Probably the easiest function to understand is the io_read() function. As with all resource managers that implement directories, io_read() has both a file personality and a directory personality.
The decision as to which personality to use is made very early on, and then branches out into the two handlers:
int
cfs_io_read (resmgr_context_t *ctp, io_read_t *msg,
RESMGR_OCB_T *ocb)
{
int sts;
// use the helper function to decide if valid
if ((sts = iofunc_read_verify (ctp, msg, ocb, NULL)) != EOK) {
return (sts);
}
// decide if we should perform the "file" or "dir" read
if (S_ISDIR (ocb -> attr -> attr.mode)) {
return (ramdisk_io_read_dir (ctp, msg, ocb));
} else if (S_ISREG (ocb -> attr -> attr.mode)) {
return (ramdisk_io_read_file (ctp, msg, ocb));
} else {
return (EBADF);
}
}
The functionality above is standard, and you'll see similar code in every resource manager that has these two personalities. It would almost make sense for the resource manager framework to provide two distinct callouts, say an io_read_file() and an io_read_dir() callout.
Win some, lose some.
To read the directory entry, the code is almost the same as what we've seen in the Web Counter Resource Manager chapter.
I'll point out the differences:
int
ramdisk_io_read_dir (resmgr_context_t *ctp, io_read_t *msg,
iofunc_ocb_t *ocb)
{
int nbytes;
int nleft;
struct dirent *dp;
char *reply_msg;
char *fname;
int pool_flag;
// 1) allocate a buffer for the reply
if (msg -> i.nbytes <= 2048) {
reply_msg = mpool_calloc (mpool_readdir);
pool_flag = 1;
} else {
reply_msg = calloc (1, msg -> i.nbytes);
pool_flag = 0;
}
if (reply_msg == NULL) {
return (ENOMEM);
}
// assign output buffer
dp = (struct dirent *) reply_msg;
// we have "nleft" bytes left
nleft = msg -> i.nbytes;
while (ocb -> offset < ocb -> attr -> nels) {
// 2) short-form for name
fname = ocb -> attr -> type.dirblocks [ocb -> offset].name;
// 3) if directory entry is unused, skip it
if (!fname) {
ocb -> offset++;
continue;
}
// see how big the result is
nbytes = dirent_size (fname);
// do we have room for it?
if (nleft - nbytes >= 0) {
// fill the dirent, and advance the dirent pointer
dp = dirent_fill (dp, ocb -> offset + 1,
ocb -> offset, fname);
// move the OCB offset
ocb -> offset++;
// account for the bytes we just used up
nleft -= nbytes;
} else {
// don't have any more room, stop
break;
}
}
// if we returned any entries, then update the ATIME
if (nleft != msg -> i.nbytes) {
ocb -> attr -> attr.flags |= IOFUNC_ATTR_ATIME
| IOFUNC_ATTR_DIRTY_TIME;
}
// return info back to the client
MsgReply (ctp -> rcvid, (char *) dp - reply_msg, reply_msg,
(char *) dp - reply_msg);
// 4) release our buffer
if (pool_flag) {
mpool_free (mpool_readdir, reply_msg);
} else {
free (reply_msg);
}
// tell resource manager library we already did the reply
return (_RESMGR_NOREPLY);
}
There are four important differences in this implementation compared to the implementations we've already seen:
- Instead of calling malloc() or calloc() all the time, we've implemented our own memory-pool manager. This results in a speed and efficiency improvement because, when we're reading directories, the size of the allocations is always the same. If it's not, we revert to using calloc(). Note that we keep track of where the memory came from by using the pool_flag.
- In previous examples, we generated the name ourselves via sprintf(). In this case, we need to return the actual, arbitrary names that are stored in the RAM-disk directory entries. While dereferencing the name may look complicated, it's only looking through the OCB to find the attributes structure, and from there it's looking at the directory structure as indicated by the offset stored in the OCB.
- Oh yes, directory gaps. When an entry is deleted (i.e. rm spud.txt), the temptation is to move all the entries by one to cover the hole (or, at least to swap the last entry with the hole). This would let you eventually shrink the directory entry, because you know that all the elements at the end are blank. By examining nels versus nalloc in the extended attributes structure, you could make a decision to shrink the directory. But alas! That's not playing by the rules, because you cannot move directory entries around as you see fit, unless absolutely no one is using the directory entry. So, you must be able to support directory entries with holes. (As an exercise, you can add this “optimization cleanup” in the io_close_ocb() handler when you detect that the use-count for the directory has gone to zero.)
- Depending on where we allocated our buffer from, we need to return it to the correct place.
Apart from the above comments, it's a plain directory-based io_read() function.
To an extent, the basic skeleton for the file-based io_read() function, ramdisk_io_read_file(), is also common. What's not common is the way we get the data. Recall that in the web counter resource manager (and in the atoz resource manager in the previous book) we manufactured our data on the fly. Here, we must dutifully return the exact same data as what the client wrote in.
Therefore, what you'll see here is a bunch of code that deals with blocks and iov_ts. For reference, this is what an iov_t looks like:
typedef struct iovec {
void *iov_base;
uint32_t iov_len;
} iov_t;
(This is a slight simplification; see <sys/target_nto.h> for the whole story.) The iov_base member points to the data area, and the iov_len member indicates the size of that data area. We create arrays of iov_ts in the RAM-disk filesystem to hold our data. The iov_t is also the native data type used with the message-passing functions, like MsgReplyv(), so it's natural to use this data type, as you'll see soon.
Before we dive into the code, let's look at some of the cases that come up during access of the data blocks. The same cases (and others) come up during the write implementation as well.
We'll assume that the block size is 4096 bytes.
When reading blocks, there are several cases to consider:
- The total transfer will originate from within one block.
- The transfer will span two blocks, perhaps not entirely using either block fully.
- The transfer will span many blocks; the intermediate blocks will be fully used, but the end blocks may not be.
It's important to understand these cases, especially since they relate to boundary transfers of:
- 1 byte
- 2 bytes within the same block
- 2 bytes and spanning two blocks
- 4096 bytes within one complete block
- more than 4096 bytes within two blocks (the first block complete and the second incomplete)
- more than 4096 bytes within two blocks (the first block incomplete and the second incomplete)
- more than 4096 bytes within two blocks (the first block incomplete and the second complete)
- more than 4096 bytes within more than two blocks (like the three cases immediately above, but with one or more full intermediate blocks)
Believe me, I had fun drawing diagrams on the white board as I was coding this. :-)
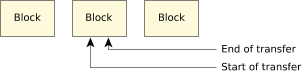 Figure 1. Total transfer originating entirely within one block.
Figure 1. Total transfer originating entirely within one block.In the above diagram, the transfer starts somewhere within one block and ends somewhere within the same block.
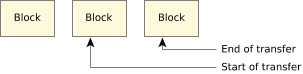 Figure 2. Total transfer spanning a block.
Figure 2. Total transfer spanning a block.In the above diagram, the transfer starts somewhere within one block, and ends somewhere within the next block. There are no full blocks transferred. This case is similar to the case above it, except that two blocks are involved rather than just one block.
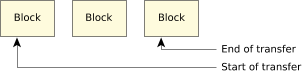 Figure 3. Total transfer spanning at least one full block.
Figure 3. Total transfer spanning at least one full block.In the above diagram, we see the case of having the first and last blocks incomplete, with one (or more) full intermediate blocks.
Keep these diagrams in mind when you look at the code.
int
ramdisk_io_read_file (resmgr_context_t *ctp, io_read_t *msg,
iofunc_ocb_t *ocb)
{
int nbytes;
int nleft;
int towrite;
iov_t *iovs;
int niovs;
int so; // start offset
int sb; // start block
int i;
int pool_flag;
// we don't do any xtypes here...
if ((msg -> i.xtype & _IO_XTYPE_MASK) != _IO_XTYPE_NONE) {
return (ENOSYS);
}
// figure out how many bytes are left
nleft = ocb -> attr -> attr.nbytes - ocb -> offset;
// and how many we can return to the client
nbytes = min (nleft, msg -> i.nbytes);
if (nbytes) {
// 1) calculate the number of IOVs that we'll need
niovs = nbytes / BLOCKSIZE + 2;
if (niovs <= 8) {
iovs = mpool_malloc (mpool_iov8);
pool_flag = 1;
} else {
iovs = malloc (sizeof (iov_t) * niovs);
pool_flag = 0;
}
if (iovs == NULL) {
return (ENOMEM);
}
// 2) find the starting block and the offset
so = ocb -> offset & (BLOCKSIZE - 1);
sb = ocb -> offset / BLOCKSIZE;
towrite = BLOCKSIZE - so;
if (towrite > nbytes) {
towrite = nbytes;
}
// 3) set up the first block
SETIOV (&iovs [0], (char *)
(ocb -> attr -> type.fileblocks [sb].iov_base) + so, towrite);
// 4) account for the bytes we just consumed
nleft = nbytes - towrite;
// 5) setup any additional blocks
for (i = 1; nleft > 0; i++) {
if (nleft > BLOCKSIZE) {
SETIOV (&iovs [i],
ocb -> attr -> type.fileblocks [sb + i].iov_base,
BLOCKSIZE);
nleft -= BLOCKSIZE;
} else {
// 6) handle a shorter final block
SETIOV (&&iovs [i],
ocb -> attr -> type.fileblocks [sb + i].iov_base, nleft);
nleft = 0;
}
}
// 7) return it to the client
MsgReplyv (ctp -> rcvid, nbytes, iovs, i);
// update flags and offset
ocb -> attr -> attr.flags |= IOFUNC_ATTR_ATIME
| IOFUNC_ATTR_DIRTY_TIME;
ocb -> offset += nbytes;
if (pool_flag) {
mpool_free (mpool_iov8, iovs);
} else {
free (iovs);
}
} else {
// nothing to return, indicate End Of File
MsgReply (ctp -> rcvid, EOK, NULL, 0);
}
// already done the reply ourselves
return (_RESMGR_NOREPLY);
}
We won't discuss the standard resource manager stuff, but we'll focus on the unique functionality of this resource manager.
- We're going to be using IOVs for our data-transfer operations, so we need to allocate an array of them. The number we need is the number of bytes that we'll be transferring plus 2—we need an extra one in case the initial block is short, and another one in case the final block is short. Consider the case were we're transferring two bytes on a block boundary. The nbytes / BLOCKSIZE calculation yields zero, but we need one more block for the first byte and one more block for the second byte. Again, we allocate the IOVs from a pool of IOVs because the maximum size of IOV allocation fits well within a pool environment. We have a malloc() fallback in case the size isn't within the capabilities of the pool.
- Since we could be at an arbitrary offset within the file when we're asked for bytes, we need to calculate where the first block is, and where in that first block our offset for transfers should be.
- The first block is special, because it may be shorter than the block size.
- We need to account for the bytes we just consumed, so that we can figure out how many remaining blocks we can transfer.
- All intermediate blocks (i.e. not the first and not the last) will be BLOCKSIZE bytes in length.
- The last block may or may not be BLOCKSIZE bytes in length, because it may be shorter.
- Notice how the IOVs are used with the MsgReplyv() to return the data from the client.
The main trick was to make sure that there were no boundary or off-by-one conditions in the logic that determines which block to start at, how many bytes to transfer, and how to handle the final block. Once that was worked out, it was smooth sailing as far as implementation.
You could optimize this further by returning the IOVs directly from the extended attributes structure's fileblocks member, but beware of the first and last block—you might need to modify the values stored in the fileblocks member's IOVs (the address and length of the first block, and the length of the last block), do your MsgReplyv(), and then restore the values. A little messy perhaps, but a tad more efficient.