Until now, we've shown only message transfers happening from one buffer in the client's address space into another buffer in the server's address space. (And one buffer in the server's space into another buffer in the client's space during the reply.)
While this approach is good enough for most applications, it can lead to inefficiencies. Recall that our write() C library code took the buffer that you passed to it, and stuck a small header on the front of it. Using what we've learned so far, you'd expect that the C library would implement write() something like this (this isn't the real source):
ssize_t write (int fd, const void *buf, size_t nbytes)
{
char *newbuf;
io_write_t *wptr;
ssize_t nwritten;
newbuf = malloc (nbytes + sizeof (io_write_t));
// fill in the write_header at the beginning
wptr = (io_write_t *) newbuf;
wptr -> type = _IO_WRITE;
wptr -> nbytes = nbytes;
// store the actual data from the client
memcpy (newbuf + sizeof (io_write_t), buf, nbytes);
// send the message to the server
nwritten = MsgSend (fd,
newbuf,
nbytes + sizeof (io_write_t),
newbuf,
sizeof (io_write_t));
free (newbuf);
return (nwritten);
}
See what happened? A few bad things:
- The write() now has to be able to malloc() a buffer big enough for both the client data (which can be fairly big) and the header. The size of the header isn't the issue—in this case, it was 12 bytes.
- We had to copy the data twice: once via the memcpy(), and then again during the message transfer.
- We had to establish a pointer to the io_write_t type and point it to the beginning of the buffer, rather than access it natively (this is a minor annoyance).
Since the kernel is going to copy the data anyway, it would be nice if we could tell it that one part of the data (the header) is located at a certain address, and that the other part (the data itself) is located somewhere else, without the need for us to manually assemble the buffers and to copy the data.
As luck would have it, QNX Neutrino implements a mechanism that lets us do just that! The mechanism is something called an IOV, standing for “Input/Output Vector.”
Let's look at some code first, then we'll discuss what happens:
#include <sys/neutrino.h>
ssize_t write (int fd, const void *buf, size_t nbytes)
{
io_write_t whdr;
iov_t iov [2];
// set up the IOV to point to both parts:
SETIOV (iov + 0, &whdr, sizeof (whdr));
SETIOV (iov + 1, buf, nbytes);
// fill in the io_write_t at the beginning
whdr.type = _IO_WRITE;
whdr.nbytes = nbytes;
// send the message to the server
return (MsgSendv (coid, iov, 2, iov, 1));
}
First of all, notice there's no malloc() and no memcpy(). Next, notice the use of the iov_t type. This is a structure that contains an address and length pair, and we've allocated two of them (named iov).
The iov_t type definition is automatically included by <sys/neutrino.h>, and is defined as:
typedef struct iovec
{
void *iov_base;
size_t iov_len;
} iov_t;
Given this structure, we fill the address and length pairs with the write header (for the first part) and the data from the client (in the second part). There's a convenience macro called SETIOV() that does the assignments for us. It's formally defined as:
#include <sys/neutrino.h>
#define SETIOV(_iov, _addr, _len) \
((_iov)->iov_base = (void *)(_addr), \
(_iov)->iov_len = (_len))
SETIOV() accepts an iov_t, and the address and length data to be stuffed into the IOV.
Also notice that since we're creating an IOV to point to the header, we can allocate the header on the stack without using malloc(). This can be a blessing and a curse—it's a blessing when the header is quite small, because you avoid the headaches of dynamic memory allocation, but it can be a curse when the header is huge, because it can consume a fair chunk of stack space. Generally, the headers are quite small.
In any event, the important work is done by MsgSendv(), which takes almost the same arguments as the MsgSend() function that we used in the previous example:
#include <sys/neutrino.h>
long MsgSendv (int coid,
const iov_t *siov,
size_t sparts,
const iov_t *riov,
size_t rparts);
Let's examine the arguments:
- coid
- The connection ID that we're sending to, just as with MsgSend().
- sparts and rparts
- The number of send and receive parts specified by the iov_t parameters. In our example, we set sparts to 2 indicating that we're sending a 2-part message, and rparts to 1 indicating that we're receiving a 1-part reply.
- siov and riov
- The iov_t arrays indicate the address and length pairs that we wish to send. In the above example, we set up the 2 part siov to point to the header and the client data, and the 1 part riov to point to just the header.
This is how the kernel views the data:
 Figure 1. How the kernel sees a multipart message.
Figure 1. How the kernel sees a multipart message.The kernel just copies the data seamlessly from each part of the IOV in the client's space into the server's space (and back, for the reply). Effectively, the kernel is performing a gather-scatter operation.
A few points to keep in mind:
- The number of parts is “limited” to 524288; however, our example of 2 is typical.
- The kernel simply copies the data specified in one IOV from one address space into another.
- The source and the target IOVs don't have to be identical.
Why is the last point so important? To answer that, let's take a look at the big picture. On the client side, let's say we issued:
write (fd, buf, 12000);
which generated a two-part IOV of:
- header (12 bytes)
- data (12000 bytes)
On the server side, (let's say it's the filesystem, fs-qnx6), we have a number of 4 KB cache blocks, and we'd like to efficiently receive the message directly into the cache blocks. Ideally, we'd like to write some code like this:
// set up the IOV structure to receive into: SETIOV (iov + 0, &header, sizeof (header.io_write)); SETIOV (iov + 1, &cache_buffer [37], 4096); SETIOV (iov + 2, &cache_buffer [16], 4096); SETIOV (iov + 3, &cache_buffer [22], 4096); rcvid = MsgReceivev (chid, iov, 4, NULL);
This code does pretty much what you'd expect: it sets up a 4-part IOV structure, sets the first part of the structure to point to the header, and the next three parts to point to cache blocks 37, 16, and 22. (These numbers represent cache blocks that just happened to be available at that particular time.) Here's a graphical representation:
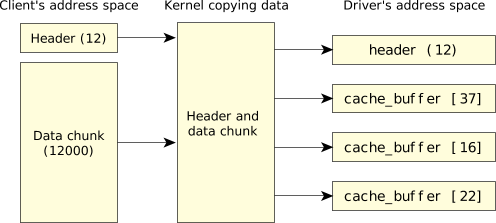 Figure 2. Converting contiguous data to separate buffers.
Figure 2. Converting contiguous data to separate buffers.Then the MsgReceivev() function is called, indicating that we'll receive a message from the specified channel (the chid parameter) and that we're supplying a 4-part IOV structure. This also shows the IOV structure itself.
(Apart from its IOV functionality, MsgReceivev() operates just like MsgReceive().)
Oops! We made the same mistake as we did before, when we introduced the MsgReceive() function. How do we know what kind of message we're receiving, and how much data is associated with it, until we actually receive the message?
We can solve this the same way as before:
rcvid = MsgReceive (chid, &header, sizeof (header), NULL);
switch (header.message_type) {
…
case _IO_WRITE:
number_of_bytes = header.io_write.nbytes;
// allocate / find cache buffer entries
// fill 3-part IOV with cache buffers
MsgReadv (rcvid, iov, 3, sizeof (header.io_write));
This does the initial MsgReceive() (note that we didn't use the IOV form for this—there's really no need to do that with a one-part message), figures out what kind of message it is, and then continues reading the data out of the client's address space (starting at offset sizeof (header.io_write)) into the cache buffers specified by the 3-part IOV.
Notice that we switched from using a 4-part IOV (in the first example) to a 3-part IOV. That's because in the first example, the first part of the 4-part IOV was the header, which we read directly using MsgReceive(), and the last three parts of the 4-part IOV are the same as the 3-part IOV—they specify where we'd like the data to go.
You can imagine how we'd perform the reply for a read request:
- Find the cache entries that correspond to the requested data.
- Fill an IOV structure with those entries.
- Use MsgWritev() (or MsgReplyv()) to transfer the data to the client.
Note that if the data doesn't start right at the beginning of a cache block (or other data structure), this isn't a problem. Simply offset the first IOV to point to where the data does start, and modify the size.