases, the maximum delays seen by ready-to-run threads. For more information, see the Considerations for The Thread Scheduler chapter.
Because the averaging window slides, it can be difficult for you to keep statistics over a longer period, so the scheduler keeps track of two other windows:
To view the statistics for these additional windows, use the show -v or show -vv option with the aps command.
The thread scheduler accounts for time spent to the actual fraction of clock ticks used, and accounts for the time spent in interrupt threads and in the kernel on behalf of user threads. We refer to this as microbilling.
 |
Microbilling may be approximated on SH and ARM targets if the board can't provide a micro clock. |
The thread scheduler is a fair-share scheduler. This means that it guarantees that partitions receive a defined minimum amount of CPU time (their budget) whenever they demand it. The thread scheduler is also a real time scheduler. That means it's a preemptive, priority-based scheduler. However, these two requirements appear to conflict, but the thread scheduler satisfies both of these requirements by scheduling through priority at all times so that it doesn't need to limit a partition in order to guarantee some other partition its budget. For more information, refer to these topics:
Underload occurs when partitions demand less CPU time than their defined budgets, over the averaging window. For example, if we have three partitions:
with light demand in all three partitions, the output of the aps show command might be something like this:
+---- CPU Time ----+-- Critical Time --
Partition name id | Budget | Used | Budget | Used
--------------------+------------------+-------------------
System 0 | 70% | 6.23% | 200ms | 0.000ms
Pa 1 | 20% | 15.56% | 0ms | 0.000ms
Pb 2 | 10% | 5.23% | 0ms | 0.000ms
--------------------+------------------+-------------------
Total | 100% | 27.02% |
In this case, all three partitions demand less than their budgets.
Whenever partitions demand less than their budgets, the thread scheduler chooses between them by picking the highest-priority running thread. In other words, when underloaded, the thread scheduler is a strict real time scheduler. This is simply typical of Neutrino scheduling.
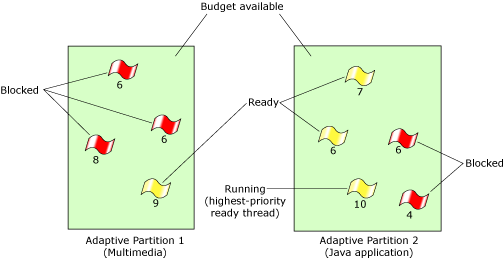
The thread scheduler's behavior when underloaded.
Free time occurs when one partition isn't running. The thread scheduler then gives that partition's time to other running partitions. If the other running partitions demand enough time, they're allowed to run over budget.
If a partition opportunistically goes over budget, it must pay back the borrowed time, but only as much as the scheduler “remembers” (i.e. only the borrowing that occurred in the last window).
For example, suppose we have these partitions:
Because the System partition demands no time, the thread scheduler distributes the remaining time to the highest-priority thread in the system. In this case, that's the infinite-loop thread in partition Pb. So the output of the aps show command may be:
+---- CPU Time ----+-- Critical Time --
Partition name id | Budget | Used | Budget | Used
--------------------+------------------+-------------------
System 0 | 70% | 0.11% | 200ms | 0.000ms
Pa 1 | 20% | 20.02% | 0ms | 0.000ms
Pb 2 | 10% | 79.83% | 0ms | 0.000ms
--------------------+------------------+-------------------
Total | 100% | 99.95% |
In this example, partition Pa receives its guaranteed minimum of 20%, but all of the free time is given to partition Pb.
This is a consequence of the principle that the thread scheduler chooses between partitions strictly by priority, as long as no partition is being limited to its budget. This strategy ensures the most real time behavior.
However, there may be circumstances when you don't want partition Pb to receive all of the free time just because it has the highest-priority thread. That may occur when, say, when you choose to use Pb to encapsulate an untrusted or third-party application, particularly when you are unable control its code.
In that case, you may want to configure the thread scheduler to run a more restrictive algorithm that divides free time by the budgets of the busy partitions (rather than assigning all of it to the highest-priority thread). To do so, set the SCHED_APS_FREETIME_BY_RATIO flag with SchedCtl() (see the Neutrino Library Reference), or use the aps modify -S freetime_by_ratio command (see the Utilities Reference).
In our example, freetime-by-ratio mode might cause the aps show command to display:
+---- CPU Time ----+-- Critical Time --
Partition name id | Budget | Used | Budget | Used
--------------------+------------------+-------------------
System 0 | 70% | 0.04% | 200ms | 0.000ms
Pa 1 | 20% | 65.96% | 0ms | 0.000ms
Pb 2 | 10% | 33.96% | 0ms | 0.000ms
--------------------+------------------+-------------------
Total | 100% | 99.96% |
which indicates that in freetime-by-ratio mode, the thread scheduler divides free time between partitions Pa and Pb in roughly a 2:1 ratio, which is the ratio of their budgets.
Full load occurs when all partitions demand their full budget. A simple way to demonstrate this is to run while(1) loops in all of the sample partitions. In this case, the aps show command might display:
+---- CPU Time ----+-- Critical Time --
Partition name id | Budget | Used | Budget | Used
--------------------+------------------+-------------------
System 0 | 70% | 69.80% | 200ms | 0.000ms
Pa 1 | 20% | 19.99% | 0ms | 0.000ms
Pb 2 | 10% | 9.81% | 0ms | 0.000ms
--------------------+------------------+-------------------
Total | 100% | 99.61% |
In this example, the requirement to meet the partitions' guaranteed budgets takes precedence over priority.
In general, when partitions are at or over their budget, the thread scheduler divides time between them by the ratios of their budgets, and balances usage to a few percentage points of the partitions' budgets. (For more information on budget accuracy, see “Choosing the window size” in the “Considerations for Scheduling” chapter of this guide.)
Even at full load, the thread scheduler can provide real time latencies to an engineerable set of critical threads (see “Critical threads” later in this chapter). However, in that case, the scheduling of critical threads takes precedence over meeting budgets.
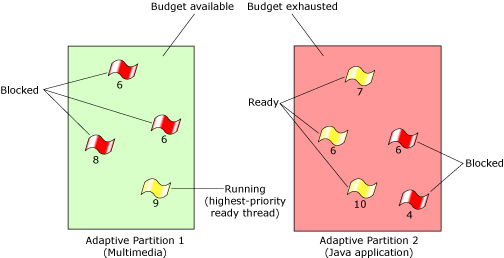
The thread scheduler's behavior under a full load.
The following table summarizes how the thread scheduler divides time in normal and freetime-by-ratio mode:
| Partition state | Normal | Freetime-by-ratio |
|---|---|---|
| Usage < budget | By priority | By priority |
| Usage > budget and there's free time | By priority | By ratio of budgets |
| Full load | By ratio of budgets | By ratio of budgets |
| Partitions running a critical thread at any load | By priority | By priority |
|
The scheduler's overhead doesn't increase with the number of threads; however, it may increase with the number of partitions, so you should use as few partitions as possible. |
Whenever a server thread in the standard Neutrino send-receive-reply messaging scheme receives a message from a client, Neutrino considers the server thread to be working on behalf of the client. So Neutrino runs the server thread at the priority of the client. In other words, threads receiving messages inherit the priority of their sender.
With the thread scheduler, this concept is extended; we run server threads in the partition of their client thread while the server is working on behalf of that client. So the receiver's time is billed to the sender's scheduler partition.
|
If you don't want the server or any threads or processes it creates to run in the client's partition, set the _NTO_CHF_FIXED_PRIORITY flag when the server creates its channel. For more information, see ChannelCreate() in the Neutrino Library Reference. |
|
Send-receive-reply message-passing is the only form of thread communication that automatically makes the server inherit the client's partition. |
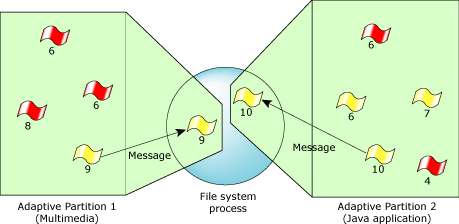
Server threads temporarily join the partition of the threads they work for.
Pulses don't inherit the sender's partition. Instead, their handlers run in the process's pulse-processing partition, which by default is the partition that the process was initially created in. You can change the pulse-processing partition with the SCHED_APS_JOIN_PARTITION command to SchedCtl(), specifying the process ID, along with a thread ID of -1.
A critical thread is one that's allowed to run even if its partition is over budget (provided that partition has a critical time budget). By default, Neutrino automatically identifies all threads that are initiated by an I/O interrupt as critical. However, you can use SchedCtl() to mark selected threads as critical.
|
The ability to mark any thread as critical may require security control to prevent its abuse as a DOS attack. For information about security, see “ Managing security for the thread scheduler” in the “Security for Scheduler Partitions” chapter of this guide. |
Critical threads always see real time latencies, even when the system is fully loaded, or any time other threads in the same partition are being limited to meet budgets. The basic idea is that a critical thread is allowed to violate the budget rules of its partition and run immediately, thereby obtaining the real time response it requires. For this to work properly, there must not be many critical threads in the system.
You can use a sigevent to make a thread run as critical:
struct sigevent my_event;
SIGEV_PULSE_INIT (&my_event, coid, 10,
MY_SIGNAL_CODE, 6969);
SIGEV_MAKE_CRITICAL(&my_event);
This has an effect only if the thread receiving your event runs in a partition with a critical-time budget.
To make a thread noncritical, you can use the SIGEV_CLEAR_CRITICAL() macro when you set up a sigevent.
|
The SIGEV_CLEAR_CRITICAL() and SIGEV_MAKE_CRITICAL()
macros set a hidden bit in the
sigev_notify field.
If you test the value of the sigev_notify field of your
sigevent after creating it, and if you've ever used
the SIGEV_MAKE_CRITICAL() macro, then use code like this:
switch (SIGEV_GET_TYPE(&my_event) ) {
instead of this:
switch (my_event.sigev_notify) {
|
A thread that receives a message from a critical thread automatically becomes critical as well.
You may mark selected scheduler partitions as critical and assign each partition a critical time budget. Critical time is specifically intended to allow critical interrupt threads to run over budget.
The critical time budget is specified in milliseconds. It's the amount of time all critical threads may use during an averaging window. A critical thread will run even if its scheduler partition is out of budget, as long as its partition has critical budget remaining.
Critical time is billed against a partition while all these conditions are met:
Otherwise, the critical time isn't billed. The critical threads run whether or not the time is billed as critical. The only time critical threads won't run is when their partition has exhausted its critical budget (see “Bankruptcy,” below).
In order to be useful and effective, the number of critical threads in the system must be few, and it's also ideal to give them high and unique priorities. Consequently, if critical threads are the majority, the thread scheduler will rarely be able to guarantee all of the partitions their minimum CPU budgets. In other words, the system degrades to a priority-based thread scheduler when there are too many critical threads.
To gain benefit from being critical, a critical thread must be the highest priority thread in the system, and not share its priority with other threads. If a ready-to-run critical thread is behind other noncritical threads (either because others have a higher priority, or are at the same priority and were made ready before your critical thread), then the critical thread may stall if the partition is out of budget.
Although your thread is critical, it must wait for a higher priority, and earlier threads sharing its partition to run first. However, if those other threads are noncritical, and if the partition is out of budget, your critical thread will not run until the averaging window rotates so that the partition once again has a budget.
A critical thread remains critical until it becomes receive-blocked. A critical thread that's being billed for critical time will not be round robin timesliced (even if its scheduling policy is round robin).
|
Neutrino marks all sigevent structures that are returned from a user's interrupt-event handler functions as critical. This makes all I/O handling threads automatically critical. This is done to minimize code changes that you would need to do for basic use of partition thread scheduling. If you don't want this behavior to occur, specify the -c option to procnto in your buildfile. |
To make a partition's critical budget infinite, set it to the number of processors times the size of the averaging window. Do this with caution, as it can cause security problems; see “Manageing Security for the Thread Scheduler” in the “Considerations for The Thread Scheduler”chapter of this guide.
Bankruptcy occurs when the critical CPU time billed to a partition exceeds its critical budget.
|
The System partition's critical budget is infinite; this partition can never become bankrupt. |
It's very important that you test your system under a full load to ensure that everything works correctly; in particular, to ensure that you've chosen the correct critical budgets. One method to verify this is to start a while(1) thread in each partition to consume all available time.
Bankruptcy is always considered to be a design error on the part of the application, but the system's response is configurable. Neutrino lets you set a recovery policy. The options are:
You can set the bankruptcy policy with the aps utility (see the Utilities Reference) or the SCHED_APS_SET_PARMS command to SchedCtl() (see the Neutrino Library Reference).
Whenever a critical or normal budget is changed for any reason, there is an effect on bankruptcy notification: it delays bankruptcy handing by two windows to prevent a false bankruptcy detection if a partition's budget suddenly changes, for example, from 90% to 1%.
|
Canceling the budget on bankruptcy changes the partition's critical budget, causing further bankruptcy detections to be suppressed for two window sizes. |
In order to cause the entire system to stabilize after such an event, the thread scheduler gives all partitions a two-window grace period against declaring bankruptcy when one partition has its budget canceled.
Priorities and thread scheduler policies are relative to one adaptive partition only; priority order is respected within a partition, but not between partitions if the thread scheduler needs to balance budgets.
You can use the thread scheduler with the existing FIFO, round robin, and sporadic scheduling policies. The scheduler, however, may:
Or:
This occurs when the thread's partition runs out of budget and some other partition has budget, i.e. the thread scheduler doesn't wait for the end of a thread's timeslice to determine whether to run a thread from a different partition. The scheduler takes that decision every clock tick (where a tick is 1 millisecond on most machines). There are 4 clock ticks per timeslice.
Round robin threads being billed for critical time aren't timesliced with threads of equal priority.
Be careful not to misuse the FIFO scheduling policy. There's a technique for obtaining mutual exclusion between a set of threads reading and writing shared data without using a mutex: you can make all threads vying for the same shared data run at the same priority.
Since only one thread can run at a time (at least, on a uniprocessor system), and with FIFO scheduling, one thread never interrupts another; each has a monopoly on the shared data while it runs. This is not ideal because any accidental change to the scheduler policy or priority will likely cause one thread to interrupt the other in the middle of its critical section. So it may lead to a code breakdown. If you accidentally put the threads using this technique into different partitions (or let them receive messages from different partitions), their critical sections will be broken.
If your application's threads use their priorities to control the order in which they run, you should always place the threads in the same partition, and you shouldn't send messages to them from other partitions.
Pairs of threads written to depend on executing in a particular order based on their priorities should always be placed in the same partition, and you should not send them messages from other partitions.
In order to solve this problem, you must use mutexes, barriers, or pulses to control thread order. This will also prevent problems if you run your application on a multicore system. As a workaround, you can specify the _NTO_CHF_FIXED_PRIORITY flag to ChannelCreate(), which prevents the receiving thread from running in the sending thread's partition.
In general, for mutual exclusion, you should ensure that your applications don't depend on FIFO scheduling, or on the length of the timeslice.
On a multicore system, you can use scheduler partitions and symmetric multiprocessing (SMP) to reap the rewards of both. For more information, see the Multicore Processing User's Guide.
Note the following facts:
It may seem unlikely to have only one thread per partition, since most systems have many threads. However, there is a way this situation will occur on a multi-threaded system.
The runmask controls which CPUs a thread is allowed to run on. With careful (or foolish) use of the runmask, it's possible to arrange things so that there are not enough threads that are permitted to run on a particular processor for the scheduler to meet its budgets.
If there are several threads that are ready to run, and they're permitted to run on each CPU, then the thread scheduler correctly guarantees each partition's minimum budget.
|
On a hyperthreaded machine, actual throughput of partitions may not match the percentage of CPU time usage reported by the thread scheduler. This discrepancy occurs because on a hyperthreaded machine, throughput isn't always proportional to time, regardless of what kind of scheduler is being used. This scenario is most likely to occur when a partition doesn't contain enough ready threads to occupy all of the pseudo-processors on a hyperthreaded machine. |
Certain combinations of runmasks and partition budgets can have surprising results.
For example, we have a two-CPU SMP machine, with these partitions:
Now, suppose the system is idle. If you run a priority-10 thread that's locked to CPU 1 and is in an infinite loop in partition Pa, the thread scheduler interprets this to mean that you intend Pa to monopolize CPU 1. That's because CPU 1 can provide only 50% of the entire machine's processing time.
If you run another thread at priority 9, also locked to CPU 1, but in the System partition, the thread scheduler interprets that to mean you also want the System partition to monopolize CPU 1.
The thread scheduler has a dilemma: it can't satisfy the requirements of both partitions. What it actually does is allow partition Pa to monopolize CPU 1.
This is why: from an idle start, the thread scheduler observes that both partitions have available budget. When partitions have available budget, the thread scheduler schedules in realtime mode, which is strict priority scheduling. So partition Pa runs. However, because CPU 1 can never satisfy the budget of partition Pa; Pa never runs out of budget. Therefore, the thread scheduler remains in real time mode and the lower-priority System partition never runs.
For this example, the aps show command might display:
+---- CPU Time ----+-- Critical Time --
Partition name id | Budget | Used | Budget | Used
--------------------+------------------+-------------------
System 0 | 50% | 0.09% | 200ms | 0.000ms
Pa 1 | 50% | 49.93% | 0ms | 0.000ms
--------------------+------------------+-------------------
Total | 100% | 50.02% |
The System partition receives no CPU time even though it contains a thread that is ready to run.
Similar situations can occur when there are several partitions, each having a budget less than 50%, but whose budgets sum to 50% or more.
Avoiding infinite loops is a good way to avoid these situations. However, if you're running third-party software, you may not have control over the code.
To simplify the usage of runmasks with the thread scheduler, you may configure the scheduler to follow a more restrictive algorithm that prefers to meet budgets in some circumstances rather than schedule by priority.
To do so, set the flag SCHED_APS_SCHEDPOL_BMP_SAFETY with the SchedCtl() function that's declared in <sys/aps_sched.h> (see the Neutrino Library Reference), or use the aps modify -S bmp_safety command (see the entry for aps in the Utilities Reference).
The following table shows how time is divided in normal mode (with its risk of monopolization), and BMP-safety mode on a 2-CPU machine:
| Partition state | Normal | BMP-safety |
|---|---|---|
| Usage < budget / 2 | By priority | By priority |
| Usage < budget | By priority | By ratio of budgets |
| Usage > budget, but there's free time | By priority* | By ratio of budgets |
| Full load | By ratio of budgets | By ratio of budgets |
* When SCHED_APS_SCHEDPOL_FREETIME_BY_PRIORITY isn't set. For more information, see the SCHED_APS_SET_PARMS command in the entry for SchedCtl() in the Neutrino Library Reference.
In the example above, but with BMP-safety turned on, not only does the thread scheduler run both the System partition and partition Pa, it reasonably divides time on CPU 1 by the ratio of the partitions' budgets. The aps show command displays usage something like this:
+---- CPU Time ----+-- Critical Time --
Partition name id | Budget | Used | Budget | Used
--------------------+------------------+-------------------
System 0 | 50% | 25.03% | 200ms | 0.000ms
Pa 1 | 50% | 24.99% | 0ms | 0.000ms
--------------------+------------------+-------------------
Total | 100% | 50.02% |
The BMP-safety mode provides an easier-to-analyze scheduling mode at the cost of reducing the circumstances when the thread scheduler will schedule strictly by priority.
|
|
|
|