You can measure the amount of time that a system is up and running, before it fails. You can also measure the amount of time that it takes you to repair a failed system.
The first number is called MTBF, and stands for Mean Time Between Failures. The second number is called MTTR, and stands for Mean Time To Repair.
Let's look at an example. If your system can, on average, run for 1000 hours (roughly 41 days), and then fails, and then if it takes you one hour to recover, then you have a system with an MTBF of 1000 hours, and an MTTR of one hour. These numbers are useful on their own, but they are also used to derive a ratio called the availability — what percentage of the time your system is available.
This is calculated by the formula:
 Figure 1. Calculating MTBF.
Figure 1. Calculating MTBF.If we do the math, with an MTBF of 1000 hours and an MTTR of one hour, your system will have an availability of:
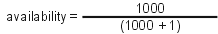 Figure 2. MTBF of 1000 hours, MTTR of one hour.
Figure 2. MTBF of 1000 hours, MTTR of one hour.or 0.999 (which is usually expressed as a percentage, so 99.9%). Since ideally the number of leading nines will be large, availability numbers are generally stated as the number of nines — 99.9% is often called "three nines."
Is three nines good enough? Can we achieve 100% reliability (also known as "continuous availability")?
Both answers are "no" — the first one is subjective, and depends on what level of service your customers expect, and the second is based on simple statistics — all software (and hardware) has bugs and reliability issues. No matter how much redundancy you put in, there is always a non-zero probability that you will have a catastrophic failure.