The ASR subsystem provides speech-recognition services to other components. Interfaces hide the existence of third-party speech-recognition software so that vendors can be replaced without affecting the rest of the system.
The ASR subsystem uses application-specific conversation modules to provide speech/prompting handling throughout the system. Conversation modules are decoupled from the speech-recognition provider so the same modules will work for multiple ASR vendors. This architecture allows customers to easily add or remove functionality, including adaptations for downloadable applications.
The platform uses various modules to manage human-machine interactions:
- Prompt modules
- Manage machine-to-human interactions, which can be either visual (onscreen) or audible.
- Audio modules
- Provide a hardware abstraction layer to hide the details of how audio is captured.
- Recognition modules
- Provide an abstraction layer to hide the details of the speech-to-text engine, allowing ASR services to be substituted transparently.
- Conversation modules
- Define how to handle human-to-machine speech commands.
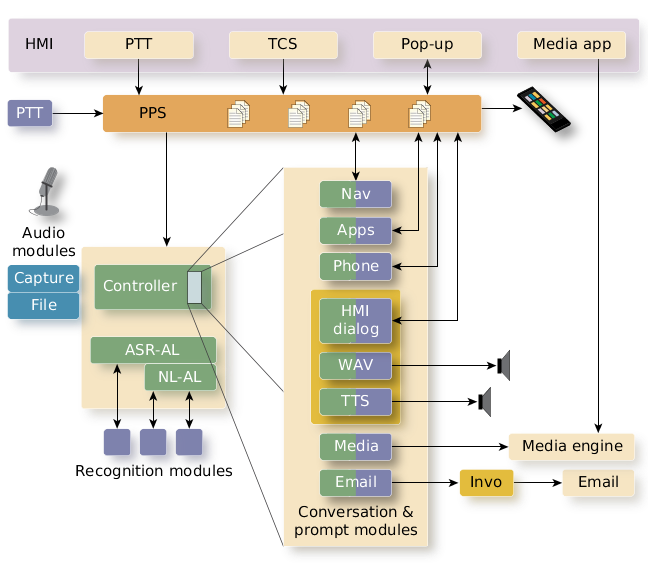 Figure 1. ASR subsystem architecture
Figure 1. ASR subsystem architectureThe ASR components are pluggable modules. With this architecture, you can reconfigure the ASR system to:
- add or remove conversation modules to modify the speech flow
- adjust the prompt module to change how the user receives responses
- change the recognition module to switch speech-to-text services
- specify different audio modules to capture audio from different sources
- "Automatic Speech Recognition (ASR)" in the User's Guide
- Automatic Speech Recognition Developer's Guide