The Automatic Speech Recognition (ASR) subsystem provides speech-recognition services to other components. Interfaces hide the existence of third-party speech-recognition software so that vendors can be replaced without affecting the rest of the system.
The ASR subsystem uses application-specific conversation modules to provide speech/prompting handling throughout the system. Conversation modules are decoupled from the speech-recognition provider so that the same modules will work for multiple ASR vendors. This architecture allows customers to easily add/remove functionality in the system, including adapting for downloadable applications.
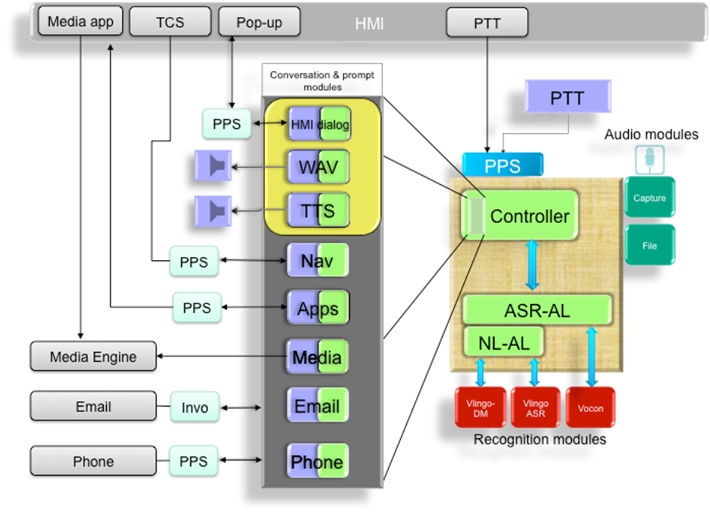
ASR services are kicked off via PPS when the user activates the Navigator's Push-to-Talk tab. The Capture audio module detects the spoken command, detects the beginning and end of sentences, and forwards the audio stream to the third-party recognition modules. The File audio module imports audio from a file (used primarily for testing).
- unprocessed JSON data
- normalized version of the JSON-encoded data
- determining the domain (e.g., navigation, phone)
- determining whether another recognition pass is required and whether the conversation is complete
- creating and/or modifying PPS objects as required
Apps such as Media and Navigation detect changes in PPS objects. For example, if the user presses the Push-to-Talk tab and says "Play Arcade Fire", the recognition modules parse the command. The Media conversation module then activates the Media Engine, causing tracks from the desired artist to play.
Prompt modules, used primarily by conversation modules, provide audio and/or visual prompt services. Specifically, they provide notification of nonspeech responses to onscreen notifications (e.g., selecting an option or canceling a command). Prompts come from prerecorded WAV files or from Text-To-Speech (TTS).
ASR and TTS integration
The ASR and TTS components, libraries, and configuration files manage ASR conversations, enable modules to communicate with each other, and allow control of audio capture characteristics, TTS synthesis settings, and attributes of the recognition module.
The following ASR modules are statically linked into io-asr-generic:
- /usr/sbin/io-asr-generic
- Manages ASR conversations.
- /lib/libasr-core.so.1
- An ASR library that enables inter-module communication.
- /etc/asr-car.cfg
- The recognition module's configuration file that enables you to configure:
- audio capture characteristics
- TTS synthesis settings
- recognition module attributes
- module ID mapping
- /opt/asr
- A directory containing resources that are required by io-asr-generic and its modules.
- Prompt modules
-
- Offboard_tts-prompt
- Provides a prompt service for playing text strings or files as audio. This is configurable in the vlingo/tts section of the asr-car.cfg configuration file.
- Wav_file-prompt
- Provides a prompt service for .wav file playback.
- Visual-interactive
- Provides on-screen interactive dialogs that augment speech interaction. (Currently not used.)
- Audio modules
-
- Capture
- Provides audio capture capability. You can configure this in the audio/capture section in the asr-car.cfg configuration file.
- Recognition module
-
- Vlingo
- Interprets the captured audio signals to deduce the words and sentences spoken.
- Conversation module
-
- Search
- Contains functionality that will be employed by other modules when the natural language-to-grammar mapping mechanism is complete.