![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
This chapter includes:
It's time to take a look at everything related to time in Neutrino. We'll see how and why you'd use timers and the theory behind them. Then we'll take a look at getting and setting the realtime clock.
 |
This chapter uses a ticksize of 10 ms, but QNX Neutrino now uses a 1 ms ticksize by default on most systems. This doesn't affect the substance of the issues being discussed. |
Let's look at a typical system, say a car. In this car, we have a bunch of programs, most of which are running at different priorities. Some of these need to respond to actual external events (like the brakes or the radio tuner), while others need to operate periodically (such as the diagnostics system).
So how does the diagnostics system “operate periodically?” You can imagine some process in the car's CPU that does something similar to the following:
// Diagnostics Process
int
main (void) // ignore arguments here
{
for (;;) {
perform_diagnostics ();
sleep (15);
}
// You'll never get here.
return (EXIT_SUCCESS);
}
Here we see that the diagnostics process runs forever. It performs one round of diagnostics and then goes to sleep for 15 seconds, wakes up, goes through the loop again, and again, …
Way back in the dim, dark days of single-tasking, where one CPU was dedicated to one user, these sorts of programs were implemented by having the sleep (15); code do a busy-wait loop. You'd calculate how fast your CPU was and then write your own sleep() function:
void
sleep (int nseconds)
{
long i;
while (nseconds--) {
for (i = 0; i < CALIBRATED_VALUE; i++) ;
}
}
In those days, since nothing else was running on the machine, this didn't present much of a problem, because no other process cared that you were hogging 100% of the CPU in the sleep() function.
|
Even today, we sometimes hog 100% of the CPU to do timing functions. Notably, the nanospin() function is used to obtain very fine-grained timing, but it does so at the expense of burning CPU at its priority. Use with caution! |
If you did have to perform some form of “multitasking,” it was usually done via an interrupt routine that would hang off the hardware timer or be performed within the “busy-wait” period, somewhat affecting the calibration of the timing. This usually wasn't a concern.
Luckily we've progressed far beyond that point. Recall from “Scheduling and the real world,” in the Processes and Threads chapter, what causes the kernel to reschedule threads:
In this chapter, we're concerned with the first two items on the list: the hardware interrupt and the kernel call.
When a thread calls sleep(), the C library contains code that eventually makes a kernel call. This call tells the kernel, “Put this thread on hold for a fixed amount of time.” The call removes the thread from the running queue and starts a timer.
Meanwhile, the kernel has been receiving regular hardware interrupts from the computer's clock hardware. Let's say, for argument's sake, that these hardware interrupts occur at exactly 10-millisecond intervals.
Let's restate: every time one of these interrupts is handled by the kernel's clock interrupt service routine (ISR), it means that 10 ms have gone by. The kernel keeps track of the time of day by incrementing its time-of-day variable by an amount corresponding to 10 ms every time the ISR runs.
So when the kernel implements a 15-second timer, all it's really doing is:
When multiple timers are outstanding, as would be the case if several threads all needed to be woken at different times, the kernel would simply queue the requests, sorting them by time order — the nearest one would be at the head of the queue, and so on. The variable that the ISR looks at is the one at the head of this queue.
That's the end of the timer five-cent tour.
Actually, there's a little bit more to it than first meets the eye.
So where does the clock interrupt come from? Here's a diagram that shows the hardware components (and some typical values for a PC) responsible for generating these clock interrupts:
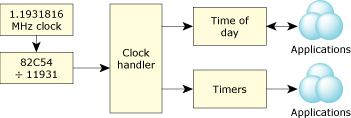
PC clock interrupt sources.
As you can see, there's a high-speed (MHz range) clock produced by the circuitry in the PC. This high-speed clock is then divided by a hardware counter (the 82C54 component in the diagram), which reduces the clock rate to the kHz or hundreds of Hz range (i.e., something that an ISR can actually handle). The clock ISR is a component of the kernel and interfaces directly with the data structures and code of the kernel itself. On non-x86 architectures (MIPS, PowerPC), a similar sequence of events occurs; some chips have clocks built into the processor.
Note that the high-speed clock is being divided by an integer divisor. This means the rate isn't going to be exactly 10 ms, because the high-speed clock's rate isn't an integer multiple of 10 ms. Therefore, the kernel's ISR in our example above might actually be interrupted after 9.9999296004 ms.
Big deal, right? Well, sure, it's fine for our 15-second counter. 15 seconds is 1500 timer ticks — doing the math shows that it's approximately 106 µs off the mark:
Unfortunately, continuing with the math, that amounts to 608 ms per day, or about 18.5 seconds per month, or almost 3.7 minutes per year!
You can imagine that with other divisors, the error could be greater or smaller, depending on the rounding error introduced. Luckily, the kernel knows about this and corrects for it.
The point of this story is that regardless of the nice round value shown, the real value is selected to be the next faster value.
Let's say that the timer tick is operating at just slightly faster than 10 ms. Can I reliably sleep for 3 milliseconds?
Nope.
Consider what happens in the kernel. You issue the C-library delay() call to go to sleep for 3 milliseconds. The kernel has to set the variable in the ISR to some value. If it sets it to the current time, this means the timer has already expired and that you should wake up immediately. If it sets it to one tick more than the current time, this means that you should wake up on the next tick (up to 10 milliseconds away).
The moral of this story is: “Don't expect timing resolution any better than the input timer tick rate.”
Under Neutrino, a program can adjust the value of the hardware divisor component in conjunction with the kernel (so that the kernel knows what rate the timer tick ISR is being called at). We'll look at this below in the “Getting and setting the realtime clock” section.
There's one more thing you have to worry about. Let's say the timing resolution is 10 ms and you want a 20 ms timeout.
Are you always going to get exactly 20 milliseconds worth of delay from the time that you issue the delay() call to the time that the function call returns?
Absolutely not.
There are two good reasons why. The first is fairly simple: when you block, you're taken off the running queue. This means that another thread at your priority may now be using the CPU. When your 20 milliseconds have expired, you'll be placed at the end of the READY queue for that priority so you'll be at the mercy of whatever thread happens to be running. This also applies to interrupt handlers running or higher-priority threads running — just because you are READY doesn't mean that you're consuming the CPU.
The second reason is a bit more subtle. The following diagram will help explain why:
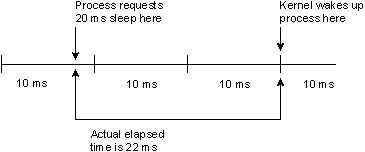
Clock jitter.
The problem is that your request is asynchronous to the clock source. You have no way to synchronize the hardware clock with your request. Therefore, you'll get from just over 20 milliseconds to just under 30 milliseconds worth of delay, depending on where in the hardware's clock period you started your request.
|
This is a key point. Clock jitter is a sad fact of life. The way to get around it is to increase the system's timing resolution so your timing is within tolerance. (We'll see how to do this in the “Getting and setting the realtime clock” section, below.) Keep in mind that jitter takes place only on the first tick — a 100-second delay with a 10-millisecond clock will delay for greater than 100 seconds and less than 100.01 seconds. |
The type of timer that I showed you above is a relative timer. The timeout period selected is relative to the current time. If you want the timer to delay your thread until January 20, 2005 at 12:04:33 EDT, you'd have to calculate the number of seconds from “now” until then, and set up a relative timer for that number of seconds. Because this is a fairly common function, Neutrino implements an absolute timer that will delay until the specified time (instead of for the specified time, like a relative timer).
What if you want to do something while you're waiting for that date to come around? Or, what if you want to do something and get a “kick” every 27 seconds? You certainly couldn't afford to be asleep!
As we discussed in the Processes and Threads chapter, you could simply start up another thread to do the work, and your thread could take the delay. However, since we're talking about timers, we'll look at another way of doing this.
You can do this with a periodic or one-shot timer, depending on your objectives. A periodic timer is one that goes off periodically, notifying the thread (over and over again) that a certain time interval has elapsed. A one-shot timer is one that goes off just once.
The implementation in the kernel is still based on the same principle as the delay timer that we used in our first example. The kernel takes the absolute time (if you specified it that way) and stores it. In the clock ISR, the stored time is compared against the time of day in the usual manner.
However, instead of your thread being removed from the running queue when you call the kernel, your thread continues to run. When the time of day reaches the stored time, the kernel notifies your thread that the designated time has been reached.
How do you receive a timeout notification? With the delay timer, you received notification by virtue of being made READY again.
With periodic and one-shot timers, you have a choice:
We've talked about pulses in the Message Passing chapter; signals are a standard UNIX-style mechanism, and we'll see the thread creation notification type shortly.
Let's take a quick look at how you fill in the struct sigevent structure.
Regardless of the notification scheme you choose, you'll need to fill in a struct sigevent structure:
struct sigevent {
int sigev_notify;
union {
int sigev_signo;
int sigev_coid;
int sigev_id;
void (*sigev_notify_function) (union sigval);
};
union sigval sigev_value;
union {
struct {
short sigev_code;
short sigev_priority;
};
pthread_attr_t *sigev_notify_attributes;
};
};
|
Note that the above definition uses anonymous unions and structures. Careful examination of the header file will show you how this trick is implemented on compilers that don't support these features. Basically, there's a #define that uses a named union and structure to make it look like it's an anonymous union. Check out <sys/siginfo.h> for details. |
The first field you have to fill in is the sigev_notify member. This determines the notification type you've selected:
Since we're going to be using the struct sigevent with timers, we're concerned only with the SIGEV_PULSE, SIGEV_SIGNAL* and SIGEV_THREAD values for sigev_notify; we'll see the other types as mentioned in the list above.
To send a pulse when the timer fires, set the sigev_notify field to SIGEV_PULSE and provide some extra information:
| Field | Value and meaning |
|---|---|
| sigev_coid | Send the pulse to the channel associated with this connection ID. |
| sigev_value | A 32-bit value that gets sent to the connection identified in the sigev_coid field. |
| sigev_code | An 8-bit value that gets sent to the connection identified in the sigev_coid field. |
| sigev_priority | The pulse's delivery priority. The value zero is not allowed (too many people were getting bitten by running at priority zero when they got a pulse — priority zero is what the idle task runs at, so effectively they were competing with Neutrino's IDLE process and not getting much CPU time :-)). |
Note that the sigev_coid could be a connection to any channel (usually, though not necessarily, the channel associated with the process that's initiating the event).
To send a signal, set the sigev_notify field to one of:
For SIGEV_SIGNAL*, the additional fields you'll have to fill are:
| Field | Value and meaning |
|---|---|
| sigev_signo | Signal number to send (from <signal.h>, e.g., SIGALRM). |
| sigev_code | An 8-bit code (if using SIGEV_SIGNAL_CODE or SIGEV_SIGNAL_THREAD). |
To create a thread whenever the timer fires, set the sigev_notify field to SIGEV_THREAD and fill these fields:
| Field | Value and meaning |
|---|---|
| sigev_notify_function | Address of void * function that accepts a void * to be called when the event triggers. |
| sigev_value | Value passed as the parameter to the sigev_notify_function() function. |
| sigev_notify_attributes | Thread attributes structure (see the Processes and Threads chapter, under “The thread attributes structure” for details). |
|
This notification type is a little scary! You could have a whole slew of threads created if the timer fires often enough and, if there are higher priority threads waiting to run, this could chew up all available resources on the system! Use with caution! |
There are some convenience macros in <sys/siginfo.h> to make filling in the notification structures easier (see the entry for sigevent in the Neutrino Library Reference):
Suppose you're designing a server that spent most of its life RECEIVE blocked, waiting for a message. Wouldn't it be ideal to receive a special message, one that told you that the time you had been waiting for finally arrived?
This scenario is exactly where you should use pulses as the notification scheme. In the “Using timers” section below, I'll show you some sample code that can be used to get periodic pulse messages.
Suppose that, on the other hand, you're performing some kind of work, but don't want that work to go on forever. For example, you may be waiting for some function call to return, but you can't predict how long it takes.
In this case, using a signal as the notification scheme, with perhaps a signal handler, is a good choice (another choice we'll discuss later is to use kernel timeouts; see _NTO_CHF_UNBLOCK in the Message Passing chapter as well). In the “Using timers” section below, we'll see a sample that uses signals.
Alternatively, a signal with sigwait() is cheaper than creating a channel to receive a pulse on, if you're not going to be receiving messages in your application anyway.
Having looked at all this wonderful theory, let's turn our attention to some specific code samples to see what you can do with timers.
To work with a timer, you must:
Let's look at these in order.
The first step is to create the timer with timer_create():
#include <time.h>
#include <sys/siginfo.h>
int
timer_create (clockid_t clock_id,
struct sigevent *event,
timer_t *timerid);
The clock_id argument tells the timer_create() function which time base you're creating this timer for. This is a POSIX thing — POSIX says that on different platforms you can have multiple time bases, but that every platform must support at least the CLOCK_REALTIME time base. Under Neutrino, there are three time bases to choose from:
For now, we'll ignore CLOCK_SOFTTIME and CLOCK_MONOTONIC but we will come back to them in the “Other clock sources” section, below.
The second parameter is a pointer to a struct sigevent data structure. This data structure is used to inform the kernel about what kind of event the timer should deliver whenever it “fires.” We discussed how to fill in the struct sigevent above in the discussion of signals versus pulses versus thread creation.
So, you'd call timer_create() with CLOCK_REALTIME and a pointer to your struct sigevent data structure, and the kernel would create a timer object for you (which gets returned in the last argument). This timer object is just a small integer that acts as an index into the kernel's timer tables; think of it as a “handle.”
At this point, nothing else is going to happen. You've only just created the timer; you haven't triggered it yet.
Having created the timer, you now have to decide what kind of timer it is. This is done by a combination of arguments to timer_settime(), the function used to actually start the timer:
#include <time.h>
int
timer_settime (timer_t timerid,
int flags,
struct itimerspec *value,
struct itimerspec *oldvalue);
The timerid argument is the value that you got back from the timer_create() function call — you can create a bunch of timers, and then call timer_settime() on them individually to set and start them at your convenience.
The flags argument is where you specify absolute versus relative.
If you pass the constant TIMER_ABSTIME, then it's absolute, pretty much as you'd expect. You then pass the actual date and time when you want the timer to go off.
If you pass a zero, then the timer is considered relative to the current time.
Let's look at how you specify the times. Here are key portions of two data structures (in <time.h>):
struct timespec {
long tv_sec,
tv_nsec;
};
struct itimerspec {
struct timespec it_value,
it_interval;
};
There are two members in struct itimerspec:
The it_value specifies either how long from now the timer should go off (in the case of a relative timer), or when the timer should go off (in the case of an absolute timer). Once the timer fires, the it_interval value specifies a relative value to reload the timer with so that it can trigger again. Note that specifying a value of zero for the it_interval makes it into a one-shot timer. You might expect that to create a “pure” periodic timer, you'd just set the it_interval to the reload value, and set it_value to zero. Unfortunately, the last part of that statement is false — setting the it_value to zero disables the timer. If you want to create a pure periodic timer, set it_value equal to it_interval and create the timer as a relative timer. This will fire once (for the it_value delay) and then keep reloading with the it_interval delay.
Both the it_value and it_interval members are actually structures of type struct timespec, another POSIX thing. The structure lets you specify sub-second resolutions. The first member, tv_sec, is the number of seconds; the second member, tv_nsec, is the number of nanoseconds in the current second. (What this means is that you should never set tv_nsec past the value 1 billion — this would imply more than a one-second offset.)
Here are some examples:
it_value.tv_sec = 5; it_value.tv_nsec = 500000000; it_interval.tv_sec = 0; it_interval.tv_nsec = 0;
This creates a one-shot timer that goes off in 5.5 seconds. (We got the “.5” because of the 500,000,000 nanoseconds value.)
We're assuming that this is used as a relative timer, because if it weren't, then that time would have elapsed long ago (5.5 seconds past January 1, 1970, 00:00 GMT).
Here's another example:
it_value.tv_sec = 987654321; it_value.tv_nsec = 0; it_interval.tv_sec = 0; it_interval.tv_nsec = 0;
This creates a one-shot timer that goes off Thursday, April 19, 2001 at 00:25:21 EDT. (There are a bunch of functions that help you convert between the human-readable date and the “number of seconds since January 1, 1970, 00:00:00 GMT” representation. Take a look in the C library at time(), asctime(), ctime(), mktime(), strftime(), etc.)
For this example, we're assuming that it's an absolute timer, because of the huge number of seconds that we'd be waiting if it were relative (987654321 seconds is about 31.3 years).
Note that in both examples, I've said, “We're assuming that…” There's nothing in the code for timer_settime() that checks those assumptions and does the “right” thing! You have to specify whether the timer is absolute or relative yourself. The kernel will happily schedule something 31.3 years into the future.
One last example:
it_value.tv_sec = 1; it_value.tv_nsec = 0; it_interval.tv_sec = 0; it_interval.tv_nsec = 500000000;
Assuming it's relative, this timer will go off in one second, and then again every half second after that. There's absolutely no requirement that the reload values look anything like the one-shot values.
The first thing we should look at is a server that wants to get periodic messages. The most typical uses for this are:
Of course there are other, specialized uses for these things, such as network “keep alive” messages that need to be sent periodically, retry requests, etc.
In this scenario, a server is providing some kind of service to a client, and the client has the ability to specify a timeout. There are lots of places where this is used. For example, you may wish to tell a server, “Get me 15 second's worth of data,” or “Let me know when 10 seconds are up,” or “Wait for data to show up, but if it doesn't show up within 2 minutes, time out.”
These are all examples of server-maintained timeouts. The client sends a message to the server, and blocks. The server receives periodic messages from a timer (perhaps once per second, perhaps more or less often), and counts how many of those messages it's received. When the number of timeout messages exceeds the timeout specified by the client, the server replies to the client with some kind of timeout indication or perhaps with the data accumulated so far — it really depends on how the client/server relationship is structured.
Here's a complete example of a server that accepts one of two messages from clients and a timeout message from a pulse. The first client message type says, “Let me know if there's any data available, but don't block me for more than 5 seconds.” The second client message type says, “Here's some data.” The server should allow multiple clients to be blocked on it, waiting for data, and must therefore associate a timeout with the clients. This is where the pulse message comes in; it says, “One second has elapsed.”
In order to keep the code sample from being one overwhelming mass, I've included some text before each of the major sections. You can find the complete version of time1.c in the Sample Programs appendix.
The first section of code here sets up the various manifest constants that we'll be using, the data structures, and includes all the header files required. We'll present this without comment. :-)
/*
* time1.c
*
* Example of a server that receives periodic messages from
* a timer, and regular messages from a client.
*
* Illustrates using the timer functions with a pulse.
*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
#include <signal.h>
#include <errno.h>
#include <unistd.h>
#include <sys/siginfo.h>
#include <sys/neutrino.h>
// message send definitions
// messages
#define MT_WAIT_DATA 2 // message from client
#define MT_SEND_DATA 3 // message from client
// pulses
#define CODE_TIMER 1 // pulse from timer
// message reply definitions
#define MT_OK 0 // message to client
#define MT_TIMEDOUT 1 // message to client
// message structure
typedef struct
{
// contains both message to and from client
int messageType;
// optional data, depending upon message
int messageData;
} ClientMessageT;
typedef union
{
// a message can be either from a client, or a pulse
ClientMessageT msg;
struct _pulse pulse;
} MessageT;
// client table
#define MAX_CLIENT 16 // max # of simultaneous clients
struct
{
int in_use; // is this client entry in use?
int rcvid; // receive ID of client
int timeout; // timeout left for client
} clients [MAX_CLIENT]; // client table
int chid; // channel ID (global)
int debug = 1; // set debug value, 1=on, 0=off
char *progname = "time1.c";
// forward prototypes
static void setupPulseAndTimer (void);
static void gotAPulse (void);
static void gotAMessage (int rcvid, ClientMessageT *msg);
This next section of code is the mainline. It's responsible for:
Notice the check against the return value from MsgReceive() — a zero indicates it's a pulse (and we don't do any strong checking to ensure that it's our pulse), a non-zero indicates it's a message. The processing of the pulse or message is done by gotAPulse() and gotAMessage().
int
main (void) // ignore command-line arguments
{
int rcvid; // process ID of the sender
MessageT msg; // the message itself
if ((chid = ChannelCreate (0)) == -1) {
fprintf (stderr, "%s: couldn't create channel!\n",
progname);
perror (NULL);
exit (EXIT_FAILURE);
}
// set up the pulse and timer
setupPulseAndTimer ();
// receive messages
for (;;) {
rcvid = MsgReceive (chid, &msg, sizeof (msg), NULL);
// determine who the message came from
if (rcvid == 0) {
// production code should check "code" field...
gotAPulse ();
} else {
gotAMessage (rcvid, &msg.msg);
}
}
// you'll never get here
return (EXIT_SUCCESS);
}
In setupPulseAndTimer() you see the code where we define the type of timer and notification scheme. When we talked about the timer function calls in the text above, I said that the timer could deliver a signal, a pulse, or cause a thread to be created. That decision is made here (in setupPulseAndTimer()). Notice that we used the macro SIGEV_PULSE_INIT(). By using this macro, we're effectively assigning the value SIGEV_PULSE to the sigev_notify member. (Had we used one of the SIGEV_SIGNAL*_INIT() macros instead, it would have delivered the specified signal.) Notice that, for the pulse, we set the connection back to ourselves via the ConnectAttach() call, and give it a code that uniquely identifies it (we chose the manifest constant CODE_TIMER; something that we defined). The final parameter in the initialization of the event structure is the priority of the pulse; we chose SIGEV_PULSE_PRIO_INHERIT (the constant -1). This tells the kernel not to change the priority of the receiving thread when the pulse arrives.
Near the bottom of this function, we call timer_create() to create a timer object within the kernel, and then we fill it in with data saying that it should go off in one second (the it_value member) and that it should reload with one-second repeats (the it_interval member). Note that the timer is activated only when we call timer_settime(), not when we create it.
|
The SIGEV_PULSE notification scheme is a Neutrino extension — POSIX has no concept of pulses. |
/*
* setupPulseAndTimer
*
* This routine is responsible for setting up a pulse so it
* sends a message with code MT_TIMER. It then sets up a
* periodic timer that fires once per second.
*/
void
setupPulseAndTimer (void)
{
timer_t timerid; // timer ID for timer
struct sigevent event; // event to deliver
struct itimerspec timer; // the timer data structure
int coid; // connection back to ourselves
// create a connection back to ourselves
coid = ConnectAttach (0, 0, chid, 0, 0);
if (coid == -1) {
fprintf (stderr, "%s: couldn't ConnectAttach to self!\n",
progname);
perror (NULL);
exit (EXIT_FAILURE);
}
// set up the kind of event that we want to deliver -- a pulse
SIGEV_PULSE_INIT (&event, coid,
SIGEV_PULSE_PRIO_INHERIT, CODE_TIMER, 0);
// create the timer, binding it to the event
if (timer_create (CLOCK_REALTIME, &event, &timerid) == -1) {
fprintf (stderr, "%s: couldn't create a timer, errno %d\n",
progname, errno);
perror (NULL);
exit (EXIT_FAILURE);
}
// setup the timer (1s delay, 1s reload)
timer.it_value.tv_sec = 1;
timer.it_value.tv_nsec = 0;
timer.it_interval.tv_sec = 1;
timer.it_interval.tv_nsec = 0;
// and start it!
timer_settime (timerid, 0, &timer, NULL);
}
In gotAPulse(), you can see how we've implemented the server's ability to timeout a client. We walk down the list of clients, and since we know that the pulse is being triggered once per second, we simply decrement the number of seconds that the client has left before a timeout. If this value reaches zero, we reply back to that client with a message saying, “Sorry, timed out” (the MT_TIMEDOUT message type). You'll notice that we prepare this message ahead of time (outside the for loop), and then send it as needed. This is just a style/usage issue — if you expect to be doing a lot of replies, then it might make sense to incur the setup overhead once. If you don't expect to do a lot of replies, then it might make more sense to set it up as needed.
If the timeout value hasn't yet reached zero, we don't do anything about it — the client is still blocked, waiting for a message to show up.
/*
* gotAPulse
*
* This routine is responsible for handling the fact that a
* timeout has occurred. It runs through the list of clients
* to see which client has timed out, and replies to it with
* a timed-out response.
*/
void
gotAPulse (void)
{
ClientMessageT msg;
int i;
if (debug) {
time_t now;
time (&now);
printf ("Got a Pulse at %s", ctime (&now));
}
// prepare a response message
msg.messageType = MT_TIMEDOUT;
// walk down list of clients
for (i = 0; i < MAX_CLIENT; i++) {
// is this entry in use?
if (clients [i].in_use) {
// is it about to time out?
if (--clients [i].timeout == 0) {
// send a reply
MsgReply (clients [i].rcvid, EOK, &msg,
sizeof (msg));
// entry no longer used
clients [i].in_use = 0;
}
}
}
}
In gotAMessage(), you see the other half of the functionality, where we add a client to the list of clients waiting for data (if it's a MT_WAIT_DATA message), or we match up a client with the message that just arrived (if it's a MT_SEND_DATA message). Note that for simplicity we didn't add a queue of clients that are waiting to send data, but for which no receiver is yet available — that's a queue management issue left as an exercise for the reader!
/*
* gotAMessage
*
* This routine is called whenever a message arrives. We
* look at the type of message (either a "wait for data"
* message, or a "here's some data" message), and act
* accordingly. For simplicity, we'll assume that there is
* never any data waiting. See the text for more discussion
* about this.
*/
void
gotAMessage (int rcvid, ClientMessageT *msg)
{
int i;
// determine the kind of message that it is
switch (msg -> messageType) {
// client wants to wait for data
case MT_WAIT_DATA:
// see if we can find a blank spot in the client table
for (i = 0; i < MAX_CLIENT; i++) {
if (!clients [i].in_use) {
// found one -- mark as in use, save rcvid, set timeout
clients [i].in_use = 1;
clients [i].rcvid = rcvid;
clients [i].timeout = 5;
return;
}
}
fprintf (stderr, "Table full, message from rcvid %d ignored, "
"client blocked\n", rcvid);
break;
// client with data
case MT_SEND_DATA:
// see if we can find another client to reply to with
// this client's data
for (i = 0; i < MAX_CLIENT; i++) {
if (clients [i].in_use) {
// found one -- reuse the incoming message
// as an outgoing message
msg -> messageType = MT_OK;
// reply to BOTH CLIENTS!
MsgReply (clients [i].rcvid, EOK, msg,
sizeof (*msg));
MsgReply (rcvid, EOK, msg, sizeof (*msg));
clients [i].in_use = 0;
return;
}
}
fprintf (stderr, "Table empty, message from rcvid %d ignored, "
"client blocked\n", rcvid);
break;
}
}
Some general notes about the code:
This is intentional in the design. You could modify this to add MT_NO_WAITERS and MT_NO_SPACE messages, respectively, which can be returned whenever these errors were detected.
Note that the example above shows just one way of implementing timeouts for clients. Later in this chapter (in “Kernel timeouts”), we'll talk about kernel timeouts, which are another way of implementing almost the exact same thing, except that it's driven by the client, rather than a timer.
Here we have a slightly different use for the periodic timeout messages. The messages are purely for the internal use of the server and generally have nothing to do with the client at all.
For example, some hardware might require that the server poll it periodically, as might be the case with a network connection — the server should see if the connection is still “up,” regardless of any instructions from clients.
Another case could occur if the hardware has some kind of “inactivity shutdown” timer. For example, since keeping a piece of hardware powered up for long periods of time may waste power, if no one has used that hardware for, say, 10 seconds, the hardware could be powered down. Again, this has nothing to do with the client (except that a client request will cancel this inactivity powerdown) — it's just something that the server has to be able to provide for its hardware.
Code-wise, this would be very similar to the example above, except that instead of having a list of clients that are waiting, you'd have only one timeout variable. Whenever a timer event arrives, this variable would be decremented; if zero, it would cause the hardware to shut down (or whatever other activity you wish to perform at that point). If it's still greater than zero, nothing would happen.
The only “twist” in the design would be that whenever a message comes in from a client that uses the hardware, you'd have to reset that timeout variable back to its full value — having someone use that resource resets the “countdown.” Conversely, the hardware may take a certain “warm-up” time in order to recover from being powered down. In this case, once the hardware has been powered down, you would have to set a different timer once a request arrived from a client. The purpose of this timer would be to delay the client's request from going to the hardware until the hardware has been powered up again.
So far, we've seen just about all there is to see with timers, except for one small thing. We've been delivering messages (via a pulse), but you can also deliver POSIX signals. Let's see how this is done:
timer_create (CLOCK_REALTIME, NULL, &timerid);
This is the simplest way to create a timer that sends you a signal. This method raises SIGALRM when the timer fires. If we had actually supplied a struct sigevent, we could specify which signal we actually want to get:
struct sigevent event; SIGEV_SIGNAL_INIT (&event, SIGUSR1); timer_create (CLOCK_REALTIME, &event, &timerid);
This hits us with SIGUSR1 instead of SIGALRM.
You catch timer signals with normal signal handlers, there's nothing special about them.
If you'd like to create a new thread every time a timer fires, then you can do so with the struct sigevent and all the other timer stuff we just discussed:
struct sigevent event; SIGEV_THREAD_INIT (&event, maintenance_func, NULL);
You'll want to be particularly careful with this one, because if you specify too short an interval, you'll be flooded with new threads! This could eat up all your CPU and memory resources!
Apart from using timers, you can also get and set the current realtime clock, and adjust it gradually. The following functions can be used for these purposes:
| Function | Type? | Description |
|---|---|---|
| ClockAdjust() | Neutrino | Gradually adjust the time |
| ClockCycles() | Neutrino | High-resolution snapshot |
| clock_getres() | POSIX | Fetch the base timing resolution |
| clock_gettime() | POSIX | Get the current time of day |
| ClockPeriod() | Neutrino | Get or set the base timing resolution |
| clock_settime() | POSIX | Set the current time of day |
| ClockTime() | Neutrino | Get or set the current time of day |
The functions clock_gettime() and clock_settime() are the POSIX functions based on the kernel function ClockTime(). These functions can be used to get or set the current time of day. Unfortunately, setting this is a “hard” adjustment, meaning that whatever time you specify in the buffer is immediately taken as the current time. This can have startling consequences, especially when time appears to move “backwards” because the time was ahead of the “real” time. Generally, setting a clock using this method should be done only during power up or when the time is very much out of synchronization with the real time.
That said, to effect a gradual change in the current time, the function ClockAdjust() can be used:
int
ClockAdjust (clockid_t id,
const struct _clockadjust *new,
const struct _clockadjust *old);
The parameters are the clock source (always use CLOCK_REALTIME), and a new and old parameter. Both the new and old parameters are optional, and can be NULL. The old parameter simply returns the current adjustment. The operation of the clock adjustment is controlled through the new parameter, which is a pointer to a structure that contains two elements, tick_nsec_inc and tick_count. Basically, the operation of ClockAdjust() is very simple. Over the next tick_count clock ticks, the adjustment contained in tick_nsec_inc is added to the current system clock. This means that to move the time forward (to “catch up” with the real time), you'd specify a positive value for tick_nsec_inc. Note that you'd never move the time backwards! Instead, if your clock was too fast, you'd specify a small negative number to tick_nsec_inc, which would cause the current time to not advance as fast as it would. So effectively, you've slowed down the clock until it matches reality. A rule of thumb is that you shouldn't adjust the clock by more than 10% of the base timing resolution of your system (as indicated by the functions we'll talk about next, ClockPeriod() and friends).
As we've been saying throughout this chapter, the timing resolution of everything in the system is going to be no more accurate than the base timing resolution coming into the system. So the obvious question is, how do you set the base timing resolution? You can use the ClockPeriod() function for this:
int
ClockPeriod (clockid_t id,
const struct _clockperiod *new,
struct _clockperiod *old,
int reserved);
As with the ClockAdjust() function described above, the new and the old parameters are how you get and/or set the values of the base timing resolution. The new and old parameters are pointers to structures of struct _clockperiod, which contains two members, nsec and fract. Currently, the fract member must be set to zero (it's the number of femtoseconds; we probably won't use this kind of resolution for a little while yet!) The nsec member indicates how many nanoseconds elapse between ticks of the base timing clock. The default is 10 milliseconds (1 millisecond on machines with CPU speeds of greater than 40 MHz), so the nsec member (if you use the “get” form of the call by specifying the old parameter) will show approximately 10 million nanoseconds. (As we discussed above, in “Clock interrupt sources,” it's not going to be exactly 10 millisecond.)
While you can certainly feel free to try to set the base timing resolution on your system to something ridiculously small, the kernel will step in and prevent you from doing that. Generally, you can set most systems in the 1 millisecond to hundreds of microseconds range.
There is one timebase that might be available on your processor that doesn't obey the rules of “base timing resolution” we just described. Some processors have a high-frequency (high-accuracy) counter built right into them, which Neutrino can let you have access to via the ClockCycles() call. For example, on a Pentium processor running at 200 MHz, this counter increments at 200 MHz as well, so it can give you timing samples right down to 5 nanoseconds. This is particularly useful if you want to figure out exactly how long a piece of code takes to execute (assuming of course, that you don't get preempted). You'd call ClockCycles() before your code and after your code, and then compute the delta. See the Neutrino Library Reference for more details.
|
Note that on an SMP system, you may run into a little problem. If your thread gets a ClockCycles() value from one CPU and then eventually runs on another CPU, you may get inconsistent results. This stems from the fact that the counters used by ClockCycles() are stored in the CPU chips themselves, and are not synchronized between CPUs. The solution to this is to use thread affinity to force the thread to run on a particular CPU. |
Now that we've seen the basics of timers, we'll look at a few advanced topics:
We've seen the clock source CLOCK_REALTIME, and mentioned that a POSIX conforming implementation may supply as many different clock sources as it feels like, provided that it at least provides CLOCK_REALTIME.
What is a clock source? Simply put, it's an abstract source of timing information. If you want to put it into real life concepts, your personal watch is a clock source; it measures how fast time goes by. Your watch will have a different level of accuracy than someone else's watch. You may forget to wind your watch, or get it new batteries, and time may seem to “freeze” for a while. Or, you may adjust your watch, and all of a sudden time seems to “jump.” These are all characteristics of a clock source.
Under Neutrino, CLOCK_REALTIME is based off of the “current time of day” clock that Neutrino provides. (In the examples below, we refer to this as “Neutrino Time.”) This means that if the system is running, and suddenly someone adjusts the time forward by 5 seconds, the change may or may not adversely affect your programs (depending on what you're doing). Let's look at a sleep (30); call:
| Real Time | Neutrino Time | Activity |
|---|---|---|
| 11:22:05 | 11:22:00 | sleep (30); |
| 11:22:15 | 11:22:15 | Clock gets adjusted to 11:22:15; it was 5 seconds too slow! |
| 11:22:35 | 11:22:35 | sleep (30); wakes up |
Beautiful! The thread did exactly what you expected: at 11:22:00 it went to sleep for thirty seconds, and at 11:22:35 (thirty elapsed seconds later) it woke up. Notice how the sleep() “appeared” to sleep for 35 seconds, instead of 30; in real, elapsed time, though, only 30 seconds went by because Neutrino's clock got adjusted ahead by five seconds (at 11:22:15).
The kernel knows that the sleep() call is a relative timer, so it takes care to ensure that the specified amount of “real time” elapses.
Now, what if, on the other hand, we had used an absolute timer, and at 11:22:00 in “Neutrino time” told the kernel to wake us up at 11:22:30?
| Real Time | Neutrino Time | Activity |
|---|---|---|
| 11:22:05 | 11:22:00 | Wake up at 11:22:30 |
| 11:22:15 | 11:22:15 | Clock gets adjusted as before |
| 11:22:30 | 11:22:30 | Wakes up |
This too is just like what you'd expect — you wanted to be woken up at 11:22:30, and (in spite of adjusting the time) you were.
However, there's a small twist here. If you take a look at the pthread_mutex_timedlock() function, for example, you'll notice that it takes an absolute timeout value, as opposed to a relative one:
int
pthread_mutex_timedlock (pthread_mutex_t *mutex,
const struct timespec *abs_timeout);
As you can imagine, there could be a problem if we try to implement a mutex that times out in 30 seconds. Let's go through the steps. At 11:22:00 (Neutrino time) we decide that we're going to try and lock a mutex, but we only want to block for a maximum of 30 seconds. Since the pthread_mutex_timedlock() function takes an absolute time, we perform a calculation: we add 30 seconds to the current time, giving us 11:22:30. If we follow the example above, we would wake up at 11:22:30, which means that we would have only locked the mutex for 25 seconds, instead of the full 30.
The POSIX people thought about this, and the solution they came up with was to make the pthread_mutex_timedlock() function be based on CLOCK_MONOTONIC instead of CLOCK_REALTIME. This is built in to the pthread_mutex_timedlock() function and isn't something that you can change.
They way CLOCK_MONOTONIC works is that its timebase is never adjusted. The impact of that is that regardless of what time it is in the real world, if you base a timer in CLOCK_MONOTONIC and add 30 seconds to it (and then do whatever adjustments you want to the time), the timer will expire in 30 elapsed seconds.
The clock source CLOCK_MONOTONIC has the following characteristics:
|
The important thing about the clock starting at zero is that this is a different “epoch” (or “base”) than CLOCK_REALTIME's epoch of Jan 1 1970, 00:00:00 GMT. So, even though both clocks run at the same rate, their values are not interchangeable. |
If we wanted to sort our clock sources by “hardness” we'd have the following ordering. You can think of CLOCK_MONOTONIC as being a freight train — it doesn't stop for anyone. Next on the list is CLOCK_REALTIME, because it can be pushed around a bit (as we saw with the time adjustment). Finally, we have CLOCK_SOFTTIME, which we can push around a lot.
The main use of CLOCK_SOFTTIME is for things that are “soft” — things that aren't going to cause a critical failure if they don't get done. CLOCK_SOFTTIME is “active” only when the CPU is running. (Yes, this does sound obvious :-) but wait!) When the CPU is powered down due to Power Management detecting that nothing is going to happen for a little while, CLOCK_SOFTTIME gets powered down as well!
Here's a timing chart showing the three clock sources:
| Real Time | Neutrino Time | Activity |
|---|---|---|
| 11:22:05 | 11:22:00 | Wake up at “now” + 00:00:30 (see below) |
| 11:22:15 | 11:22:15 | Clock gets adjusted as before |
| 11:22:20 | 11:22:20 | Power management turns off CPU |
| 11:22:30 | 11:22:30 | CLOCK_REALTIME wakes up |
| 11:22:35 | 11:22:35 | CLOCK_MONOTONIC wakes up |
| 11:45:07 | 11:45:07 | Power management turns on CPU, and CLOCK_SOFTTIME wakes up |
There are a few things to note here:
When CLOCK_SOFTTIME “over-sleeps,” it wakes up as soon as it's able — it doesn't stop “timing” while the CPU is powered down, it's just not in a position to wake up until after the CPU powers up. Other than that, CLOCK_SOFTTIME is just like CLOCK_REALTIME.
To specify one of the different clock source, use a POSIX timing function that accepts a clock ID. For example:
#include <time.h>
int
clock_nanosleep (clockid_t clock_id,
int flags,
const struct timespec *rqtp,
struct timespec *rmtp);
The clock_nanosleep() function accepts the clock_id parameter (telling it which clock source to use), a flag (which determines if the time is relative or absolute), a “requested sleep time” parameter (rqtp), as well as a pointer to an area where the function can fill in the amount of time remaining (in the rmtp parameter, which can be NULL if you don't care).
Neutrino lets you have a timeout associated with all kernel blocking states. We talked about the blocking states in the Processes and Threads chapter, in the section “Kernel states.” Most often, you'll want to use this with message passing; a client will send a message to a server, but the client won't want to wait “forever” for the server to respond. In that case, a kernel timeout is suitable. Kernel timeouts are also useful with the pthread_join() function. You might want to wait for a thread to finish, but you might not want to wait too long.
Here's the definition for the TimerTimeout() function call, which is the kernel function responsible for kernel timeouts:
#include <sys/neutrino.h>
int
TimerTimeout (clockid_t id,
int flags,
const struct sigevent *notify,
const uint64_t *ntime,
uint64_t *otime);
This says that TimerTimeout() returns an integer (a pass/fail indication, with -1 meaning the call failed and set errno, and zero indicating success). The time source (CLOCK_REALTIME, etc.) is passed in id, and the flags parameter gives the relevant kernel state or states. The notify should always be a notification event of type SIGEV_UNBLOCK, and the ntime is the relative time when the kernel call should timeout. The otime parameter indicates the previous value of the timeout — it's not used in the vast majority of cases (you can pass NULL).
|
It's important to note that the timeout is armed by TimerTimeout(), and triggered on entry into one of the kernel states specified by flags. It is cleared upon return from any kernel call. This means that you must re-arm the timeout before each and every kernel call that you want to be timeout-aware. You don't have to clear the timeout after the kernel call; this is done automagically. |
The simplest case to consider is a kernel timeout used with the pthread_join() call. Here's how you'd set it up:
/*
* part of tt1.c
*/
#include <sys/neutrino.h>
// 1 billion nanoseconds in a second
#define SEC_NSEC 1000000000LL
int
main (void) // ignore arguments
{
uint64_t timeout;
struct sigevent event;
int rval;
…
// set up the event -- this can be done once
// This or event.sigev_notify = SIGEV_UNBLOCK:
SIGEV_UNBLOCK_INIT (&event);
// set up for 10 second timeout
timeout = 10LL * SEC_NSEC;
TimerTimeout (CLOCK_REALTIME, _NTO_TIMEOUT_JOIN,
&event, &timeout, NULL);
rval = pthread_join (thread_id, NULL);
if (rval == ETIMEDOUT) {
printf ("Thread %d still running after 10 seconds!\n",
thread_id);
}
…
(You'll find the complete version of tt1.c in the Sample Programs appendix.)
We used the SIGEV_UNBLOCK_INIT() macro to initialize the event structure, but we could have set the sigev_notify member to SIGEV_UNBLOCK ourselves. Even more elegantly, we could pass NULL as the struct sigevent — TimerTimeout() understands this to mean that it should use a SIGEV_UNBLOCK.
If the thread (specified in thread_id) is still running after 10 seconds, then the kernel call will be timed out — pthread_join() will return with an errno of ETIMEDOUT.
You can use another shortcut — by specifying a NULL for the timeout value (ntime in the formal declaration above), this tells the kernel not to block in the given state. This can be used for polling. (While polling is generally discouraged, you could use it quite effectively in the case of the pthread_join() — you'd periodically poll to see if the thread you're interested in was finished yet. If not, you could perform other work.)
Here's a code sample showing a non-blocking pthread_join():
int
pthread_join_nb (int tid, void **rval)
{
TimerTimeout (CLOCK_REALTIME, _NTO_TIMEOUT_JOIN,
NULL, NULL, NULL);
return (pthread_join (tid, rval));
}
Things get a little trickier when you're using kernel timeouts with message passing. Recall from the Message Passing chapter (in the “Message passing and client/server” part) that the server may or may not be waiting for a message when the client sends it. This means that the client could be blocked in either the SEND-blocked state (if the server hasn't received the message yet), or the REPLY-blocked state (if the server has received the message, and hasn't yet replied). The implication here is that you should specify both blocking states for the flags argument to TimerTimeout(), because the client might get blocked in either state.
To specify multiple states, you simply OR them together:
TimerTimeout (… _NTO_TIMEOUT_SEND | _NTO_TIMEOUT_REPLY, …);
This causes the timeout to be active whenever the kernel enters either the SEND-blocked state or the REPLY-blocked state. There's nothing special about entering the SEND-blocked state and timing out — the server hasn't received the message yet, so the server isn't actively doing anything on behalf of the client. This means that if the kernel times out a SEND-blocked client, the server doesn't have to be informed. The client's MsgSend() function returns an ETIMEDOUT indication, and processing has completed for the timeout.
However, as was mentioned in the Message Passing chapter (under “_NTO_CHF_UNBLOCK”), if the server has already received the client's message, and the client wishes to unblock, there are two choices for the server. If the server has not specified _NTO_CHF_UNBLOCK on the channel it received the message on, then the client will be unblocked immediately, and the server won't receive any indication that an unblock has occurred. Most of the servers I've seen always have the _NTO_CHF_UNBLOCK flag enabled. In that case, the kernel delivers a pulse to the server, but the client remains blocked until the server replies! As mentioned in the above-referenced section of the Message Passing chapter, this is done so that the server has an indication that it should do something about the client's unblock request.
We've looked at Neutrino's time-based functions, including timers and how they can be used, as well as kernel timeouts. Relative timers provide some form of event “in a certain number of seconds,” while absolute timers provide this event “at a certain time.” Timers (and, generally speaking, the struct sigevent) can cause the delivery of a pulse, a signal, or a thread to start.
The kernel implements timers by storing the absolute time that represents the next “event” on a sorted queue, and comparing the current time (as derived by the timer tick interrupt service routine) against the head of the sorted queue. When the current time is greater than or equal to the first member of the queue, the queue is processed (for all matching entries) and the kernel dispatches events or threads (depending on the type of queue entry) and (possibly) reschedules.
To provide support for power-saving features, you should disable periodic timers when they're not needed — otherwise, the power-saving feature won't implement power saving, because it believes that there's something to “do” periodically. You could also use the CLOCK_SOFTTIME clock source, unless of course you actually wanted the timer to defeat the power saving feature.
Given the different types of clock sources, you have flexibility in determining the basis of your clocks and timer; from “real, elapsed” time through to time sources that are based on power management activities.
|
|
|
|