![[Previous]](prev.gif) |
![[Contents]](contents.gif) |
![[Index]](keyword_index.gif) |
![[Next]](next.gif) |
|
|
|
|
 |
This version of this document is no longer maintained. For the latest documentation, see http://www.qnx.com/developers/docs. |
In many computer systems, it's important to protect different applications or groups of applications from others. You don't want one application -- whether defective or malicious -- to corrupt another or prevent it from running.
To address this issue, some systems use virtual walls, called partitions, around a set of applications to ensure that each partition is given an engineered set of resources. The primary resource considered is CPU time, but can also include any shared resource such as memory and file space (disk or flash).
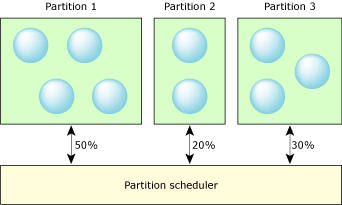
Static partitions guarantee that processes get the resources specified by the system designer.
Partitions provide:
By using multiple partitions, you can avoid having a single point of failure. For example, a runaway process can't tie up the entire system; processes in other partitions still get their allocated share of system resources.
Neutrino's process model already provides a lot more protection than some other operating systems do, including:
 |
The initial version of Adaptive Partitioning implements the budgeting of CPU time, via the adaptive partitioning scheduler. Future releases will address budgeting memory and other resources. |
Rigid partitions work best in fairly static systems with little or no dynamic deployment of software. In dynamic systems, static partitions can be inefficient. For example, the static division of execution time between partitions can waste CPU time and introduce delays:
To provide realtime performance with guarantees against overloading, QNX Neutrino introduces adaptive partitioning.
An adaptive partition is a set of threads that work on a common or related goal or activity. Like a static partition, an adaptive partition has a budget allocated to it that guarantees its minimum share of the CPU's resources. Unlike a static partition, an adaptive partition:
You can introduce adaptive partitioning without changing -- or even recompiling -- your application code, although you do have to rebuild your system's OS image.
Adaptive partitioning provides a number of benefits to the design, development, running, and debugging of your system, as described in the sections that follow.
Adaptive partitioning ensures that any free time available in the system (i.e. time in a partition's budget that the partition doesn't need) is made available to other partitions. This lets the system handle bursty processing demands that occur in normal system operation. With a cyclic scheduler, there's a "use it or lose it" approach where unused CPU time is spent running an idler thread in partitions that don't use their full budget.
Another important feature of adaptive partitioning is the concept of partition inheritance. This lets designers develop server processes that run with no (or minimal) budget. When the server performs requests from clients, the client partition is billed for the time. Without this feature, CPU budget would be allocated to a server regardless of how much or often it's used. The benefits of these features include:
Designing large-scale distributed systems is inherently complex. Typical systems have a large number of subsystems, processes, and threads that are developed in isolation from each other. The design is divided among groups with differing system performance goals, different schemes for determining priorities, and different approaches to runtime optimization.
This can be further compounded by product development in different geographic locations and time zones. Once all of these disparate subsystems are integrated into a common runtime environment, all parts of the system need to provide adequate response under all operating scenarios such as:
Given the parallel development paths, system issues invariably arise when integrating the product. Typically, once a system is running, unforeseen interactions that cause serious performance degradations are uncovered. When situations such as this arise, there are usually very few designers or architects who can diagnose and solve these problems at a system level. Solutions often take a lot of tweaking (frequently by trial and error) to get right. This extends system integration, impacting the time to market.
Problems of this nature can take a week or more to troubleshoot and several weeks to adjust priorities across the system, retest and refine. Product scalability is limited if these problems can't be solved effectively.
This is largely due to the fact that there's no effective way to "budget" CPU use across these groups. Thread priorities provide a way to ensure that critical tasks run, but don't provide guaranteed CPU time for important, noncritical tasks, which can be starved in normal operations. In addition, a common approach to establishing thread priorities is difficult to scale across a large development team.
Adaptive partitioning lets architects define high-level CPU budgets per subsystem, allowing development groups to implement their own priority schemes and optimizations within a given budget. This approach lets design groups develop subsystems independently and eases the integration effort. The net effect is to improve time-to-market and facilitate product scaling.
Many systems are vulnerable to Denial of Service (DOS) attacks. For example, a malicious user could bombard a system with requests that need to be processed by one process. When under attack, this process overloads the CPU and effectively starves the rest of the system.
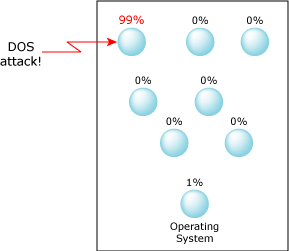
Without adaptive partitioning, a DOS attack on one process can starve other critical functions.
Some systems try to overcome this problem by implementing a monitor process that detects CPU utilization and invokes corrective actions when it deems that a process is using too much CPU. This approach has a number of drawbacks, including:
Adaptive partitioning can solve this problem by providing separate budgets to the system's various functions. This ensures that the system always has some CPU capacity for important tasks. Threads can change their own priorities, which can be a security hole, but you can configure the adaptive partitioning scheduler to prevent code running in a partition from changing its own budget.
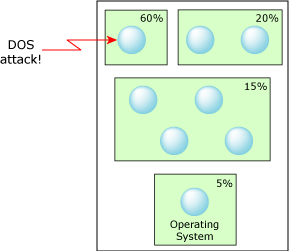
With adaptive partitioning, a DOS attack is contained.
Since adaptive partitioning can allocate any unused CPU time to partitions that need it, it doesn't unnecessarily cap control-plane activity when there's a legitimate need for increased processing.
Adaptive partitioning can even make debugging an embedded system easier--during development or deployment--by providing an "emergency door" into the system.
Simply create a partition that you can run diagnostic tools in; if you don't need to use the partition, the scheduler allocates its budget among the other partitions. This gives you access to the system without compromising its performance. For more information, see the Testing and Debugging chapter of the Adaptive Partitioning User's Guide.
The adaptive partitioning scheduler is an optional thread scheduler that lets you guarantee minimum percentages of the CPU's throughput to groups of threads, processes, or applications. The percentage of the CPU time allotted to a partition is called a budget.
The adaptive partitioning scheduler has been designed on top of the core QNX Neutrino architecture primarily to solve these problems in embedded systems design:
For more information, see the Adaptive Partitioning User's Guide.
|
|
|
|