We'll start with the door-lock actuators, because they're the simplest to deal with. The only thing we want this driver to do is to let a door be opened, or prevent one from being opened—that's it! This dictates the commands that the driver will take—we need to tell the driver which door lock it should manipulate, and its new state (locked or unlocked). For the initial software prototype, those are the only commands that I'd provide. Later, to offload processing and give us the ability to support new hardware, we might consider adding more commands.
Suppose you have different types of door-lock actuators—there are at least two types we should consider. One is a door release mechanism—when active, the door can be opened, and when inactive, the door cannot be opened. The second is a motor-driven door mechanism—when active, the motor starts and causes the door to swing open; when inactive, the motor releases the door allowing it to swing closed. These might look like two different drivers, with two different interfaces. However, they can be handled by the same interface (but not the same driver).
All we really want to do is let someone go through the door. Naturally, this means that we'd like to have some kind of timer associated with the opening of the door. When we've granted access, we'll allow the door to remain unlocked for, say, 20 seconds. After that point, we lock the door. For certain kinds of doors, we might wish to change the time, longer or shorter, as required.
A key question that arises is, "Where do we put this timer?" There are several possible places where it can go:
- the door lock driver itself,
- a separate timing manager driver that then talks to the door lock driver, or
- the control program itself.
This comes back to design decoupling (and is related to scalability).
If we put the timing functionality into the control program, we're adding to its workload. Not only does the control program have to handle its normal duties (database verification, operator displays, etc.), it now also has to manage timers.
For a small, simple system, this probably won't make much of a difference. But once we start to scale our design into a campus-wide security system, we'll be incurring additional processing in one central location. Whenever you see the phrase "one central location" you should immediately be looking for scalability problems. There are a number of significant problems with putting the functionality into the control program:
- Scalability
- The control program must maintain a timer for each door; the more doors, the more timers.
- Security
- If the communications system fails after the control program has opened the door, you're left with an unlocked door.
- Upgradability
- If a new type of door requires different timing parameters (for example, instead of lock and unlock commands, it might require multiple timing parameters to sequence various hardware), you now have to upgrade the control program.
The short answer here is that the control program really shouldn't have to manage the timers. This is a low-level detail that's ideally suited to being offloaded.
Let's consider the next point. Should we have a process that manages the timers, and then communicates with the door-lock actuators? Again, I'd answer no. The scalability and security aspects raised above don't apply in this case (we're assuming that this timer manager could be distributed across various CPUs, so it scales well, and since it's on the same CPU we can eliminate the communications failure component). The upgradability aspect still applies, however.
But there's also a new issue: functional clustering. What I mean by that is that the timing function is tied to the hardware. You might have dumb hardware where you have to do the timing yourself, or you might have smart hardware that has timers built into it.
In addition, you might have complicated hardware that requires multi-phase sequencing. By having a separate manager handle the timing, it has to be aware of the hardware details. The problem here is that you've split the hardware knowledge across two processes, without gaining any advantages. On a filesystem disk driver, for example, this might be similar to having one process being responsible for reading blocks from the disk while another one was responsible for writing. You're certainly not gaining anything, and in fact you're complicating the driver because now the two processes must coordinate with each other to get access to the hardware.
That said, there are cases where having a process that's between the control program and the individual door locks makes sense.
Suppose that we wanted to create a meta door-lock driver for some kind of complicated, sequenced door access (for example, in a high security area, where you want one door to open, and then completely close, before allowing access to another door). In this case, the meta driver would actually be responsible for cycling the individual door lock drivers. The nice thing about the way we've structured our devices is that as far as the control software is concerned, this meta driver looks just like a standard door-lock driver—the details are hidden by the interface.
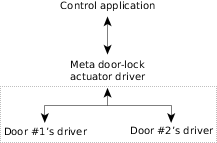 Figure 1. The meta door-lock driver presents the same interface as a regular door-lock driver.
Figure 1. The meta door-lock driver presents the same interface as a regular door-lock driver.